从零开始部署pytorch+yovov4模型
之前部署了直接在win中运行的模型。考虑到很多模型都是在pytorch 中跑的,练习一下pytorch的配置过程。
1.首先有一个pytorch环境。
环境内容
torch:1.2.0
torchvision:0.4.0
Anaconda安装
最新版本的Anaconda没有VSCODE,如果大家为了安装VSCODE方便可以直接安装旧版的Anaconda,百度网盘连接如下。也可以装新版然后分开装VSCODE。
链接:https://pan.baidu.com/s/1MEdjh976CYotuQgiRWkdPA
提取码:1234
下载好了之后,选择合适路径,直接安装就好。
我选择了Add Anaconda to my PATH environment variable,我用起来觉得更好用。
等待安装完之后,就安装了Anaconda了。
下载Cudnn和CUDA
我这里使用的是torch=1.2.0,官方推荐的Cuda版本是10.0,因此会用到cuda10.0,与cuda10.0对应的cudnn是7.4.1.5,这个组合我实验过了,绝对是可以用的。
cude10和cudnn可以在官网下载,懒得找的我贴个百度云连接:
链接:https://pan.baidu.com/s/1UCOrvg8pU4kZ2ro6JQhxQQ
提取码:1234
下载好之后可以打开cuda_10的exe文件进行安装。
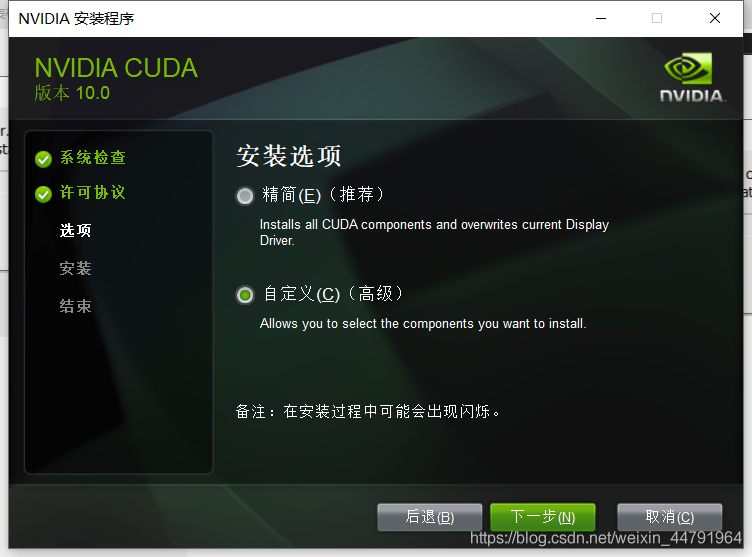
这里选择自定义。
然后直接点下一步就行了。
安装完后在C盘这个位置可以找到根目录。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
然后大家把Cudnn的内容进行解压。
把这里面的内容直接复制到C盘的根目录下就可以了。
配置torch环境
Win+R启动cmd,我没有启动cmd,而是启动的anacade 的
在命令提示符内输入以下命令:
创建环境:
conda create –n pytorch python=3.6
激活环境:
activate pytorch
打开pytorch的官方安装方法:
https://pytorch.org/get-started/previous-versions/
官网推荐的安装代码如下,我使用的是Cuda10的版本:
# CUDA 10.0 pip install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html # CUDA 9.2 pip install torch==1.2.0+cu92 torchvision==0.4.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html # CPU only pip install torch==1.2.0+cpu torchvision==0.4.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
需要注意的是,直接这样安装似乎特别慢。虽然慢,但我还是用这种慢的方式装的,当时速度还可以。好的,继续参考大佬博客:因此我们可以进入如下网址:
https://download.pytorch.org/whl/torch_stable.html
找到自己需要的轮子下载。
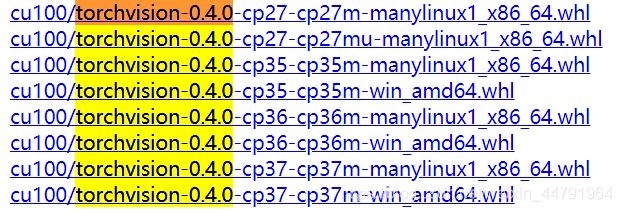
下载的时候使用迅雷下载就行了,速度还是比较快的!
下载完成后找到安装路径:
在cmd定位过来后利用文件全名进行安装就行了!
