

吉林大学算法设计与分析期末复习
算法设计与分析
简答
-
以比较为基础的检索算法的时间下界是O(logn);Ω还是O?
以比较为基础的分类算法的时间下界是Ω(nlogn);
简要说明理由:理由 -
算法的五大特性:确定性,能行性,输入,输出,有穷性。
而计算过程只满足前4条特性,不满足有穷性 -
全面分析算法的两个阶段:
-
事前分析:执行次数,时间函数
-
事后分析:性能图
-
-
最优性原理:
无论过程的初始状态或者初始决策是什么,其余的决策都必须相对于初始决策所产生的状态构成一个最优决策序列。
最优性原理成立的例子:流水线调度问题,货郎担问题;
最优性原理不成立的例子:多段图问题(以乘法作为路径长度且出现负权边时 或 包含负长度环的任意两点间最短路径问题; -
贪心方法不一定能得到01背包问题的最优解。举例
-
c^(x)<=c(x) -
问题状态:树中
每一个节点确定所求解问题的一个问题状态;
状态空间:由根节点到其他节点的所有路径确定了这个问题的状态空间;
解状态:解状态是这样一些问题状态S,对于这些问题状态,由根到S的那条路径确定了这解空间中的一个元组;
答案状态:答案状态是这样一些解状态S,对于这些解状态,由根到S的那条路径确定了这问题的一个解。
解空间的树结构即为状态空间树;
4皇后问题的问题状态一共有65个? -
静态树:树结构与要解决的问题实例无关
动态树:树结构是与实例相关的,且树结构是动态确定的
活结点:自己已生成而其所有儿子结点还没有全部生成的结点
E-结点:当前正在生成其儿子结点的活结点
死结点:不再进一步扩展或其儿子结点已全部生成的结点 -
决定回溯法效率的因素
-
生成下一个X(k)的时间
-
满足显式约束条件X(k)的数目
-
限界函数Bi的计算时间
-
对于所有的i,满足Bi的X(k)的数目
-
-
分治法的求解思想:将整个问题分成若干个小问题后分而治之
-
分治法的三个基本步骤:
分:将n个输入分成k个不同的可独立求解的子问题;
治:求出这些问题的解;
合:通过适当的方法将每个问题的解合并成整个问题的解。 -
分治法适用的问题
n取值相当大,直接求解往往非常困难,甚至无法求出。
将n个输入分解成k个不同子集,得到k个不同的可独立求解的子问题。
在求出子问题的解之后,能找到适当的方法把它们合并成整个问题的解。 -
分治策略DANDC的抽象化控制
procedure DANDC(p,q)
global n,A(1:n);integer m,p,q
if SMALL(p,q) //判断输入规模q-p+1是否足够小,可直接求解
then return(G(p,q))//G是求解该规模问题的函数
else m<-DIVIDE(p,q)//分割函数,p<=m<=q,原问题被划分为A(p:m)和A(m+1:q)两个子问题
return(COMBINE(DANDC(p,m),DANDC(m+1,q)))//合并两个子问题
endif
end DANDC
-
二维极大点分治法
-
分:找出垂直于X轴的中位线L,将整个点集分为两个子集SL和SR对集合S中所有点按x值排序后,寻找第n//2点的位置
-
治:分别找出SL和SR的极大点
-
合:对于SL中的极大点p,如果py小于SR中的任一极大点的y值,则p被支配,舍弃
递归出口:如果集合S中只有一个点,那么这个点就是极大点
-
-
贪心方法的求解步骤:
- 选取一种度量标准
- 按此标准对n个输入进行排序
- 按该排序一次输入一个量
- 如果这个输入量在当前该度量意义下的部分最优解加在一起不能产生一个可行解,则不把此输入加入到这个部分解之中
-
贪心方法设计求解的核心问题是选择能产生问题最优解的
最优度量标准 -
贪心方法适用的问题的特点:
它有n个输入,而它的解就是这n个输入的某个子集,这些子集必须满足某些事先给定的条件 -
把目标函数作为度量标准所得到的解不一定是最优解
-
贪心方法的抽象化控制:
Procedure GREEDY(A,n) //A(1:n)包含n个输入 solution<-∅ for i<-1 to n do x<-SELECT(A) if FEASIBLE(solution,x) then solution<-UNION(solution,x) endif repeat return solution end GREEDY -
Q.回溯法和分支限界法的状态空间生成方式有何不同?简述两种方法的基本思想
- 回溯法:当前结点的E-结点R一旦生成一个新的儿子结点C,这个C结点就变成新的E-结点,生成下一个儿子结点
- 分支-限界法:一个E-结点一直保持到变成死节点为止
- 回溯法:加限界的深度优先生成方法称为回溯法。回溯法在包含问题的所有解的解空间树中,按深度优先的策略,从根节点出发搜索解空间树。搜索至解空间树的任一结点时,先判断改结点是否肯定不包含问题的解。如果肯定不包含,就跳过以该结点为根的子树,逐层向其祖先结点回溯。否则就进入该子树,继续按深度优先的策略进行搜索
- 分支-限界法:生成当前E-结点的全部儿子后,再生成其他活结点的儿子;使用限界函数帮助避免生成不包含答案结点子树的状态空间。
-
P类问题:所有已经找到多项式算法的问题的集合
NP类问题:所有可在多项式时间内由不确定算法验证的判定问题的集合
可满足性问题:对于变量的任一一组真值指派确定公式是否为真
