
UTF-8 不需要 BOM,尽管 Unicode 标准允许在 UTF-8 中使用 BOM。
所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下:把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。
BOM(byte order mark)是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题。
「UTF-8」和「带 BOM 的 UTF-8」的区别就是有没有 BOM。即文件开头有没有 U+FEFF。
UTF-8 的网页代码不应使用 BOM,否则常常会出错。这是一个小例子: 为什么这个网页代码 <head> 内的信息会被浏览器理解为在 <body> 内?
另附《The Unicode Standard, Version 6.0》之 3.10 D95 UTF-8 encoding scheme 的一段话:
所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下:把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。
BOM(byte order mark)是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题。
「UTF-8」和「带 BOM 的 UTF-8」的区别就是有没有 BOM。即文件开头有没有 U+FEFF。
UTF-8 的网页代码不应使用 BOM,否则常常会出错。这是一个小例子: 为什么这个网页代码 <head> 内的信息会被浏览器理解为在 <body> 内?
另附《The Unicode Standard, Version 6.0》之 3.10 D95 UTF-8 encoding scheme 的一段话:
While there is obviously no need for a byte order signature when using UTF-8, there are occasions when processes convert UTF-16 or UTF-32 data containing a byte order mark into UTF-8. When represented in UTF-8, the byte order mark turns into the byte sequence. Its usage at the beginning of a UTF-8 data stream is neither required nor recommended by the Unicode Standard, but its presence does not affect conformance to the UTF-8 encoding scheme. Identification of the byte sequence at the beginning of a data stream can, however, be taken as a near-certain indication that the data stream is using the UTF-8 encoding scheme.
---------------------------------------------------------------------------------------------------------------------------
字符编码相信是每个程序员的噩梦,只要是有中文的地方,总是会遇到各种编码的问题,并且这种问题还非常难缠,尤其在linux上,因为上面很多软件都是针对英语国家开发的,是不会考虑其他语种编码问题。在遇到编码的无数大坑之后,我决定仔细研究下编码问题,因为这就像一道坎一直横在你面前,每次到这里你都会跌到,每次爬起来之后,你都若无其事,这样的人被称作战士,真正的战士。可惜是个力量战士,做为新时代的智力战士,当然不能在那跌到然后又在这继续跌到。
文件的存储方式:
文件都有自己的存储格式,比如最常见的txt,cpp,h,c,xml ,png, rmvb各种格式,还有自定义格式。这些文件不论是什么格式,都是存储在计算机硬盘里的2进制格存储,对应不同文件格式,有不同的软件解析。这篇文章不谈文件是如何存储的,只谈文件是如何解析的。
