
第五次课作业
作业
基础作业:
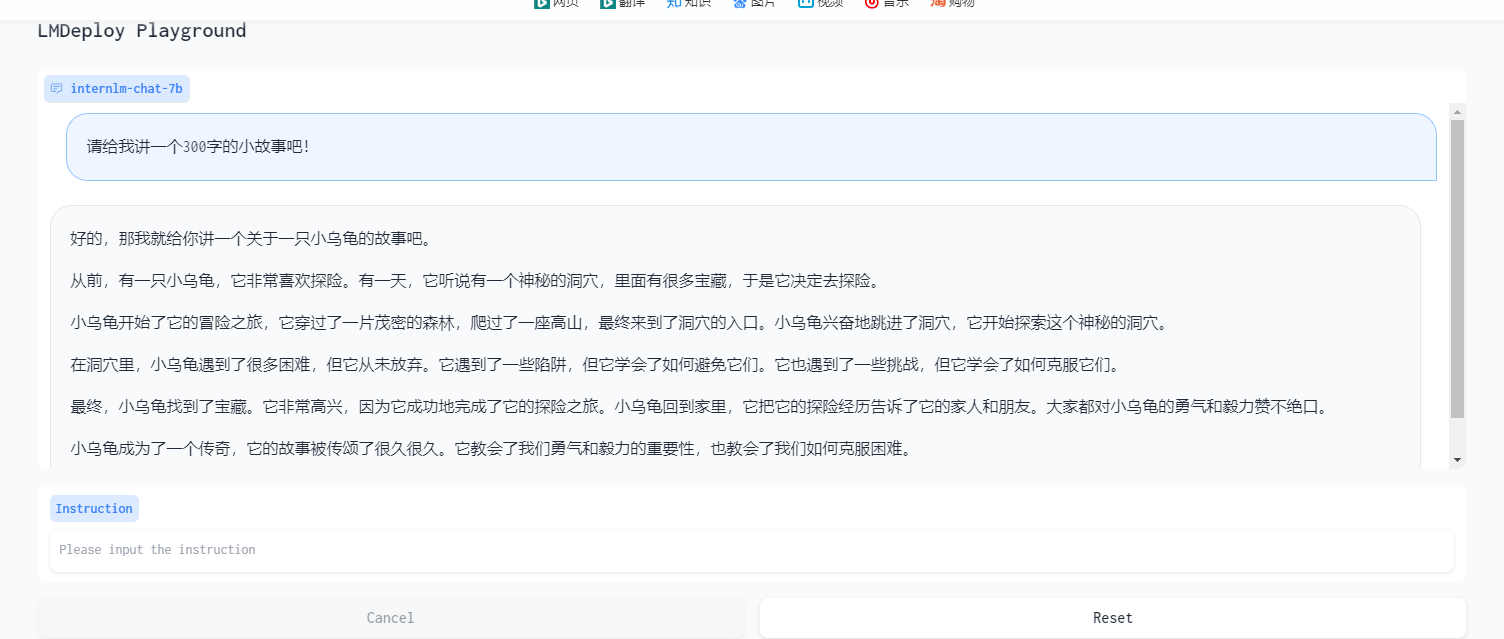
进阶作业(可选做)
- 将第四节课训练自我认知小助手模型使用 LMDeploy 量化部署到 OpenXLab 平台。
将quant_output上传到平台中
- 对internlm-chat-7b模型进行量化,并同时使用KV Cache量化,使用量化后的模型完成API服务的部署,分别对比模型量化前后和 KV Cache 量化前后的显存大小(将 bs设置为 1 和 max len 设置为512)。
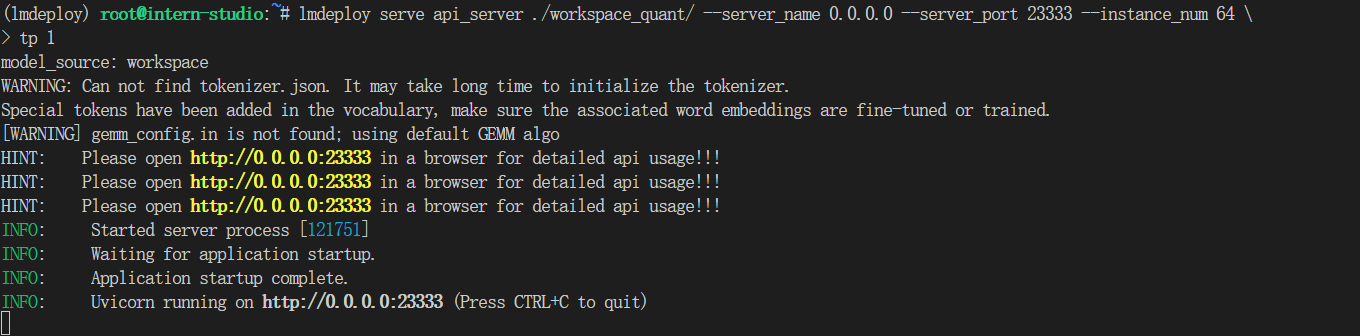

-
在自己的任务数据集上任取若干条进行Benchmark测试,测试方向包括:
