Java开发面试题整理(2019春招)
一、Java基础部分
1. HashMap和Hashtable各有什么特点,它们有什么区别?(必背题,超级重要)
- HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
2. HashMap的工作原理?
- HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
- 当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
- 1和2参考博客链接
- 这里还有许多相关问题的描述,都是比较重要的!建议将其背熟!
3. ArrayList和LinkList各自的特点和区别?
1、ArrayList和LinkedList可想从名字分析,它们一个是Array(动态数组)的数据结构,一个是Link(链表)的数据结构,此外,它们两个都是对List接口的实现。前者是数组队列,相当于动态数组;后者为双向链表结构,也可当作堆栈、队列、双端队列
2、当随机访问List时(get和set操作),ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
3、当对数据进行增加和删除的操作时(add和remove操作),LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。
4、从利用效率来看,ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
5、ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储结点信息以及结点指针信息。
4. RESTFul风格接口的特点?
- 此题是现在做应用开发常问的题目,RestFul风格在现在的应用开发还是比较常用的,所以还是比较重要,建议进行了解:以下是作者自认为不错的一篇关于RestFul架构风格的博客,推荐!博客·链接
5. 面向对象的七种设计原则
面向对象七大设计原则:
1、 开闭原则(OCP:Open Closed Principle)
核心:对扩展开放,对修改关闭。即在设计一个模块的时候,应当使这个模块可以在不被修改的前提下被扩展。
- 根据开闭原则,在设计一个软件系统模块(类,方法)的时候,应该可以在不修改原有的模块(修改关闭)的基础上,能扩展其功能(扩展开放)。
2、 里氏替换原则(LSP:Liskov Substitution Principle)
核心:在任何父类出现的地方都可以用他的子类来替代(子类应当可以替换父类并出现在父类能够出现的任何地方)
- 1.子类必须完全实现父类的方法。在类中调用其他类是务必要使用父类或接口,如果不能使用父类或接口,则说明类的设计已经违背了LSP原则。
- 2.子类可以有自己的个性。子类当然可以有自己的行为和外观了,也就是方法和属性
- 3.覆盖或实现父类的方法时输入参数可以被放大。即子类可以重载父类的方法,但输入参数应比父类方法中的大,这样在子类代替父类的时候,调用的仍然是父类的方法。即以子类中方法的前置条件必须与超类中被覆盖的方法的前置条件相同或者更宽松。
- 4.覆盖或实现父类的方法时输出结果可以被缩小。
3、 单一职责原则(SRP:Single responsibility principle)
核心:解耦和增强内聚性(高内聚,低耦合)
- 类被修改的几率很大,因此应该专注于单一的功能。如果你把多个功能放在同一个类中,功能之间就形成了关联,改变其中一个功能,有可能中止另一个功能,这时就需要新一轮的测试来避免可能出现的问题。
4、 接口隔离原则(ISP:Interface Segregation Principle)
核心思想:不应该强迫客户程序依赖他们不需要使用的方法。接口分离原则的意思就是:一个接口不需要提供太多的行为,一个接口应该只提供一种对外的功能,不应该把所有的操作都封装到一个接口当中.
- 分离接口的两种实现方法:
- 1.使用委托分离接口。(Separation through Delegation)
- 2.使用多重继承分离接口。(Separation through Multiple Inheritance)
5、 依赖倒置原则(DIP:Dependence Inversion Principle)
核心:要依赖于抽象,不要依赖于具体的实现
- 1.高层模块不应该依赖低层模块,两者都应该依赖其抽象(抽象类或接口)
- 2.抽象不应该依赖细节(具体实现)
- 3.细节(具体实现)应该依赖抽象。
三种实现方式: - 1.通过构造函数传递依赖对象
- 2.通过setter方法传递依赖对象
- 3.接口声明实现依赖对象
6、 迪米特原则(最少知识原则)(LOD:Law of Demeter)
核心思想:一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。(类间解耦,低耦合)意思就是降低各个对象之间的耦合,提高系统的可维护性;在模块之间只通过接口来通信,而不理会模块的内部工作原理,可以使各个模块的耦合成都降到最低,促进软件的复用
注:
- 1.在类的划分上,应该创建有弱耦合的类;
- 2.在类的结构设计上,每一个类都应当尽量降低成员的访问权限;
- 3.在类的设计上,只要有可能,一个类应当设计成不变;
- 4.在对其他类的引用上,一个对象对其它对象的引用应当降到最低;
- 5.尽量降低类的访问权限;
- 6.谨慎使用序列化功能;
- 7.不要暴露类成员,而应该提供相应的访问器(属性)
7、 组合/聚合复用原则(CRP:Composite Reuse Principle)
核心思想:尽量使用对象组合,而不是继承来达到复用的目的。该原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分:新的对象通过向这些对象的委派达到复用已有功能的目的。
复用的种类:
- 1.继承
- 2.合成聚合
注:在复用时应优先考虑使用合成聚合而不是继承
6. 谈谈堆和栈的区别!