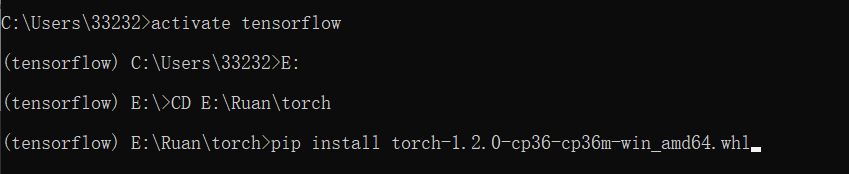
这里我也传一个百度网盘的版本。
链接: https://pan.baidu.com/s/14-QVk7Kb_CVwaVZxVPIgtw
提取码: rg2e
全部安装完成之后重启电脑。
以上就是安装pytorch的全部过程了。如何检测自己安装的环境是成功的呢?
打开cmd或者anacodnda prompt输入
import torch a = torch.cuda.is_available() print(a) ngpu= 1 device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu") print(device) print(torch.cuda.get_device_name(0)) print(torch.rand(3,3).cuda())
输出样例:
True
cuda:0
GeForce GTX 1650
tensor([[0.0387, 0.8379, 0.6165],
[0.4231, 0.0060, 0.9049],
[0.7293, 0.1726, 0.9432]], device='cuda:0')
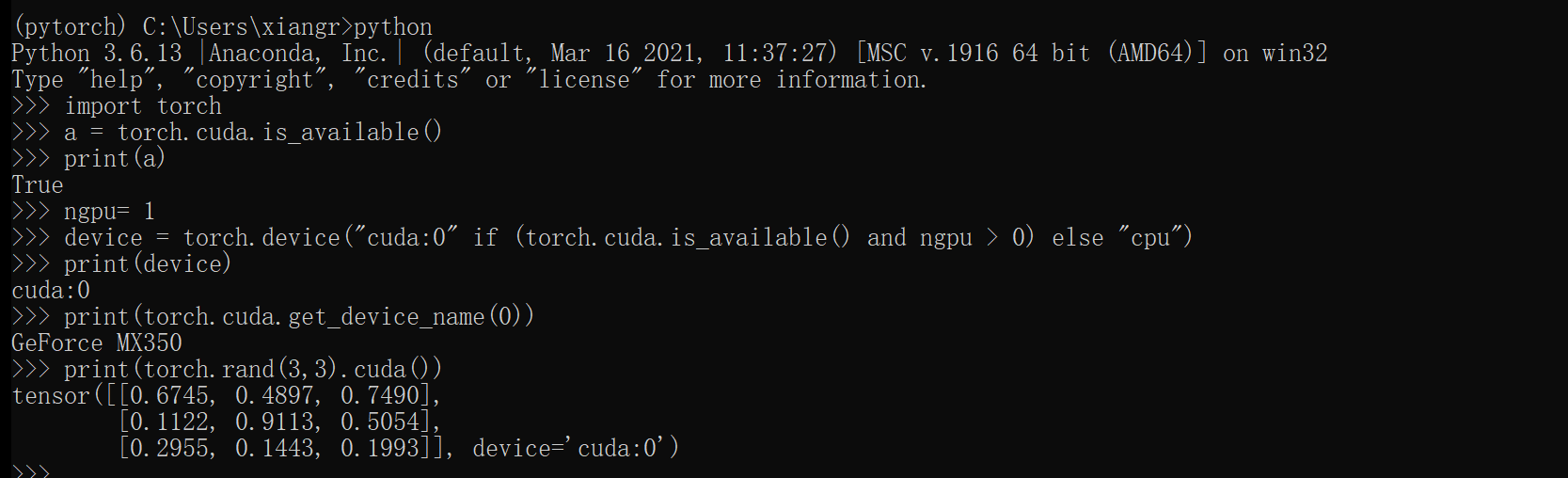
就表示成功配置了pytorch环境。
安装VSCODE
为了方便编辑代码,需要安装编辑器。
打开anaconda,切换环境。
安装VSCODE,安装完就可以launch一下了,之后就可以把VScode固定到任务栏上,方便打开。
当然,安装pycharm也很好用。贴个我的安装包:
链接:https://pan.baidu.com/s/1LUfAtHrYbIfhpD4dd_JsAA
提取码:1234
2. 运行代码
下载代码
安装好环境之后,就是运行代码了。有GPU加持的笔记本可以进行简单的视频识别。我使用的代码是github这位大佬的,大家可以来参考:
https://github.com/bubbliiiing/yolov4-pytorch#Reference
直接下载之后解压即可。
下载完库后解压,在百度网盘下载yolo4_weights.pth或者yolo4_voc_weights.pth,放入model_data,
网上有很多,我发个我在用的吧:
链接:https://pan.baidu.com/s/1PjIfRjI8nLFL_QFgrR3QEw
提取码:1234
打开anaconda的命令行:
#依次输入 activate pytorch#进入pytorch环境 #进入解压代码的文件夹:例如:cd E:\github\yolov4-bubbliiiing\yolov4-pytorch-master #然后运行里面的predict.py文件 python predict.py #然后输入需要识别的图片路径 img/street.jpg #这是图片识别;对于视频识别和摄像头识别,只需要打开predict.py文件进行修改即可
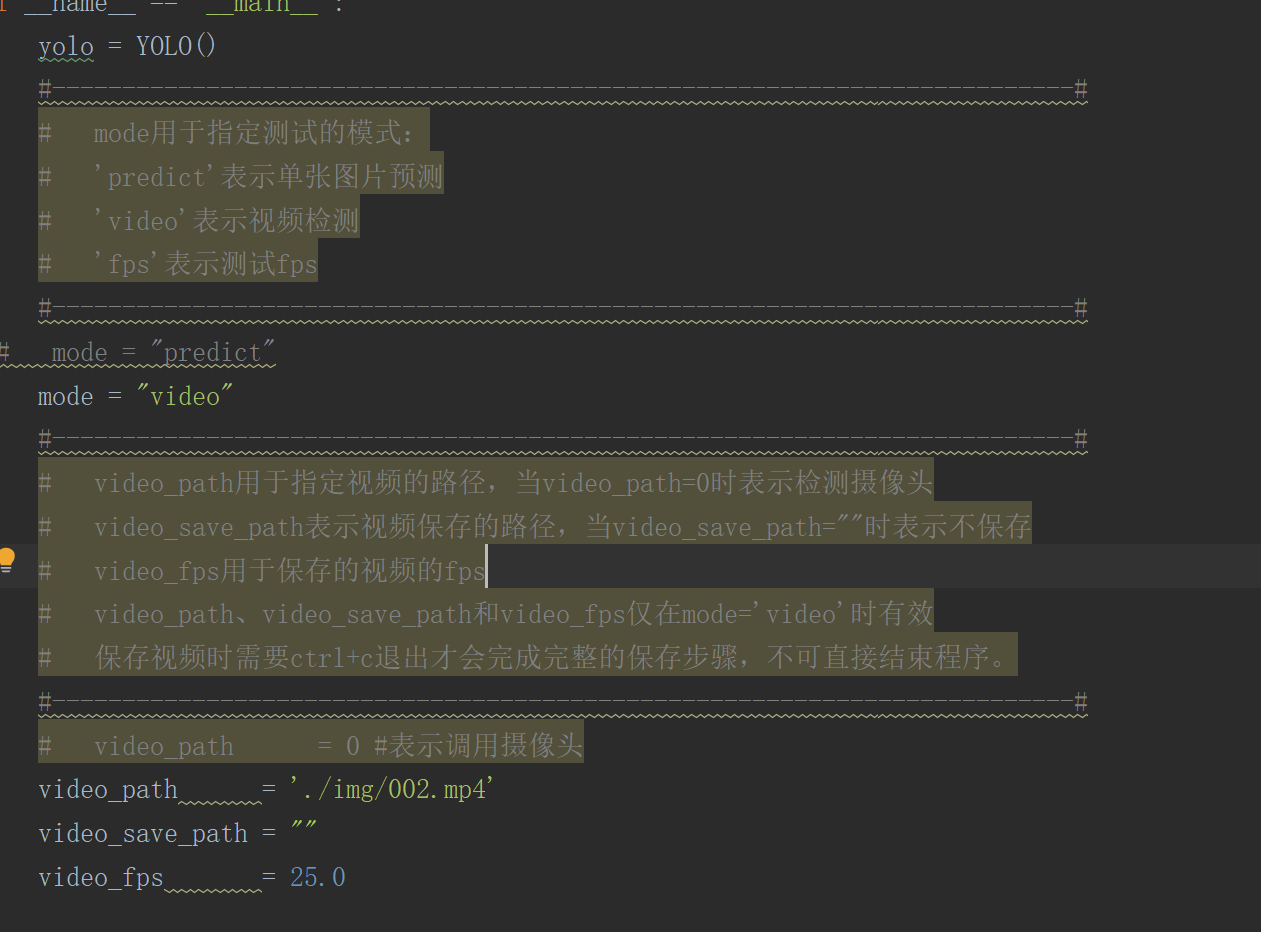
修改对应的命令行,即可调用视像头或者是视频识别。
以上就是我全部的配置过程,后续会进行训练自己的数据,欢迎大家在留言区探讨!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号