文本文件解析:
文本文件对应于人类可以阅读的文本,如何从2进制转换为文本文件呢?起初由于计算机在美国发明,自然大家考虑的是英语如何表示,英语字母总共26个,加上特殊字符,128个字符,7位既一个byte即可表示出来。这个就是大家所熟知的ascill编码。对应关系很简单,一个字符对应一一个byte。
但很快发现,其他非英语国家的文字远远超过ascill码,这时候大家当然想统一一下,不同国家出了自己不同的编码方式,中国的gb2312就是自己做出来的编码方式,这样下去每个国家都有自己的编码方式,来回转换太麻烦了。这时候出现了新的编码方式,unicode编码方式,想将编码统一,所以规定了每个字符对应的unicode码。
1、很多文件都是ascii编码,如果用unicode 太浪费。
2、没有标志位说明该几个字节来解析为一个符号。
这时候拯救世界的utf出现了,utf是unicode的一种实现,只不过更聪明了。utf16是占用两字节,或者四字节,utf32是占用四字节。utf8是很聪明的一种表示方式。
1、对于单字节符号,字节第一位为0,后面7位表示字节编码。
2、对于n字节符号,第一字节的前n位都设为1,第n+1位为0,其余位位编码位置。
对于不同的编码,在文本的最前方有不同的标志,unicode 通常有两位来表示分别是ff fe, 或者feff, fffe表示litte-endian 编码feff表示big-endian编码。utf8是efbbbf来开头的。可以看出来utf-8是自解释的,所以不用带这个标志文件,大多数程序是可以识别的。但有些程序不能识别这个标志,比如php就会直接把这个标志当文本解析,不会忽略。相信很多遇到php输出文本解析乱码或者解析错误的同学都遇到这样的问题。
最后说说如何去掉或者加上bom,如果有vim那最好不过了,去掉命令:
set encoding=utf-8
set nobomb
添加命令:
set encoding=utf-8
set bomb
字符编码相信是每个程序员的噩梦,只要是有中文的地方,总是会遇到各种编码的问题,并且这种问题还非常难缠,尤其在linux上,因为上面很多软件都是针对英语国家开发的,是不会考虑其他语种编码问题。在遇到编码的无数大坑之后,我决定仔细研究下编码问题,因为这就像一道坎一直横在你面前,每次到这里你都会跌到,每次爬起来之后,你都若无其事,这样的人被称作战士,真正的战士。可惜是个力量战士,做为新时代的智力战士,当然不能在那跌到然后又在这继续跌到。
文件的存储方式:
文件都有自己的存储格式,比如最常见的txt,cpp,h,c,xml ,png, rmvb各种格式,还有自定义格式。这些文件不论是什么格式,都是存储在计算机硬盘里的2进制格存储,对应不同文件格式,有不同的软件解析。这篇文章不谈文件是如何存储的,只谈文件是如何解析的。
文本文件解析:
文本文件对应于人类可以阅读的文本,如何从2进制转换为文本文件呢?起初由于计算机在美国发明,自然大家考虑的是英语如何表示,英语字母总共26个,加上特殊字符,128个字符,7位既一个byte即可表示出来。这个就是大家所熟知的ascill编码。对应关系很简单,一个字符对应一一个byte。
但很快发现,其他非英语国家的文字远远超过ascill码,这时候大家当然想统一一下,不同国家出了自己不同的编码方式,中国的gb2312就是自己做出来的编码方式,这样下去每个国家都有自己的编码方式,来回转换太麻烦了。这时候出现了新的编码方式,unicode编码方式,想将编码统一,所以规定了每个字符对应的unicode码。
1、很多文件都是ascii编码,如果用unicode 太浪费。
2、没有标志位说明该几个字节来解析为一个符号。
这时候拯救世界的utf出现了,utf是unicode的一种实现,只不过更聪明了。utf16是占用两字节,或者四字节,utf32是占用四字节。utf8是很聪明的一种表示方式。
1、对于单字节符号,字节第一位为0,后面7位表示字节编码。
2、对于n字节符号,第一字节的前n位都设为1,第n+1位为0,其余位位编码位置。
对于不同的编码,在文本的最前方有不同的标志,unicode 通常有两位来表示分别是ff fe, 或者feff, fffe表示litte-endian 编码feff表示big-endian编码。utf8是efbbbf来开头的。可以看出来utf-8是自解释的,所以不用带这个标志文件,大多数程序是可以识别的。但有些程序不能识别这个标志,比如php就会直接把这个标志当文本解析,不会忽略。相信很多遇到php输出文本解析乱码或者解析错误的同学都遇到这样的问题。