COOK定理:可满足性在P内,当且仅当P=NP
NP难度:如果可满足性约化为一个问题L,则称此问题是NP难的
NP完全:如果L是NP难的而且L属于NP,则称问题L是NP完全的可满足问题是NP完全问题 -
最优二分检索树Knuth的优化方法:将k限制在区间
R(i,j-1)~R(i+1,j) -
二维极大点:
-
支配:if x1>y1 and y1>y2 :(x1,y1)支配(x2,y2)
-
if 一个点没有被其它点支配:极大点
-
-
多阶段决策过程
每一阶段都需要作出决策
i阶段的决策仅依赖于i阶段当前的状态,而与i阶段之前的过程无关 -
多阶段决策问题的目标:在所有允许选择的决策序列中,选取一个会获得问题最优解的决策序列,即
最优决策序列 -
动态规划的两个步骤:
- 证明问题满足最优性原理
- 给出递推关系式
-
最优性原理:无论过程的初始状态和初始决策是什么,其余的决策都必须相对于初始决策所产生的状态构成一个最优决策序列
-
最优性原理的证明思路:
-
设最优决策序列的形式
-
确定初始状态和初始决策
-
确定初始决策所产生的状态
-
证明其余决策相对于上一步是最优决策序列
-
-
回溯法的约束条件:
- 显式约束:限定每个xi只从一个给定的集合Si上取值。
满足显式约束的所有元组确定一个可能的解空间 - 隐式约束:描述了Xi必须彼此相关的情况。
规范函数
- 显式约束:限定每个xi只从一个给定的集合Si上取值。
-
8皇后的静态的状态空间树结点总数:
1+8+8*7+8*7*6+...+8! = 69281 -
蒙特卡洛方法估算 ppt
-
LC检索抽象化控制
算法9.1line procedure LC(T, ĉ) If T是答案结点 then 输出T; return endif E←T 将活结点表初始化为空 loop for E的每个儿子X do if X是答案结点 then 输出从X到T的那条路径; return endif call ADD(X);PARENT(X)←E repeat if 不再有活结点 then print(“no answer node”); stop endif call LEAST(E) repeat end LC算法9.2
line procedure LC1(T, ĉ) E←T 将活结点表初始化为空 loop if E是答案结点 then 输出从E到T的那条路径; return endif for E的每个儿子X do call ADD(X);PARENT(X)←E repeat if 不再有活结点 then print(“no answer node”); stop endif call LEAST(E) repeat end LC1
证明题
-
证明以比较为基础的分类算法的最坏情况的时间下界为Ω(nlogn)
- 假设参加分类的n个关键字A(1),A(2),...,A(n),各不相同,因此任意两个关键字A(i)和A(j)的比较必然导致A(i)<A(j) or A(i)>A(j)的结果。在比较树中,一个进入左分支,另一个进入右分支。各外部结点表示算法终止。由于n个关键字共有n!个排列,而每种排列可以是某种特定输入下的分类结果,因此比较树必有至少n!个外节点。
由根到外节点的路径长度即为生成该分类序列的比较长度。最坏情况的比较次数即为根到外节点的最长路径。设T(n)是为这些算法对应的比较树的最小高度。设一棵二元树的所有内节点的级数均<=k,
n!<=2T(n)
当n>1时有 n!>=n(n-1)(n-2)...(n/2)>=(n/2)n/2
对于n>=4有 T(n)>=(n/2)log(n/2)>=(n/4)logn
因此以比较为基础的分类算法的最坏情况的时间下界为Ω(nlogn)
- 假设参加分类的n个关键字A(1),A(2),...,A(n),各不相同,因此任意两个关键字A(i)和A(j)的比较必然导致A(i)<A(j) or A(i)>A(j)的结果。在比较树中,一个进入左分支,另一个进入右分支。各外部结点表示算法终止。由于n个关键字共有n!个排列,而每种排列可以是某种特定输入下的分类结果,因此比较树必有至少n!个外节点。
-
证明FIND(n)>=[log(n+1)]
- 在比较树中可知,FIND(n)不大于树中根到一个叶子的最长路径的距离。在这所有的树中都必定有n个内节点与x在A中可能得n种出现情况相对应。
如果一棵二元树的所有内节点所在的级数小于或等于级数k,则最多有2k-1个内节点。因此 n<=2k-1,即FIND(n)=k>=[log(n+1)]
- 在比较树中可知,FIND(n)不大于树中根到一个叶子的最长路径的距离。在这所有的树中都必定有n个内节点与x在A中可能得n种出现情况相对应。
-
证明E=I+2n
数学归纳法
当n=1时,E=2,I=0,所以E=I+2n成立
假设当n<=k(k>0)时,E=I+2n成立。
则当n=k+1时,不妨认定某个内节点x,且它为叶结点。设该结点层数为h,将结点及其左右子结点(外结点)从原数中删去,x替换为外结点
此时新树内部结点为k个,则满足Ek=Ik+2k
考察原树的外部路径长度和内部路径长度:
Ek+1=Ek-h+2(h+1)
Ik+1=Ik+h
Ek+1=Ik+2k+h+2
=Ik+1-h+2k+h+2
=Ik+1+2(k+1)
故命题成立 -
斯特拉森矩阵乘法


