部署alertmanager-告警规则
5. 部署alertmanager
5.1. 准备镜像
[root@hdss7-200 ~]# docker pull docker.io/prom/alertmanager:v0.14.0
[root@hdss7-200 ~]# docker image tag prom/alertmanager:v0.14.0 harbor.od.com/public/alertmanager:v0.14.0
[root@hdss7-200 ~]# docker push harbor.od.com/public/alertmanager:v0.14.0
# 新版本容器启动后可能会报错:
# couldn't deduce an advertise address: no private IP found, explicit advertise addr not provided
5.2. 准备资源配置清单
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'linux_hy_1992@163.com'
smtp_auth_username: 'linux_hy_1992@163.com'
smtp_auth_password: 'linux1992'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '1659775014@qq.com'
send_resolved: true
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com/public/alertmanager:v0.14.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
# Prometheus调用alert采用service name。不走ingress域名
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 9093
5.3. 应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/configmap.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/deployment.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/service.yaml
5.4. 添加告警规则
[root@hdss7-200 ~]# cat /data/nfs-volume/prometheus/etc/rules.yml # 配置中prometheus目录下
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
[root@hdss7-200 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml # 在末尾追加,关联告警规则
......
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"
# 重载配置文件,即reload
[root@hdss7-21 ~]# kubectl exec prometheus-78f57bbb58-6tcmq -it -n kube-system -- kill -HUP 1
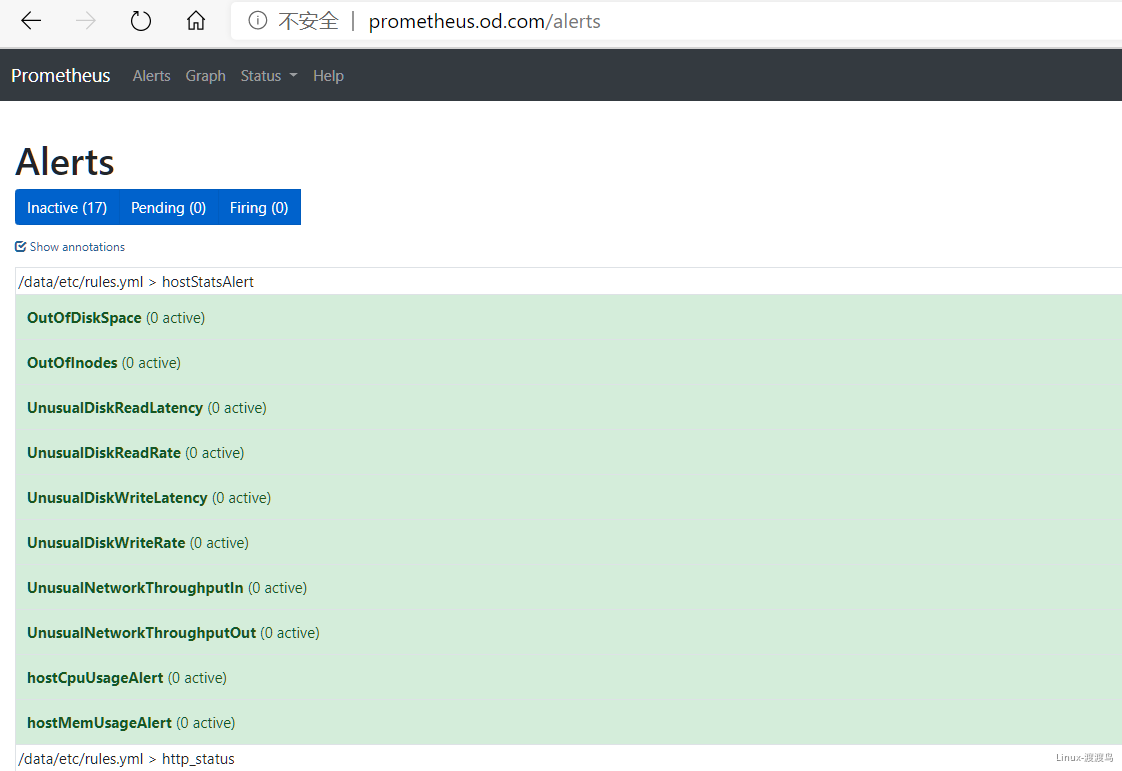
6. Prometheus的使用
6.1. Prometheus配置文件解析
# 官方文档: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
[root@hdss7-200 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s # 数据抓取周期,默认1m
evaluation_interval: 15s # 估算规则周期,默认1m
scrape_configs: # 抓取指标的方式,一个job就是一类指标的获取方式
- job_name: 'etcd' # 指定etcd的指标获取方式,没指定scrape_interval会使用全局配置
tls_config:
ca_file: /data/etc/ca.pem
cert_file: /data/etc/client.pem
