
四.python3 字符编码
计算机最底层能识别的
二进制数:0,1
为将二进制数转变成人能看懂的文字
中国
发展出 ------>ASCII:只能存英文和拉丁字符。 一个字符占一个字节,八位
------>gb2312 :只能存6700多个中文, 1980
------>gbk1.0:存了2万多字符, 1995
------>gb18030:存了2万7千个中文, 2000
国际
----------------------------->unicode(相当于一个标准):utf-32(unicode的一个表现形式,编码集): 一个任意字符占4个字节
------>unicode:utf-16: 一个字符占2个字节或2个以上(如果找不到字符对应的编码就在utf-32中去找)
------>unicode-8: 一个英文用ASCII码来存,一个中文占3个字节
中国标准用的是gbk
windows系统用的是gb18030
编码和解码
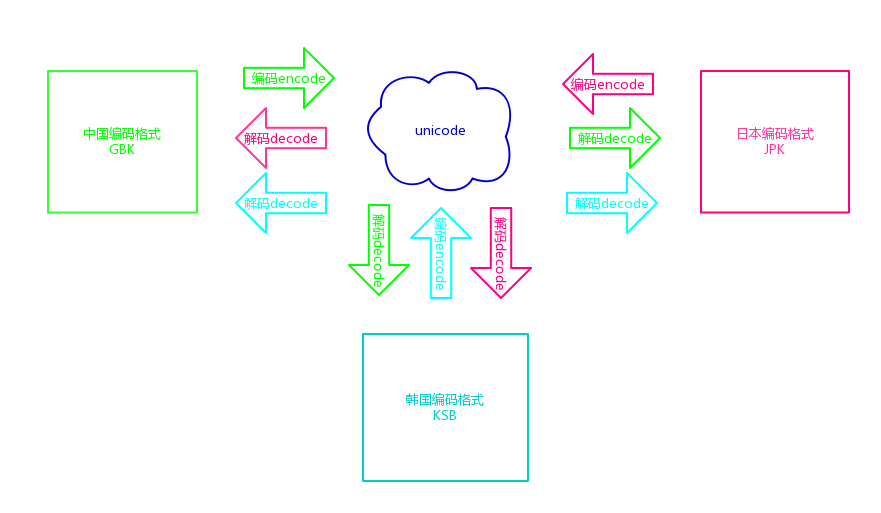
python 2.x中的默认编码是ASCII,内存中默认的unicode:utf-16
pyhthon2使用命令行,执行如下,CMD显示编码使用GBK CHAP
s = "红色"
s_to_unicode = s.decode("utf-8")
unicode_to_gbk = s_to_unicode.encode("gbk")
print("unicode",s_to_unicode)
print("gbk",unicode_to_gbk)
utf8转成unicode,unicode向下兼容gbk,所以可以显示正确的中文,unicode最后转成gbk.
python 3.x中的所有字符的默认编码是unicode,文件的默认编码是utf-8,
encode 在编码的同时,会把数据转成bytes类型
decode 在解码的同时,会把bytes类型转成字符串
b = byte = 字节类型 = [0-255]
s = "red 红色"
s_to_gbk = s.encode("gbk")
print(s)
print(s_to_gbk.decode("gbk"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号