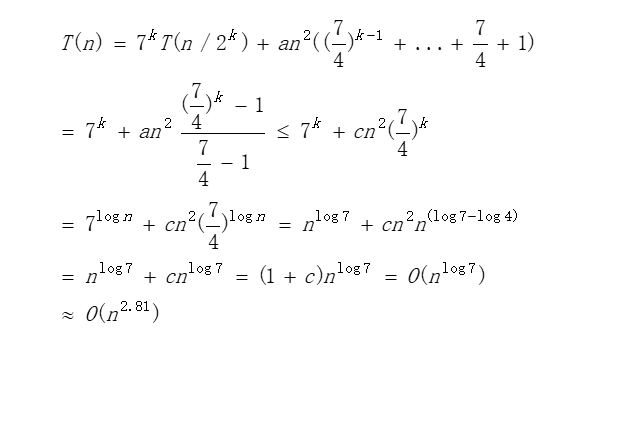
-
可分解的背包贪心证明:
设X=(x1,x2,...,xn)为算法所产生的解
1.如果所有的xi等于1,显然这个解是最优解
2.否则,设j是使得xj!=1的最小下标,由算法可知:
对于1<=i<j,xi=1
对于j<i<=n,xi=0
对于i=j,0<=xj<1
若X不是最优解,则必然存在一个最优解Y=(y1,...,yn),使得Σpiyi >Σpixi
假设Σwiyi=M,设k是使得yk!=xk的最小下标
则可以推出yk <xk成立
①k<j
则xk=1,yk<1=xk
②k=j
由于Σxiwi=M,对于1<=i<j,有xi=yi=1,而若yk>xk,则Σyiwi>M,则Y不是可行解,故yk<xk
③k>j
此时Σyiwi>M,不是可行解
现在假定把yk增加到xk,并在k+1<=j<=n中减去相同多的重量,使得容量仍为M,得到新的解Z=(z1,...,zn)
Σk<i<=nwi(yi-zi) == wk(zk-yk)
Σ1<=i<=npizi == Σ1<=i<=npiyi+(zk-yk)wkpk/wk-Σk<i<=n(yi-zi)wipi/wi
>= Σ1<=i<=npiyi+[(zk-yk)wk-Σk<i<=n(yi-zi)wi]pi/wi
== Σ1<=i<=npiyi
-
作业排序问题贪心证明

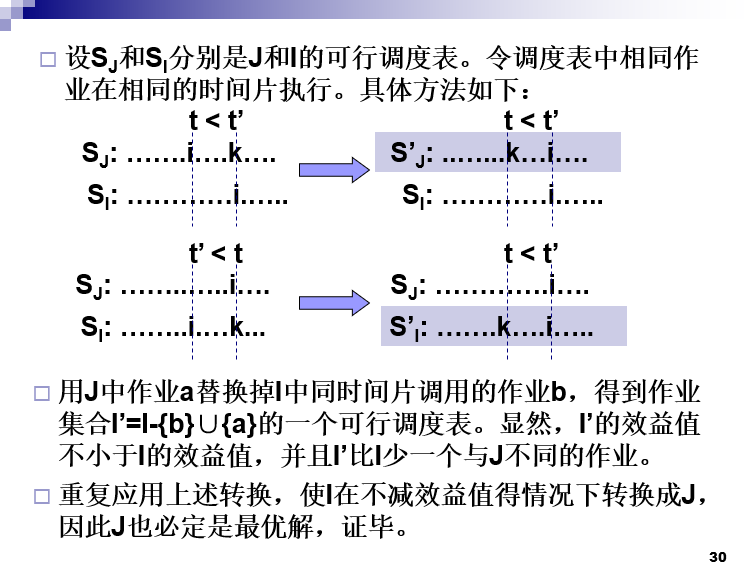
-
定理5.3:设J是k个作业的集合,σ=i1i2i3...ik是J中作业的一种排列,它使得di1<=di2<=di3<=...<=dik.J是一种可行解,当且仅当J中的作业可以按照σ的次序而又不违反任何一个期限的情况来处理。