a.堆栈空间分配
- 栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表
b.堆栈缓存方式
- 栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
- 堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
c.堆栈数据结构区别
- 堆(数据结构):堆可以被看成是一棵树,如:堆排序。
- 栈(数据结构):一种先进后出的数据结构。
7. 谈谈你所了解的设计模式,并简单描述其特点和用法,或简单写一个某某设计模式!
1. 单例设计模式
2. 工厂设计模式
3. 代理模式
4. 观察者设计模式
5. 适配器模式
6. 策略模式
7. 门面模式
8. 桥接模式
来一个参考链接几种常用的设计模式参考博客链接
注:设计模式有很多,这里列举几种常用的!读者需要自行将这几种设计模式理解清楚!前五种是常用也是常考的!
8. 熟悉HTTP基本的状态码!
一些常见的状态码为:
- 200 - 服务器成功返回网页
- 404 - 请求的网页不存在
- 503 - 服务不可用
- 具体详细的可以参考博客 HTTP状态码详细博客链接
9. List、Set和Map的特点和区别(重点)
List:
- 1.可以允许重复的对象。
- 2.可以插入多个null元素。
- 3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
- 4.常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
Set:
- 1.不允许重复对象
- 2.无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
- 3.只允许一个 null 元素
- 4.Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map:
- 1.不是collection的子接口或者实现类。Map是一个接口。
- 2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
- 3.TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
- 4.Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
- 5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
10.监听器、过滤器、拦截器、servlet的区别
- eb.xml 的加载顺序是:context- param -> listener -> filter -> servlet
监听器(listener): - 在request、session、application三个对象创建消亡或者往其中增/删/改属性时自动执行指定代码的功能组件。
- 生命周期:随web应用的启动而启动,只初始化一次,随web应用的停止而销毁。
- 作用:做一些初始化的内容添加工作、设置一些基本的内容、比如一些参数或者是一些固定的对象等等。
过滤器(filter): - 拦截请求,filter能够在一个请求到达控制层之前预处理用户请求,也可以在离开控制层时处理http 响应,进行一些设置以及逻辑判断,然后再传入servlet或者struts的 action进行业务逻辑,基于函数回调。
- 生命周期:它是随你的web应用启动而启动的,只初始化一次,以后就可以拦截相关请求,只有当你的web应用停止或重新部署的时候才销毁。
- 作用:a.对请求或响应(Request、Response)统一设置统一编码,简化操作;b.进行逻辑判断,如用户是否已经登陆、有没有权限访问该页面等等工作。c.过滤掉非法url
拦截器(interceptor): - 拦截器是在面向切面编程中应用的,基于JAVA的反射机制,在一个业务逻辑(某个方法) 前、后调用另一个方法。
生命周期:
作用:
servlet: - servlet是一种运行服务器端的java应用程序,具有独立于平台和协议的特性,并且可以动态的生成web页面,它工作在客户端请求与服务器响应的中间层。
参考链接:参考博客链接
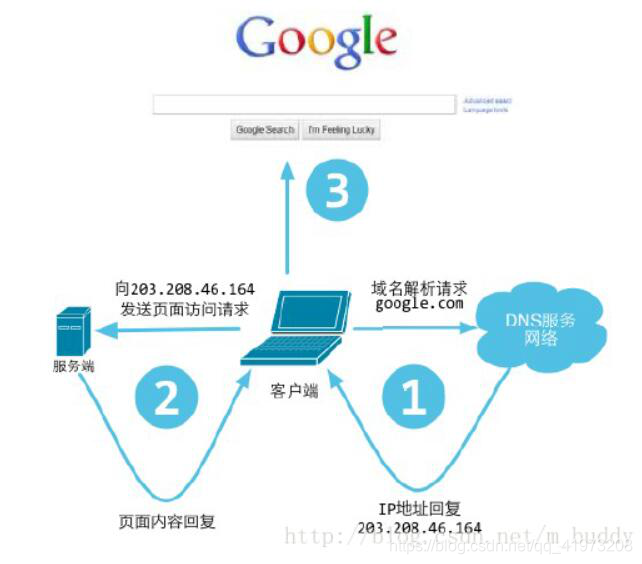
11. 当在浏览器输入一个网址,所要经过的全部在过程,请详细描述!