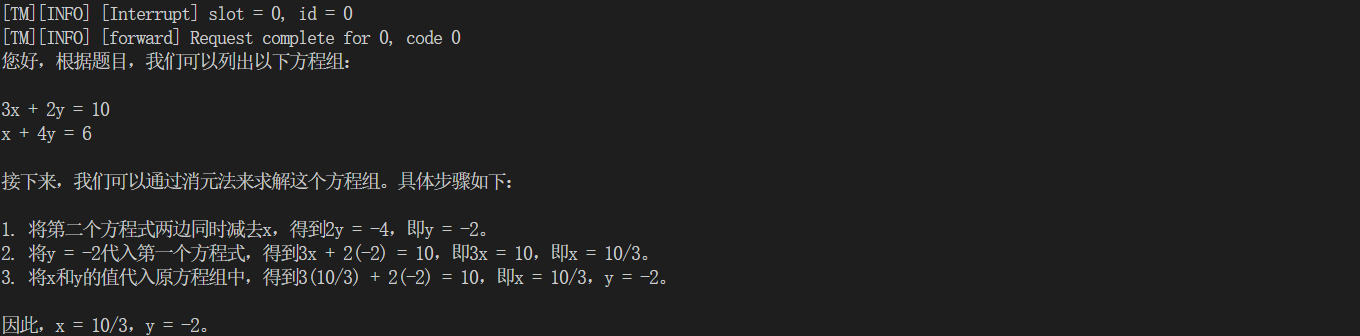
这里我都用一个问题:3x + 2y = 10, x + 4y = 6,求x,y
(1)TurboMind推理+Python代码集成
from lmdeploy import turbomind as tm # load model model_path = "/root/share/temp/model_repos/internlm-chat-7b/" tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b') generator = tm_model.create_instance() # process query query = "3x + 2y = 10, x + 4y = 6,求x,y" prompt = tm_model.model.get_prompt(query) input_ids = tm_model.tokenizer.encode(prompt) # inference for outputs in generator.stream_infer( session_id=0, input_ids=[input_ids]): res, tokens = outputs[0] response = tm_model.tokenizer.decode(res.tolist()) print(response)
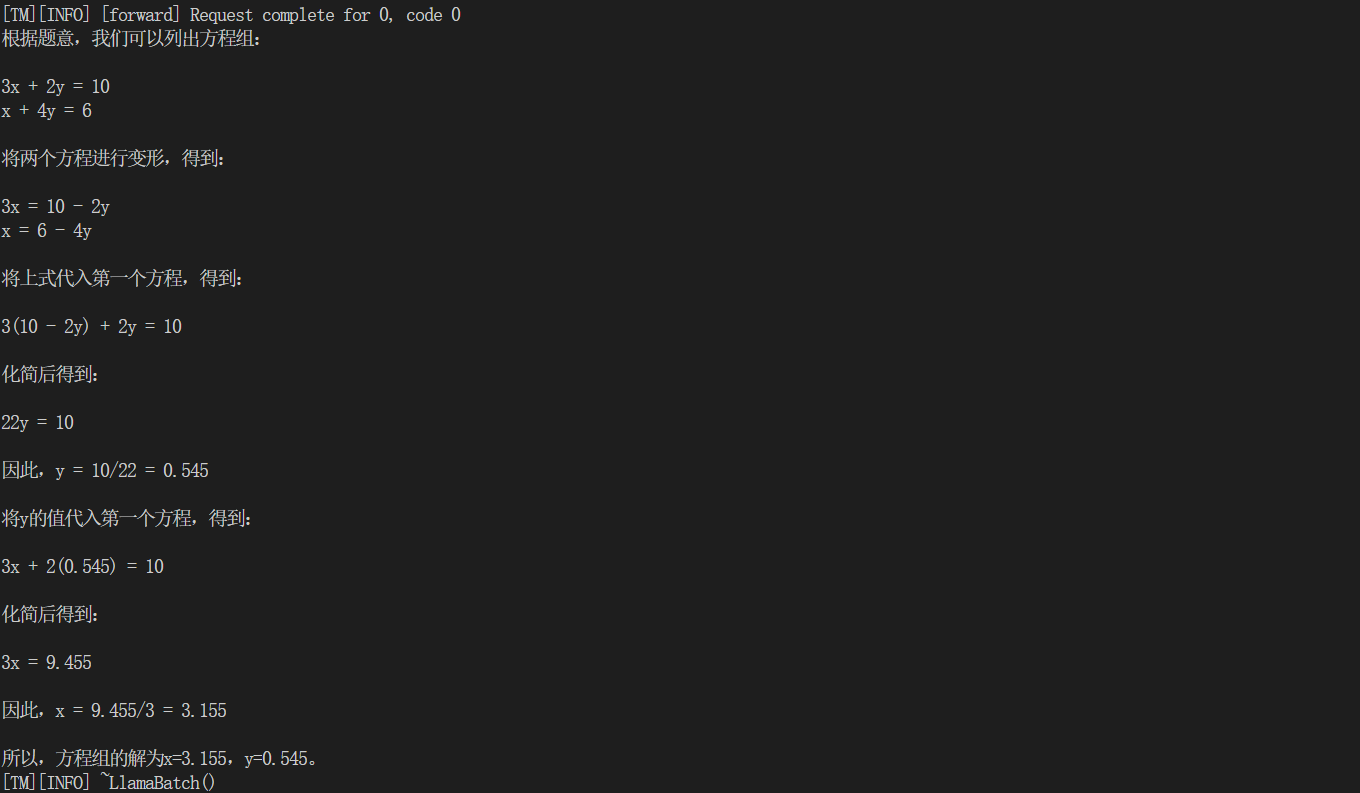
(2)在(1)的基础上采用W4A16量化
model_path = "/root/workspace_quant"