最后说说如何去掉或者加上bom,如果有vim那最好不过了,去掉命令:
set encoding=utf-8
set nobomb
添加命令:
set encoding=utf-8
set bomb
---------------------------------------------------------------------------------------------------------------------------
ANSI 确实是遗留编码,在不同语言的系统中编码不同,这一部分在微软的术语中叫 code page。比如所谓 GBK 编码,实际上更多地被叫做 CP936。这个术语是从 IBM 早期的一些工作中继承下来的,现在也没改变。但是,代码页这个概念在引入更大的字符集时已经遇到了问题,比如当初 GBK 扩展到 GB18030 时,它无法自然地用同一个代码页解决问题,不得不使用非常复杂的映射技术在几个代码页中切换才最终达到目的。
所谓微软的 Unicode,确实是 UTF-16LE。这个问题上 MSDN 文档在术语运用上有很多前后矛盾的地方,所以很多程序员都不太了解。再加上微软 SDK 默认的 WCHAR 是两个字节,进一步加剧了混乱程度。事实上时至今日,微软的默认编码不一定是两字节了,因为 Unicode 早已超过了 65536 个字符。
如果是为了跨平台,那么最有效的办法确实是坚持使用 UTF-8。不过是否使用 BOM 则未必真的需要很纠结。事实上现代的编辑器都可以很好地处理 BOM,比如 VIM。在 UNIX 环境下不适合使用 BOM 的场合有两个:一个是 XML,另一个是老旧的 shell 脚本。前者是因为规范里就没有 BOM 的位置,而后者则是因为历史原因而不能很好支持。而更大范围内的应用,比如 Python 脚本,则可以很好地处理 BOM。
所谓微软的 Unicode,确实是 UTF-16LE。这个问题上 MSDN 文档在术语运用上有很多前后矛盾的地方,所以很多程序员都不太了解。再加上微软 SDK 默认的 WCHAR 是两个字节,进一步加剧了混乱程度。事实上时至今日,微软的默认编码不一定是两字节了,因为 Unicode 早已超过了 65536 个字符。
如果是为了跨平台,那么最有效的办法确实是坚持使用 UTF-8。不过是否使用 BOM 则未必真的需要很纠结。事实上现代的编辑器都可以很好地处理 BOM,比如 VIM。在 UNIX 环境下不适合使用 BOM 的场合有两个:一个是 XML,另一个是老旧的 shell 脚本。前者是因为规范里就没有 BOM 的位置,而后者则是因为历史原因而不能很好支持。而更大范围内的应用,比如 Python 脚本,则可以很好地处理 BOM。
作者:时国怀
链接:https://www.zhihu.com/question/20650946/answer/15751688
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/20650946/answer/15751688
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
ANSI:最早的时候计算机ASCII码只能表示256个符号(含控制符号),这个字符集表示英文字母足够,其中,我们键盘上可见的符号的编码范围是从32到126(大小写英文字母、数字、英文符号等)。但表示汉字、日语、韩语就不太够用了,汉字常用字有3000多个。
但是中国人也要用电脑打字,于是,中国人就研究出来了最早的中文字符集GB2312(GBK就是后来的扩展),GB2312的做法是,把ASC码取值范围的128~255这个区间挪用了一下,用两个ASC码表示一个汉字,这样可用的编码范围用十六进制表示就是0x8080到0xFFFF,这大概能表示一万多个符号,足够了。[注:实际没用那么多,GBK的范围是8140-FEFE]
那个时候,计算机技术还不发达,各个国家搞自己的,比如台湾,也另搞了一套,叫BIG5(俗称:大五码),跟大陆的也不太一样,但方法是类似的,都是用0x80到0xFF这个区间。
然后日语(有编码JIS)、韩语等等也各搞一套。