-
磁盘排序问题

-
作业上的证明:即使作业有不同的处理时间定理5.3亦真。这里,规定作业i的效益Pi>0,要用的处理时间ti/>0,限期di/>=ti


-
0/1背包最优性原理证明:

-
多段图最优性原理证明:假设一条最优路径s,v2,v3,...,t,再假设从源点开始已经作出了v2的决策,因此v2是子问题的初始状态,子问题的最优解就是v2到t的最短路径,再反证法证明v2,v3,...,t是一条最优路径

-
多段图时空复杂度:

-
背包问题的时空复杂度:


-
背包问题的改进
- 试探法


- 试探法
-
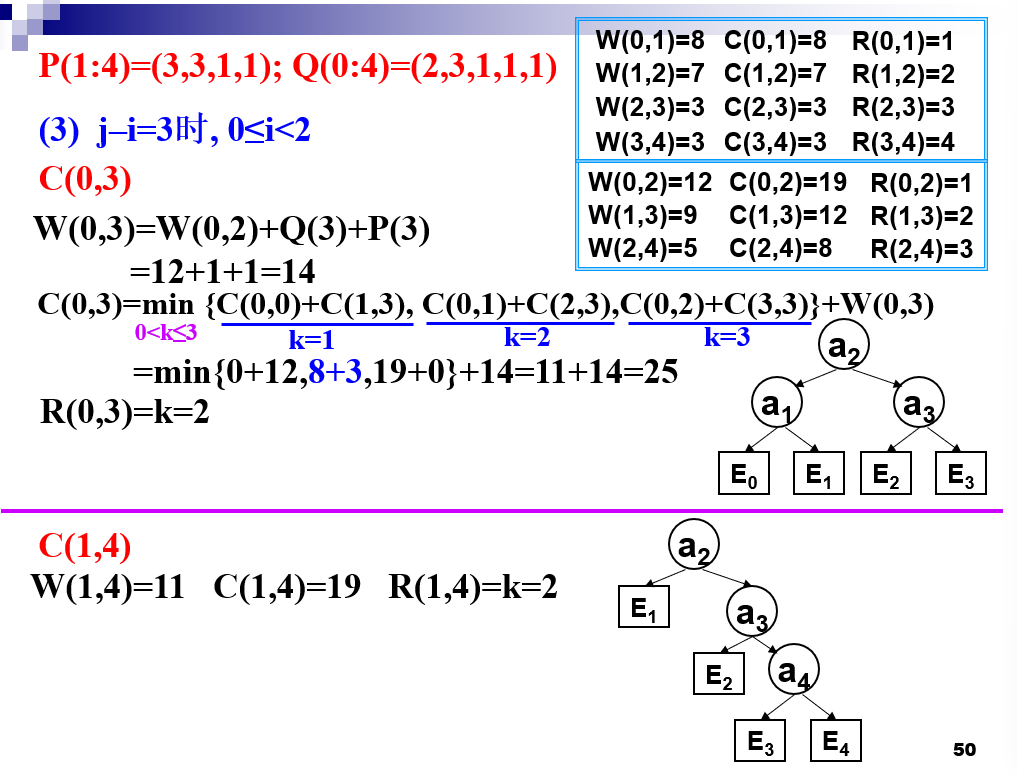
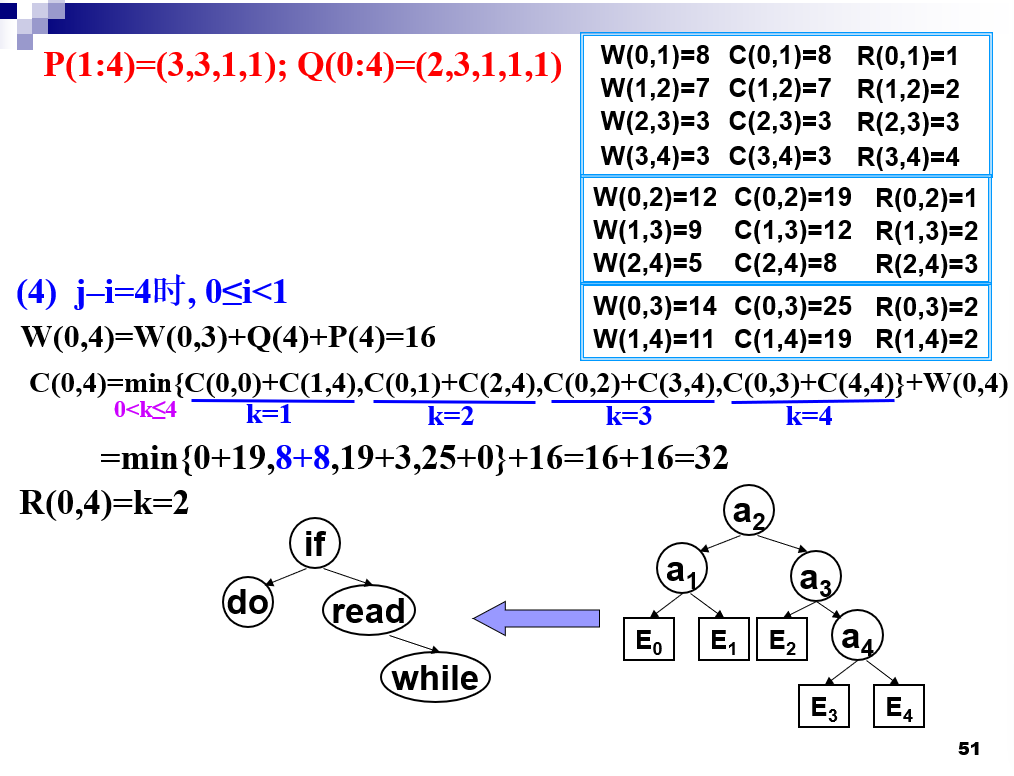
