HTTP的实体
一:HTTP的报文格式
报文结构图:
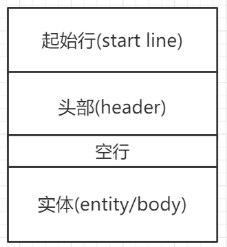
HTTP的报文结构是由三大部分组成的:
1.起始行(start line): 描述请求或响应的基本信息。
2.头部字段集合(header): 使用key-value的形式更详细的说明报文。
3.消息正文(entity): 实际传输的数据,不一定是纯文本的,可以是图片、视频等二进制文件。
二:HTTP数据实体
概述
由上图我们可以看出HTTP报文由header + body组成,让我们来了解一下 body 中会有一些什么内容呢。
数据类型与编码
HTTP协议是应用层协议,在数据传送到客户端之后,还需要告诉上层应用这是什么数据才行,所以HTTP使用 MIME type 和 Encoding type来识别 body 的类型。
HTTP协议则采用了MIME(多用途互联网邮件扩展)的一部分用来标记 body 的数据类型,以下是几个常遇到的数据类别:
1.text: 文本格式的可读数据,例如text/html、text/css等
2.image: 图像文件,例如image/gif、image/jpeg等
3.audio: 音频和视频数据 例如audio/mepg、video/mp4等
4.application: 数据格式不固定,可能是文本也可能是二进制,由上层应用决定
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
仅仅有 MIMI type 还不够,HTTP在传输时为了节约带宽,会对数据进行压缩,那么此时就需要一个 Encoding type(编码类型) 来告诉浏览器数据用的是什么编码,这样才能正确解压缩,还原出原始的数据,以下是三个常遇到的编码类型:
1.gzip:GNU zip压缩格式,也是互联网最流行的压缩格式
2.deflate:zlib压缩格式
3.br:专门为HTTP优化的新压缩法
accept-encoding: gzip, deflate, br
数据类型使用的头字段
HTTP协议定义了两个Accept请求头字段和两个Content实体头字段,用于客户端和服务器进行内容协商,客户端用Accept头告诉服务器希望接收怎样的数据,服务端用Content头告诉客户端实际发送了怎样的数据。
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
告诉服务器浏览器能够看懂HTML、XML的文本和avif、webp、apng的图片,请给我这几类格式的数据。
相应的服务器会在响应报文中用头字段Content-type告诉数据实体的真实类型。
content-type: text/html; charset=utf-8
使用Accept-encoding标记客户端支持的压缩格式,服务器选择一种格式来压缩数据,实际使用的压缩格式放在content-type头字段中。
content-encoding: gzip
语言类型与编码
语言类型指的是人类使用的自然语言,比如中文,英文,日语等。
编码指的是计算机处理的字符集,比如ASCII、GBK、UTF-8、Unicode等。
语言类型采用Accept-Language头字段来标记客户端可理解的自然语言,使用Accept-Charset头字段标记客户端可理解的字符集
accept-language: zh-CN,zh;q=0.9
accept-charset: gbk,utf-8
服务器使用Content-Language头字段告诉客户端实体数据使用的实际语言类型,Content-type头字段实际使用的字符集
content-Language: zh-CN
content-type: text/html; charset=utf-8
在以上的代码中,我们会看到出现的 q 参数,那么这个 q 表示权重来设定优先级,最大的值是1,最小的值是0.01,默认为1。服务器收到请求头后会计算权重,根据实际情况来优先输出某种格式。
三:传输大文件
概述
让我们来学习一下当需要传输的文件达到了几G、几十G的时候,如果一次性发送的话不仅会造成网络被长时间占用,HTTP协议是采用哪些方法来解决大文件的传输的。
1.数据压缩
在上面介绍的浏览器支持的压缩格式列表,如 gzip、deflate、br等,服务器选择其中的一种压缩算法,对数据进行压缩,然后再将压缩后的数据发送给浏览器,但是这个方法有缺点就是只对文本文件有较好的压缩率,而图片、音频等多媒体数据已经是高度压缩的,再用 gzip处理也不会起作用。
2.分块传输
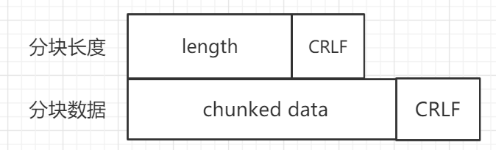
将大文件拆解成多个小块,将这些小块分批的发送给浏览器,浏览器收到后再组装复原,这样网络也不会被大文件长时间占用,节省了带宽资源。在响应报文中使用头字段Transfer-Encoding: chunked来表示,意思是报文中的 body 部分不是一次性发送过来的,而是分成了许多的块(chunk)逐个发送。数据块的格式:
每个分块包含两个部分,长度头和数据块,长度头是以 CRLF 结尾的明文,用16进制数字表示长度,数据块跟在长度头的后面,也用 CRLF 结尾。
3.范围请求
允许客户端在请求头使用专用字段来表示只获取文件的一部分,服务器在响应头中使用头字段 Accept-Ranges: bytes告知客户端它支持范围请求。
4.多段数据
在Ranges头字段里使用多个"x-y",一次性获取多个片段数据。
四:HTTP的连接管理
短链接
在HTTP1.0的时候,采用简单的请求-应答的通信方式,底层数据传输基于TCP/IP,每次发送请求前都需要先与服务器建立连接,收到响应报文后会立即关闭连接。整个会话过程很短暂,不会与服务器保持长时间的连接,所以称为短链接。
在TCP建立连接要有三次握手,发送三个数据包,需要1个RRT;关闭连接要有四次挥手,发送4个数据包,需要2个RRT。而HTTP一次简单的请求-应答需要4个包,2各个RRT。
长连接
顾名思义,长连接指的是客户端与服务器长时间连接,只需要在第一次请求时进行TCP三次握手建立连接,之后的请求都不需要再进行连接,直到四次挥手关闭连接。在HTTP1.1之后就默认使用长连接。但是当连接长时间不关闭时,会占用大量服务器资源,导致服务器无法为真正需要的用户提供服务。
如何降低长连接对服务器的负面影响?
设置"keepalive_timeout"空闲连接时间和"keepalive_requests"最多发送请求。
队头阻塞
由于HTTP规定报文必须是一发一收的,就形成了一个先进先出的队列,当队首请求处理太慢时,那么队列中的所有请求都跟着一起等待。
性能优化
1.并发连接:同时多一个域名发起多个长连接,浏览器一般都限制并发数量为6~8个。
2.域名分片:多个域名对应同一个服务器。
五:重定向和跳转
概述
跳转:
浏览器的使用者主动发起请求,跳转到另一个新的页面。
重定向:
由服务器发起的,浏览器使用者无法控制的被称为重定向。
响应字段"Location"必须出现在响应报文里,但只有配合301/302状态码才有意义,它标记了服务器要求重定向的 URI。
重定向状态码:
301:永久重定向,原URI以及永久性不存在,之后的所以请求都需要新的URI
302:临时重定向,原URI处于临时维护状态,例如常见的网站进行维护
重定向的过程
1.浏览器发送第一次请求,从得到返回301/302状态码
2.浏览器收到301/302报文,会检查响应头里有没有"Location",如果有,就从字段提取出URI,发出新的HTTP请求,相当于自动帮我们点击了链接。例如Location:/index.html,要求浏览器跳转到index.html页面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号