这些国家的编码区间都是重叠的,但同一个汉字(比如有一些汉字同时存在于简体、繁体、日语汉字中)有不同的编码,很混乱是不是?但也凑合用了。编码不同导致了很多麻烦,比如一个网页,如果你不知道它是什么编码的,那么你可能很难确定它显示的是什么,一个字符可能是大陆简体/台湾繁体/日本汉字,但又完全是不同的几个字。
所以如果用一些很老的软件,可能会听说有中文版/日文版之类的,对应的版本只能在对应的系统上运行。
后来,这个对操作系统的开发实在是太困难了,因为这意味着不同语言的版本,都要重新编码。于是发明了Unicode。
但是中国人也要用电脑打字,于是,中国人就研究出来了最早的中文字符集GB2312(GBK就是后来的扩展),GB2312的做法是,把ASC码取值范围的128~255这个区间挪用了一下,用两个ASC码表示一个汉字,这样可用的编码范围用十六进制表示就是0x8080到0xFFFF,这大概能表示一万多个符号,足够了。[注:实际没用那么多,GBK的范围是8140-FEFE]
那个时候,计算机技术还不发达,各个国家搞自己的,比如台湾,也另搞了一套,叫BIG5(俗称:大五码),跟大陆的也不太一样,但方法是类似的,都是用0x80到0xFF这个区间。
然后日语(有编码JIS)、韩语等等也各搞一套。
这些国家的编码区间都是重叠的,但同一个汉字(比如有一些汉字同时存在于简体、繁体、日语汉字中)有不同的编码,很混乱是不是?但也凑合用了。编码不同导致了很多麻烦,比如一个网页,如果你不知道它是什么编码的,那么你可能很难确定它显示的是什么,一个字符可能是大陆简体/台湾繁体/日本汉字,但又完全是不同的几个字。
所以如果用一些很老的软件,可能会听说有中文版/日文版之类的,对应的版本只能在对应的系统上运行。
后来,这个对操作系统的开发实在是太困难了,因为这意味着不同语言的版本,都要重新编码。于是发明了Unicode。
Unicode这个东西,就是要把地球上所有的语言的符号,都用统一的字符集来表示,一个编码真正做到了唯一。
Unicode里有几种方式:
UTF-16BE/LE:UTF-16就是Windows模式的编码模式(Windows里说的Unicode一般都是指这种编码),用2个字节表示任意字符,注意:英文字符也占2个字节(变态不?),这种编码可以表示65536个字符,至于LE和BE,就是一个数值在内存/磁盘上的保存方式,比如一个编码0x8182,在磁盘上应该是0x81 0x82呢?还是0x82 0x81呢?就是高位是最先保存还是最后保存的问题,前者为BE,后者为LE。
UTF-8:UTF-8则是网页比较流行的一种格式:用一个字节表示英文字符,用3个字节表示汉字,准确的说,UTF-8是用二进制编码的前缀,如果某个UTF-8的编码的第一个字节的最高二进制位是0,则这个编码占1字节,如果是110,则占2字节,如果是1110,则占3字节……
好了,说了这么,再来研究Windows的记事本。
Windows早期(至少是95年以前的事情了)是ANSI字符集的,也就是说一个中文文本,在Windows简体中文版显示的是中文,到Windows日文版显示的就不知道是什么东西了。
后来,Windows支持了Unicode,但当时大部分软件都是用ANSI编码的,unicode还不流行,怎么办?Windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是unicode的时候,就用默认语言编码解释。(在区域和语言选项里可以改默认语言)
这个默认语言,在不同Windows语言版本里是不同的,在简体中文版里,是GBK,在繁体中文版里,是BIG5,在日文版里是JIS
而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本也不甘心这样,所以它要支持Unicode,但是有一个问题,一段二进制编码,如何确定它是GBK还是BIG5还是UTF-16/UTF-8?记事本的做法是在TXT文件的最前面保存一个标签,如果记事本打开一个TXT,发现这个标签,就说明是unicode。标签叫BOM,如果是0xFF 0xFE,是UTF16LE,如果是0xFE 0xFF则UTF16BE,如果是0xEF 0xBB 0xBF,则是UTF-8。如果没有这三个东西,那么就是ANSI,使用操作系统的默认语言编码来解释。
Unicode的好处就是,不论你的TXT放到什么语言版本的Windows上,都能正常显示。而ANSI编码则不能。(UTF-8的好处是在网络环境下,比较节约流量,毕竟网络里英文的数据还是最多的)