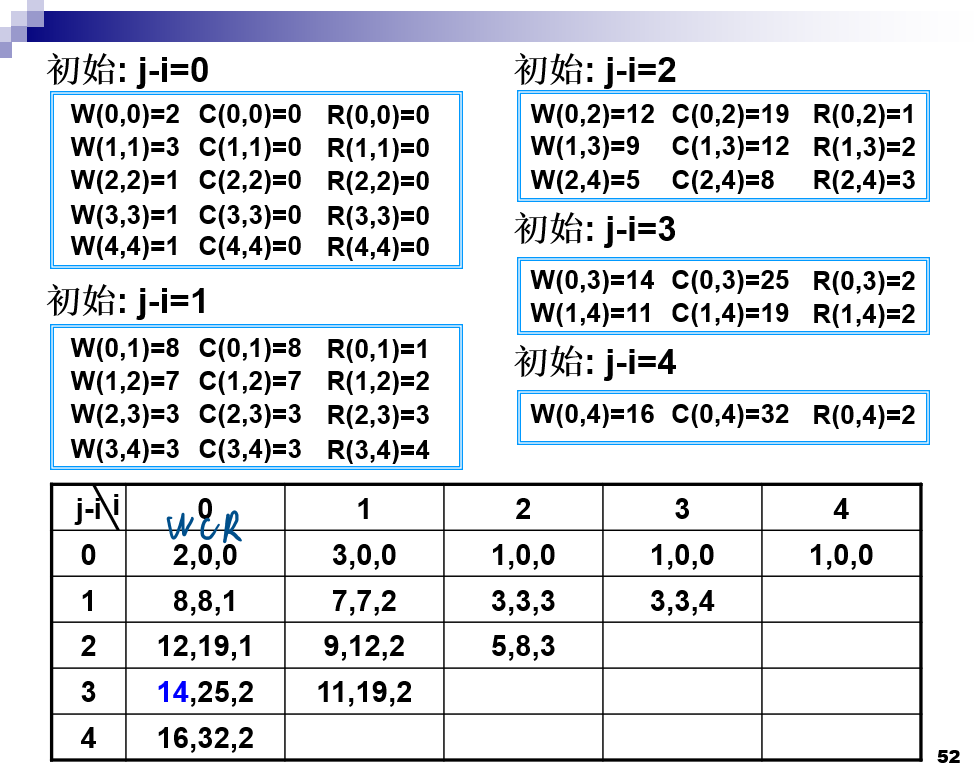
最优二分检索树
-
初始值 c[i][i] == 0,w[i][i]== q[i],0<=i<=n
R[i][i+1]=i+1,R[i][i]==0w[i][j]=q[i]+Σi+1j(q[l]+p[l])==w[i][j-1]+q[j]+p[j]
c[i][j]==min(c[i][j],c[i][k-1]+c[k][j]+p[k]+w[i][k-1]+w[k,j])==min(c[i][j],c[i][k-1]+c[k][j]+w[i][j])
-
-
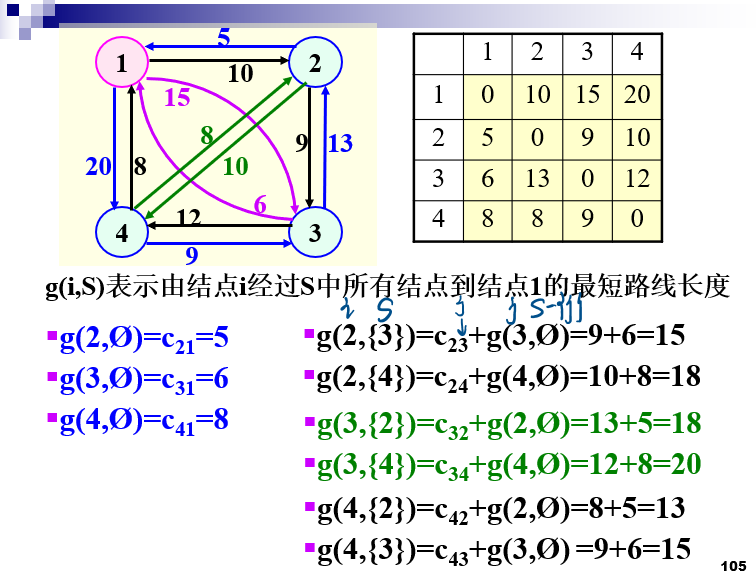
货郎担问题时间复杂度