(3)在(1)的基础上开启KV Cache量化
model_path = "/root/workspace"
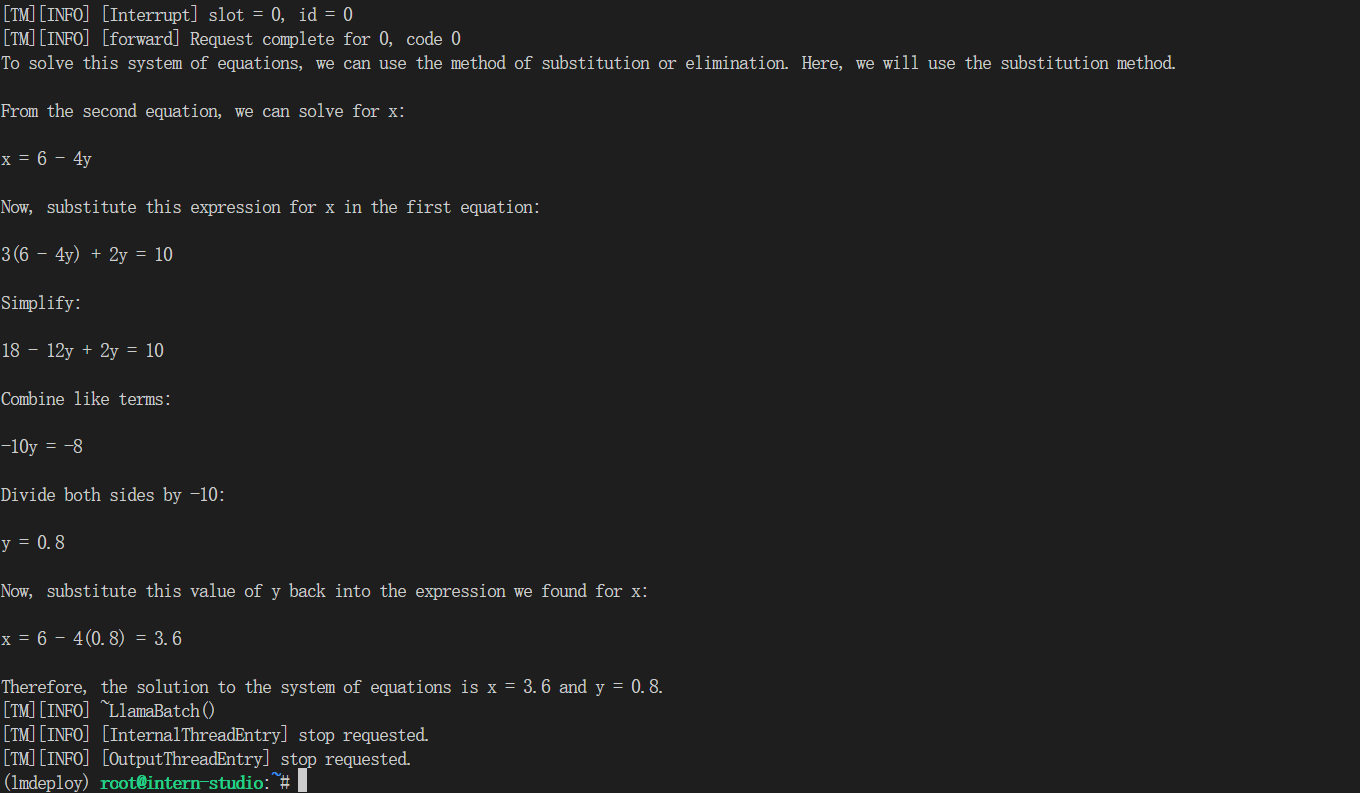
(4)在(2)的基础上开启KV Cache量化
# 和2的代码一样
# 但还是config.ini中修改一下quant_policy = 4,use_context_fmha = 0
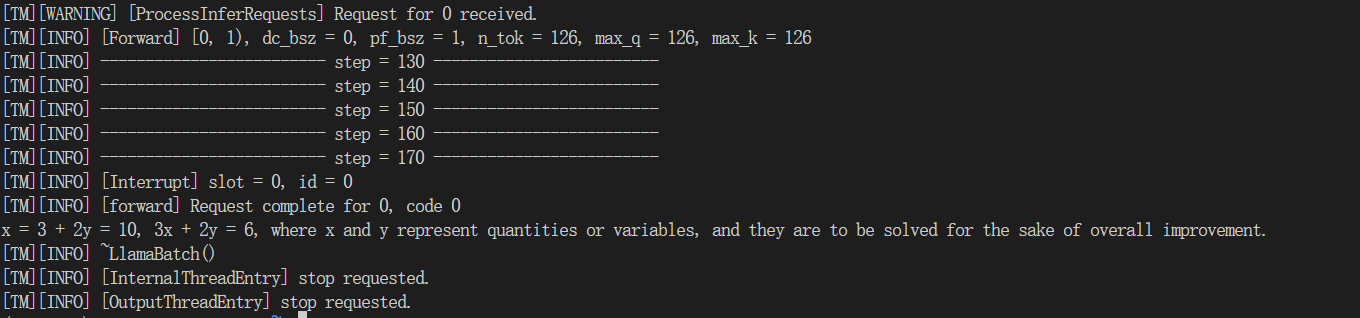
(5)使用Huggingface推理
model_path = "internlm/internlm-chat-7b"

拉不起来,555

 浙公网安备 33010602011771号
浙公网安备 33010602011771号