举例:
同样一段中文文本(可以插入一些英文),保存成ANSI/Unicode/UTF-8,三个文件。
修改windows的默认语言为日语之类的(WIN7的改法是:控制面板-时钟、语言和区域-更改显示语言-区域和语言-管理-非unicode程序语言-更改区域设置/WNIXP改法是:控制面板-区域和语言选项-非unicode程序语言)。
修改完要求重启,重启以后,再打开这三个文件,ANSI的编码全乱了,其余两个都正常显示,这就是UNICODE的作用。
另外,为什么记事本、开始菜单什么的还是正确的中文呢?明明我已经改了默认语言了?因为它们的程序编码也是unicode的。
要把txt发给国外的朋友或者用在非中文的操作系统/软件里,那么你的编码最好选择unicode
Unicode里有几种方式:
UTF-16BE/LE:UTF-16就是Windows模式的编码模式(Windows里说的Unicode一般都是指这种编码),用2个字节表示任意字符,注意:英文字符也占2个字节(变态不?),这种编码可以表示65536个字符,至于LE和BE,就是一个数值在内存/磁盘上的保存方式,比如一个编码0x8182,在磁盘上应该是0x81 0x82呢?还是0x82 0x81呢?就是高位是最先保存还是最后保存的问题,前者为BE,后者为LE。
UTF-8:UTF-8则是网页比较流行的一种格式:用一个字节表示英文字符,用3个字节表示汉字,准确的说,UTF-8是用二进制编码的前缀,如果某个UTF-8的编码的第一个字节的最高二进制位是0,则这个编码占1字节,如果是110,则占2字节,如果是1110,则占3字节……
好了,说了这么,再来研究Windows的记事本。
Windows早期(至少是95年以前的事情了)是ANSI字符集的,也就是说一个中文文本,在Windows简体中文版显示的是中文,到Windows日文版显示的就不知道是什么东西了。
后来,Windows支持了Unicode,但当时大部分软件都是用ANSI编码的,unicode还不流行,怎么办?Windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是unicode的时候,就用默认语言编码解释。(在区域和语言选项里可以改默认语言)
这个默认语言,在不同Windows语言版本里是不同的,在简体中文版里,是GBK,在繁体中文版里,是BIG5,在日文版里是JIS
而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本也不甘心这样,所以它要支持Unicode,但是有一个问题,一段二进制编码,如何确定它是GBK还是BIG5还是UTF-16/UTF-8?记事本的做法是在TXT文件的最前面保存一个标签,如果记事本打开一个TXT,发现这个标签,就说明是unicode。标签叫BOM,如果是0xFF 0xFE,是UTF16LE,如果是0xFE 0xFF则UTF16BE,如果是0xEF 0xBB 0xBF,则是UTF-8。如果没有这三个东西,那么就是ANSI,使用操作系统的默认语言编码来解释。
Unicode的好处就是,不论你的TXT放到什么语言版本的Windows上,都能正常显示。而ANSI编码则不能。(UTF-8的好处是在网络环境下,比较节约流量,毕竟网络里英文的数据还是最多的)
举例:
同样一段中文文本(可以插入一些英文),保存成ANSI/Unicode/UTF-8,三个文件。
修改windows的默认语言为日语之类的(WIN7的改法是:控制面板-时钟、语言和区域-更改显示语言-区域和语言-管理-非unicode程序语言-更改区域设置/WNIXP改法是:控制面板-区域和语言选项-非unicode程序语言)。
修改完要求重启,重启以后,再打开这三个文件,ANSI的编码全乱了,其余两个都正常显示,这就是UNICODE的作用。
另外,为什么记事本、开始菜单什么的还是正确的中文呢?明明我已经改了默认语言了?因为它们的程序编码也是unicode的。
要把txt发给国外的朋友或者用在非中文的操作系统/软件里,那么你的编码最好选择unicode
ASCII是古老的编码,那个时候还不区分字符集和编码,基本可以看作合二为一的东西。
Unicode严格来说是字符集,可以有多种编码。
UTF-8是一种Unicode的编码。
兼容性最好的,我记得好像是UTF-8不带BOM头。