-
定理9.2
已知若T有限且存在答案结点,LC一定能找到一个答案结点。下面证明满足已知条件时,LC能找到最小成本答案结点。

-
定理9.3
定理9.3 令ĉ是满足如下条件的函数,在状态空间树T中,对于每一个结点X,有ĉ(X)≤c(X) ,而对于T中的每一个答案结点X,有ĉ(X)=c(X)。如果算法在第5行终止,则所找到的答案结点是具有最小成本的答案结点。
证明:在第4步,结点E是答案结点,对于活结点表中的每一个结点L,一定有ĉ(E)≤ĉ(L)。由假设ĉ(E)=c(E)且对于每一个活结点L,ĉ(L)≤c(L) ,从而c(E)≤c(L),E是一个最小成本答案结点,证毕。
计算题
-
更快的作业排序
注意并查集的路径压缩
F数组下标最大值为min(n,max(di))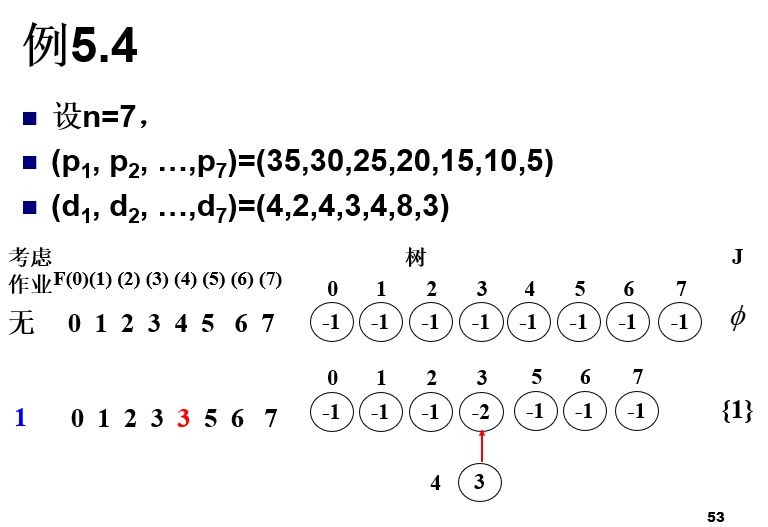
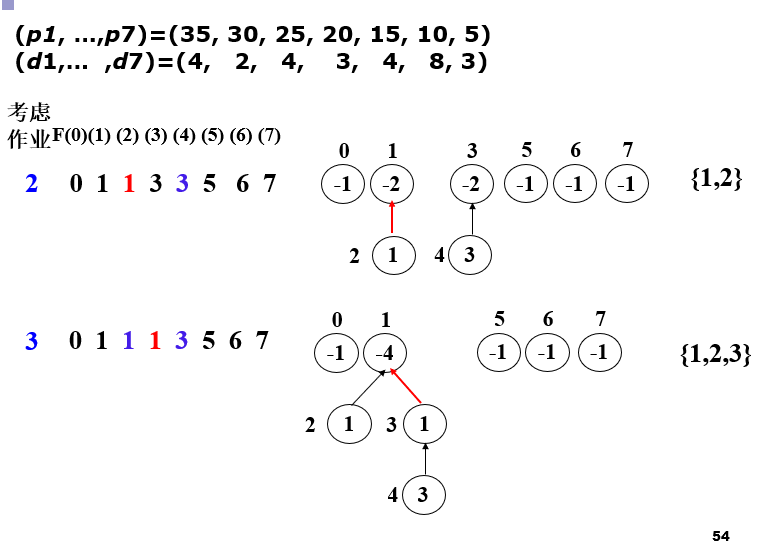
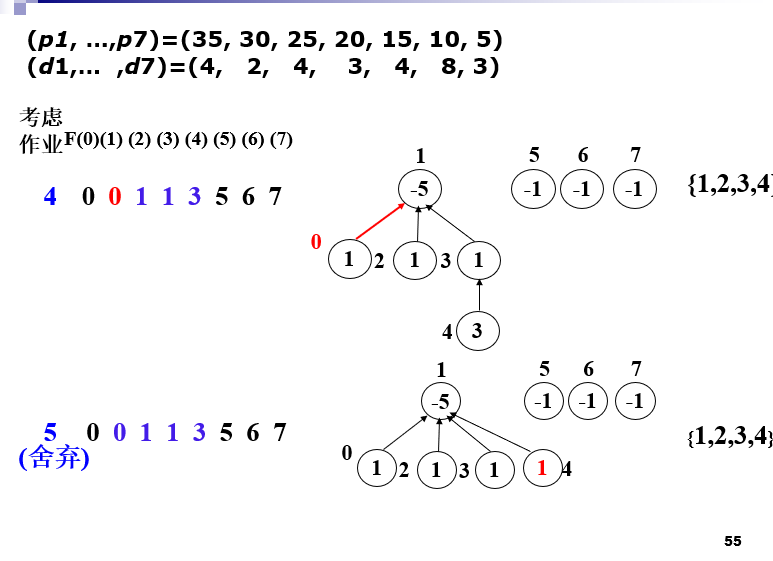
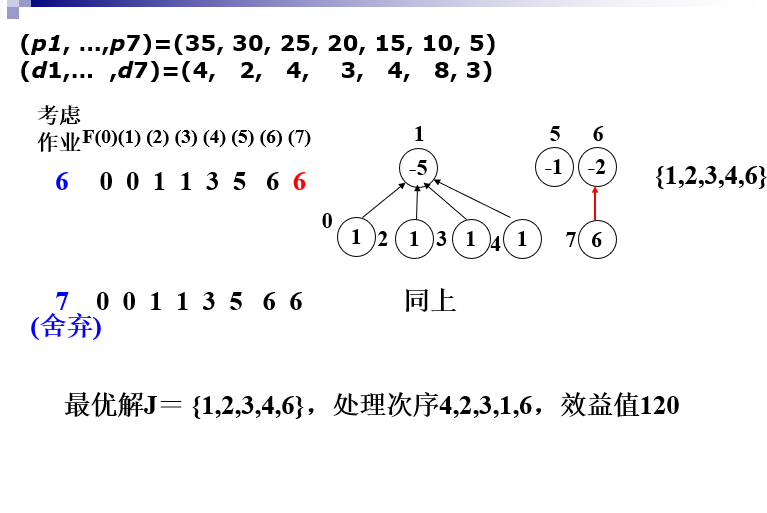
-
多段图
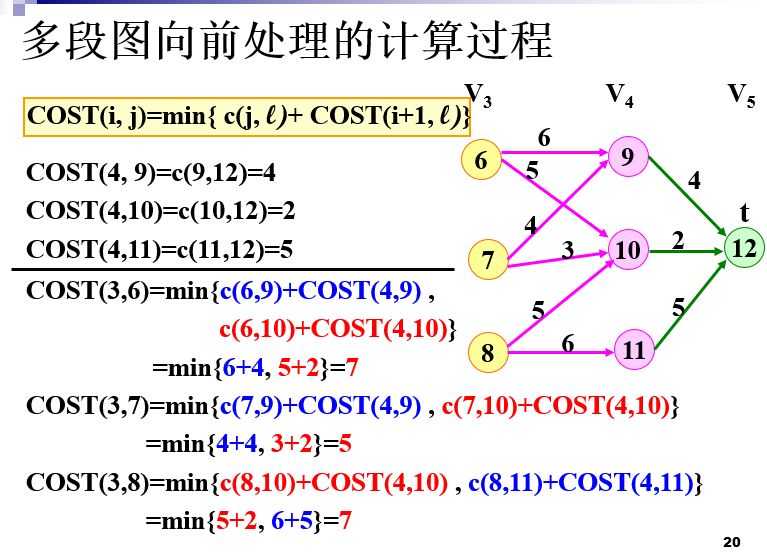
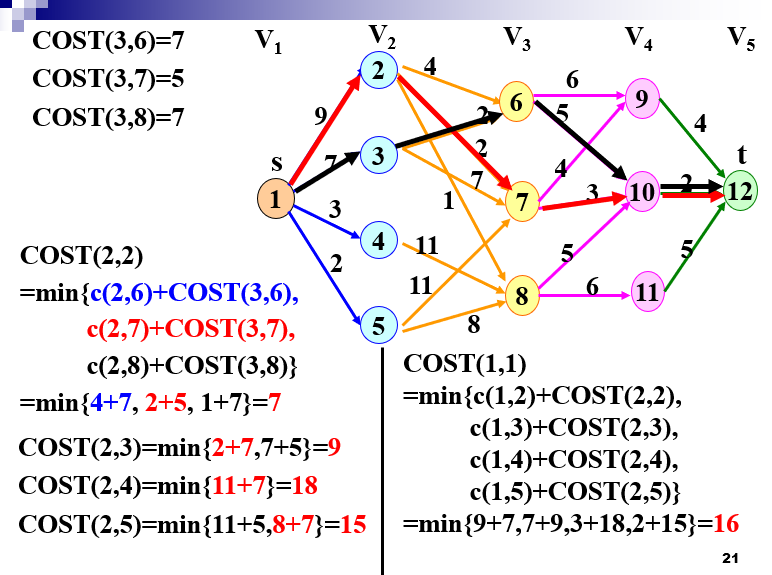