浏览器访问某地址的详细过程:
- 在服务器上输入一个地址:例如www.baidu.com后,回车:浏览器会根据输入的URL到DNS服务器查询对应的IP地址和域名;返回到客户端,客户端再根据所查到的的域名和IP,请求建立TCP连接,连接到对应的百度服务器,向服务器发送HTTP Request(请求),服务端接收到请求包并进行处理,并调用自身服务,返回HTTP Response(响应)。客户端接到响应的时候开始渲染这个Response包里的主体(body),等接收完所有内容后自动断开该TCP连接。
- 详细过程图:
12. 简单描述Spring的特点:
- spirng就是一个容器 ,它通过控制反转IOC和依赖注入(DI)实现高内聚、低耦合的应用。除此之外她还能整合很多第三方框架,它提供了面向切面编程AOP的能力,使其对数据库事务管理极为方便。
- 简介:Spring就是一个轻量级的开源的Java SE 和Java EE 的开发应用框架。目的在于简化企业级应用的开发。
二、数据库基础部分
1. 详细描述几种你所熟悉的优化数据库的方式。
1、选取最适用的字段属性
2、使用连接(JOIN)来代替子查询(Sub-Queries)
3、使用联合(UNION)来代替手动创建的临时表
4、事务
5、锁定表
6、使用外键
7、使用索引
8、优化的查询语句
参考链接:优化数据库的八种方式详解
2. 数据库的视图和索引都有什么特点,有什么区别?
- 概念:视图是从一个或多个表中导出来的表,是一种不是一种真正存在的概念。
- 视图操作sql:
1 //创建视图: 2 create view viewName(参数列表/可以不写这样就是默认和下面的select一样) as select * from 表名; 3 //例1: 4 create table viewdemo(id int primary key , name char(10),score float); 5 create view view1 6 as select* from viewdemo; 7 create view view2(name,score) as select name ,score from viewdemo; 8 //修改视图: 9 alter view viewname (columns) as select columns from tableName; 10 //例: 11 alter view view2 (id ,name) as select id,name from viewdemo ; 12 //删除视图: 13 drop view if exists view name; 14 //例: 15 drop view view2;
- 概念:可以理解为是一本书的目录,它记录了数据在数据库中存放的位置,就像一本书的目录,记录了,某一页在这本书的那个位置。相同地,索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据库表里所有记录的引用指针。
- 视图操作sql:
1 ALTER TABLE table_name ADD [UNIQUE|FULLTEXT] [INDEX|KEY] 2 [inex_name] (col_name [length ] ,...) [ASC|DESC]
1 普通索引: 2 ALTER TABLE book ADD INDEX indexName( bookname(30) ); 3 唯一索引: 4 ALTER TABLE book ADD UNIQUE INDEX UniqueIdx( bookid ); 5 组合索引: 6 ALTER TABLE book ADD INDEX BkAndInfoIdx( authors(20), info(50) ); 7 全文索引: 8 ALTER TABLE t6 ADD FULLTEXT INDEX infiIdx(info);( 9 前提是这个表的存储引擎为 MyISAM)
使用 create index 创建索引:
语法:
1 CREATE [UNIQUE|FULLTEXT] [INDEX|KEY] INDEX index_name 2 ON table_name ( col_name[ length ] , ... ) [ASC | DESC ] 3 例:在表book的bookname字段上建立名为BkNameIdx的索引。 4 CREATE INDEX BkNameIdx ON book (bookname); 5 例: 在book表的bookId字段上建立唯一索引。 6 CREATE UNIQUE INDEX UniqueIdx ON book (bookId); 7 4、删除索引: 8 ALTER TABLE table_name DROP INDEX index_name; 9 DROP INDEX index_name ON table_name ;
后续还会有补充,姑且先写到这吧!
我有一个微信公众号,经常会分享一些Java技术相关的干货;
如果你喜欢我的分享,可以用微信搜索“Java团长”或者“javatuanzhang”关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号