注: 字符集(char set)就是字符的集合,收录了一定数量的字符。每个字符有对应的ID值,叫码点(code point)。实际存储的时候,不一定是直接存储字符串的码点(比如,为了节约空间),要进行转换。这个转换规则就是编码。
Unicode严格来说是字符集,可以有多种编码。
UTF-8是一种Unicode的编码。
兼容性最好的,我记得好像是UTF-8不带BOM头。
注: 字符集(char set)就是字符的集合,收录了一定数量的字符。每个字符有对应的ID值,叫码点(code point)。实际存储的时候,不一定是直接存储字符串的码点(比如,为了节约空间),要进行转换。这个转换规则就是编码。
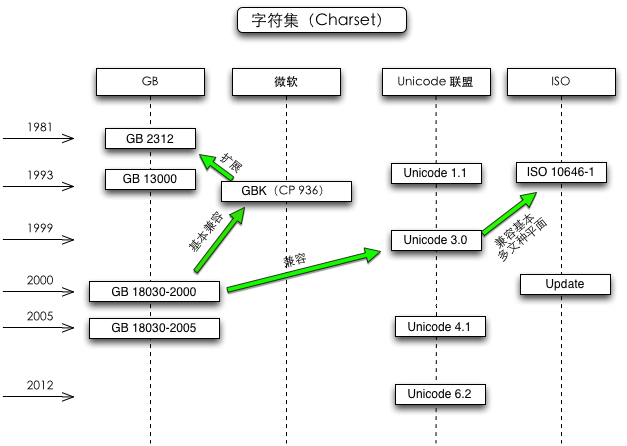
发布过编码规范的组织有 GB、微软、Unicode 联盟和 ISO 等,互相之间有的兼容,有的不兼容。
GB 是国标,中国的一个发布编码规范的机构,可以忽略掉,通用性太差了。
微软在 GB2312 的基础上扩展了 GBK,也可以忽略掉。
UTF-8(一种编码方式) 是 Unicode(一种标准) 的实现方式。记事本把 Unicode 和 UTF-8 并列,我不太懂它什么意思。
ANSI 并不是确定的一种编码,在简体中文操作系统指的是 GB2312,在繁体操作系统指的是 BIG5。
一句话,最好用 UTF-8。
多说一句:不要使用 Windows 自带的记事本!说记事本是垃圾,一点不为过。
GB 是国标,中国的一个发布编码规范的机构,可以忽略掉,通用性太差了。
微软在 GB2312 的基础上扩展了 GBK,也可以忽略掉。
UTF-8(一种编码方式) 是 Unicode(一种标准) 的实现方式。记事本把 Unicode 和 UTF-8 并列,我不太懂它什么意思。
ANSI 并不是确定的一种编码,在简体中文操作系统指的是 GB2312,在繁体操作系统指的是 BIG5。
一句话,最好用 UTF-8。
多说一句:不要使用 Windows 自带的记事本!说记事本是垃圾,一点不为过。
基本的问题是:非英语字符需要扩展 只面向英文的ASCii编码。
ANSI:泛指最早每种国家语言各自实现的编码方式,各个编码互相之间不兼容,比较省空间。
Unicode:一套抽象的兼容所有常用语言的编码方式,但是不适合计算机系统直接存储。
UTF-8:一种将unicode转换成适合计算机存储的方式,
相对其他的UTF-xx省空间,同时又可以和ASCII混用,结构相对复杂,底层处理相对慢。
UTF-16,UTF-32:另外的unicode存储编码,结构简单,不能和ASCII混用。
BOM:一种为了跨平台设计的文件起始标记,但很多程序没去处理这个,用了BOM反而常造成问题。
ANSI:泛指最早每种国家语言各自实现的编码方式,各个编码互相之间不兼容,比较省空间。
Unicode:一套抽象的兼容所有常用语言的编码方式,但是不适合计算机系统直接存储。
UTF-8:一种将unicode转换成适合计算机存储的方式,
相对其他的UTF-xx省空间,同时又可以和ASCII混用,结构相对复杂,底层处理相对慢。
UTF-16,UTF-32:另外的unicode存储编码,结构简单,不能和ASCII混用。
BOM:一种为了跨平台设计的文件起始标记,但很多程序没去处理这个,用了BOM反而常造成问题。
作者:蓝色鼓点
链接:https://www.zhihu.com/question/20650946/answer/15755457
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/20650946/answer/15755457
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
1.ANSI 就是ASCII编码。一个英文字符占一个字符
2.GB2312 是国内利用ASCII控制字符(即码值超过127)的两个字符形成一个汉字的原理。在DOS时代和windows 3.1时代用的就是这个方案,必须要外挂系统来解决显示问题。 同时代台湾搞一个BIG5编码也是相同原理,但是码值有冲突,所以那个时代txt 乱码是很头痛问题。 一个汉字相当于两个字符。但是这个格式用得还是很多。网上txt 中文小说几乎都是这个格式,还有歌词文件 lrc也是这个格式。后来为兼容繁体字,后推出一个GBK 大字集。