- 背包
- 最优二分检索树



- 可靠性问题:
- 货郎担

算法题
- 0/1背包问题

- 找质量不同的硬币
一种是知道假币是轻的还是重的,这时候直接二分就好了
还有一种不知道硬币多重,这时候需要三分procedure choose(low,mid,high) sum1<-sum(A,low,mid-1) sum2<-sum(A,mid,high) if sum1<sum2 then return -1 else if sum1>sum2 then return 1 else return 0 endif end choose procedure find(n,j) integer A(1:N),j//j为假币,若j=0,则不存在假币 j<=0;low<-1;high<-n while low<high do integer mid mid<-(low+high)/2 if choose(low,mid,high)==-1 then high=mid else if choose(low,mid,high)==1 then low=mid+1 else break endif repeat return j end find
三分
procedure FIND(h,p,q,r)
integer a,b,c
a<-sum(A,h,p-1)
b<-sum(A,p,q-1)
c<-sum(q,r)
if p=q-1 then//只有三个元素时
if a=b then return a
else if a=c then return p
else return h
endif
else
if a=b then h<-q,p<-(r-q+1)/3+q,q<-2(r-q+1)/3+q
else if a==c then h<-p,q<-2(q-p)/3p,r<-q-1,p<-(q-p)/3+p
else q<-2(p-h)/3,r<-p-1,p<-(p-h)/3
endif
endif
call FIND(h,p,q,r)
end FIND
- 同构二叉树
bool isotree(TreeNode *root1,TreeNode* root2){
if(!root1 and !root2)return true;
if(!root or !root2)return false;
if(root1->val!=root2->val)return false;
if isotree(root1.left,root2.left) and isotree(root1.right,root2.right) then
return True
if isotree(root1.right,root2.left) and isotree(root1.left,root2.right) then
return True
return
}
- 自底向上的归并
Procedure MERGESORT(n)
integer low,mid,high,step,k
step<-1;k<-logn
while step<=2**k do //自底向上,区间要从小枚举
low<- 1
while low+step-1<n do //右边界
mid<-low+step-1 //(low,low+step-1),(low+step,mid+step)
high<-min(mid+step,n)
MERGE(low,mid,high);
low<-high+1;
repeat
step<-step*2
repeat
end MERGESORT
- 三分检索
Procedure ThriSearch(A,x,n,j)
integer low,mid1,mid2,high
low<-1;high<-n
while low<=high do
mid1<-(2*low+high)//3
mid2<-(low+2*high)//3
case
:x=A(mid1):j<-mid1;return
:x=A(mid2):j<-mid2;return
:x<A(mid1):high<-mid1-1
:x>A(mid2):low<-mid2+1
:else: low<-mid1+1;high<-mid2-1
-
找零 完全背包
def coinChange(self, coins: List[int], amount: int) -> int: coins.insert(0,0) dp=[inf]*(amount+1) dp[0]=0 for i in range(len(coins)): for j in range(coins[i],amount+1): dp[j]=min(dp[j],dp[j-coins[i]]+1) return dp[-1] if dp[-1]<inf else -1 -
找零 贪心
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;//要找的钱
int res = 0, coins[4] = {64,16,4,1};//纸币面额
for(int i = 0; i < 4; i++)
{
res += n / coins[i];
n %= coins[i];
}
cout << res << endl;
}
- 旅行商问题
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=20,M=1<<N;
int f[M][N],w[N][N];//w表示的是无权图
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
cin>>w[i][j];
memset(f,0x3f,sizeof(f));//因为要求最小值,所以初始化为无穷大
f[1][0]=0;//因为零是起点,所以f[1][0]=0;
for(int i=0;i<1<<n;i++)//i表示所有的情况
for(int j=0;j<n;j++)//j表示走到哪一个点
if(i>>j&1)
for(int k=0;k<n;k++)//k表示走到j这个点之前,以k为终点的最短距离
if(i>>k&1)
f[i][j]=min(f[i][j],f[i-(1<<j)][k]+w[k][j]);//更新最短距离
cout<<f[(1<<n)-1][n-1]<<endl;//表示所有点都走过了,且终点是n-1的最短距离
//位运算的优先级低于'+'-'所以有必要的情况下要打括号
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号