3. 国标组织为了解决世界各国的宽字符编码不统一的问题,搞出一UNICODE编码。把世界常用的语言的字符编一编码采用两个字符。世界约有几万字符(主要中文吃了一片),因此不同国家用不同代码区(code page 区别)(无论英文,汉字,泰文等)均是如此。 windows是内核采用了UNICODE编码。 但是在应用程序这一级为了兼容老的程序还有一套API,留给原来的应用程序来用。
4.到了Linux 和Mac OS X, 内核的编码采用是UTF-8,宽字符如汉字,采用的UTF-8编码。这个主要是针对网络传输的,从名字就可以看出来,UCS Transfer For .这个编码的特点除了统一编码外,还有的码值是变长,即一个字符可以由1-4字符表示,英文就与ASCII对应,汉字最短是两个字符,最长是四个字符,这个可以把传输字符量减到最小。
UTF8 与UNICODE没有规律的转换关系,两者编码是有冲突的。
--------------------------------------------
跨平台开发者要碰到一些问题: 在windows写的汉字,比如在程序中汉字注释(无论是UNICODE,还是GB2312)在LINUX下UTF8显示均是乱码。反过来也是一样。
当然有一些windows工具如UltraEdit 能直接识别,那是应用程序自己作了转换。
至于说哪种格式通用,没有定例,完全看应用程序的要求。我举几个常见例子。
1. 歌词文件 lrc,从我看的研究来看,哪个平台都是采用ANSI + GBK编码的。你随便从QQ音乐下载几个歌词就知道了。现在从网上下的小说txt ,基于是GBK格式的。
2.java内码指定是UNICODE编码,所以你在哪一个平台的Eclipse里输入的汉字均采用UNICODE编码,这样在Mac OS X 你可以发现在Eclipse写的汉字,用XCode 打开就乱码。
3. XML这一些格式,里面要求是UTF-8,你可以看第一句就注明是UTF-8格式。
2.GB2312 是国内利用ASCII控制字符(即码值超过127)的两个字符形成一个汉字的原理。在DOS时代和windows 3.1时代用的就是这个方案,必须要外挂系统来解决显示问题。 同时代台湾搞一个BIG5编码也是相同原理,但是码值有冲突,所以那个时代txt 乱码是很头痛问题。 一个汉字相当于两个字符。但是这个格式用得还是很多。网上txt 中文小说几乎都是这个格式,还有歌词文件 lrc也是这个格式。后来为兼容繁体字,后推出一个GBK 大字集。
3. 国标组织为了解决世界各国的宽字符编码不统一的问题,搞出一UNICODE编码。把世界常用的语言的字符编一编码采用两个字符。世界约有几万字符(主要中文吃了一片),因此不同国家用不同代码区(code page 区别)(无论英文,汉字,泰文等)均是如此。 windows是内核采用了UNICODE编码。 但是在应用程序这一级为了兼容老的程序还有一套API,留给原来的应用程序来用。
4.到了Linux 和Mac OS X, 内核的编码采用是UTF-8,宽字符如汉字,采用的UTF-8编码。这个主要是针对网络传输的,从名字就可以看出来,UCS Transfer For .这个编码的特点除了统一编码外,还有的码值是变长,即一个字符可以由1-4字符表示,英文就与ASCII对应,汉字最短是两个字符,最长是四个字符,这个可以把传输字符量减到最小。
UTF8 与UNICODE没有规律的转换关系,两者编码是有冲突的。
--------------------------------------------
跨平台开发者要碰到一些问题: 在windows写的汉字,比如在程序中汉字注释(无论是UNICODE,还是GB2312)在LINUX下UTF8显示均是乱码。反过来也是一样。
当然有一些windows工具如UltraEdit 能直接识别,那是应用程序自己作了转换。
至于说哪种格式通用,没有定例,完全看应用程序的要求。我举几个常见例子。
1. 歌词文件 lrc,从我看的研究来看,哪个平台都是采用ANSI + GBK编码的。你随便从QQ音乐下载几个歌词就知道了。现在从网上下的小说txt ,基于是GBK格式的。
2.java内码指定是UNICODE编码,所以你在哪一个平台的Eclipse里输入的汉字均采用UNICODE编码,这样在Mac OS X 你可以发现在Eclipse写的汉字,用XCode 打开就乱码。
3. XML这一些格式,里面要求是UTF-8,你可以看第一句就注明是UTF-8格式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号