key_file: /data/etc/client-key.pem
scheme: https # 默认是http方式获取
static_configs:
- targets:
- '10.4.7.12:2379'
- '10.4.7.21:2379'
- '10.4.7.22:2379'
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints # 目标资源类型,支持node、endpoints、pod、service、ingress等
scheme: https # tls,bearer_token_file都是与apiserver通信时使用
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: # 对目标标签修改时使用
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep # action支持:
# keep,drop,replace,labelmap,labelkeep,labeldrop,hashmod
regex: default;kubernetes;https
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:10255
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:4194
- job_name: 'kubernetes-kube-state'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]
regex: .*true.*
action: keep
- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']
regex: 'node-exporter;(.*)'
action: replace
target_label: nodename
- job_name: 'blackbox_http_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: http
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+);(.+)
replacement: $1:$2$3
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox_tcp_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [tcp_connect]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: tcp
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'traefik'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: keep
regex: traefik
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
alerting: # Alertmanager配置
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files: # 引用外部的告警或者监控规则,类似于include
- "/data/etc/rules.yml"
6.2. Pod接入Exporter
当前实验部署的是通用的Exporter,其中Kube-state-metrics是通过Kubernetes API采集信息,Node-exporter用于收集主机信息,这两项与Pod无关,部署完毕后直接使用即可。
根据Prometheus配置文件,可以看出Pod监控信息获取是通过标签(注释)选择器来实现的,给资源添加对应的标签或者注释来实现数据的监控。
6.2.1. Traefik接入
# 在traefik的daemonset.yaml的spec.template.metadata 加入注释,然后重启Pod
annotations:
prometheus_io_scheme: traefik
prometheus_io_path: /metrics
prometheus_io_port: "8080"
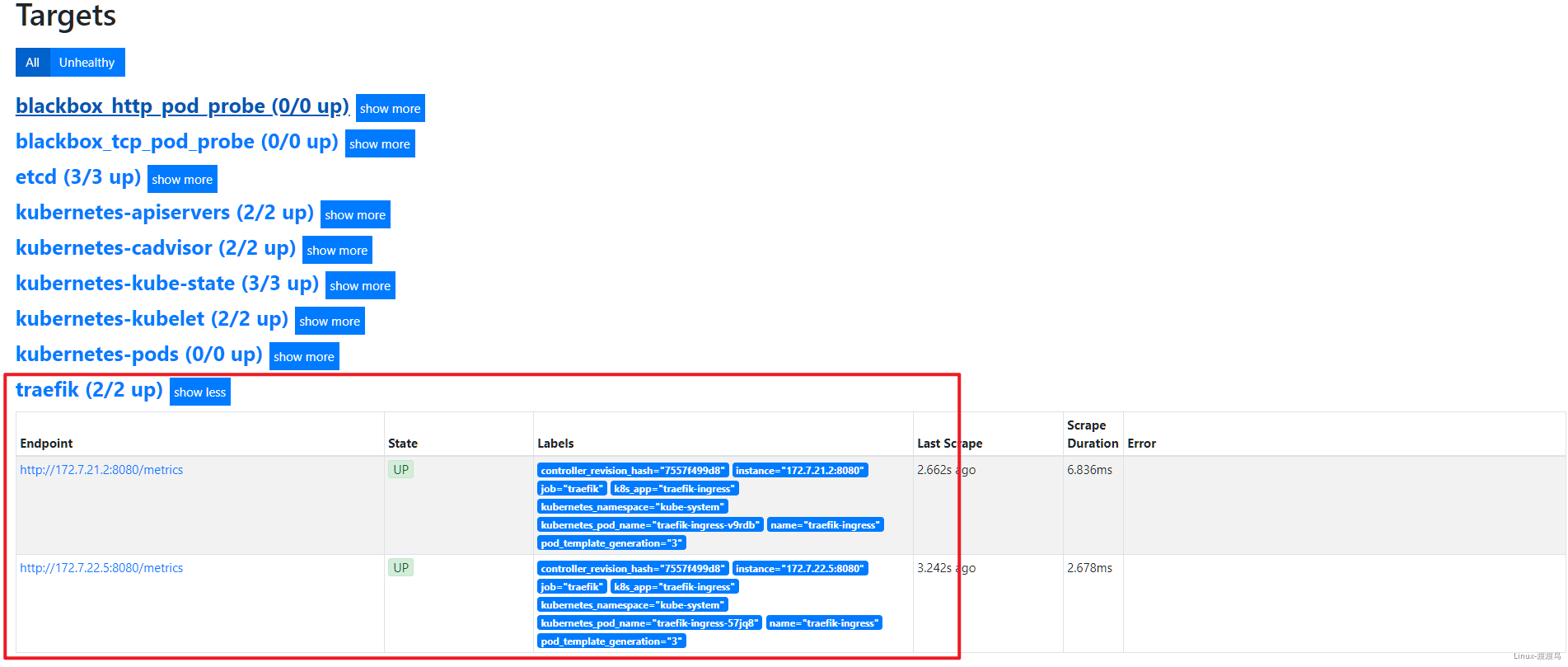
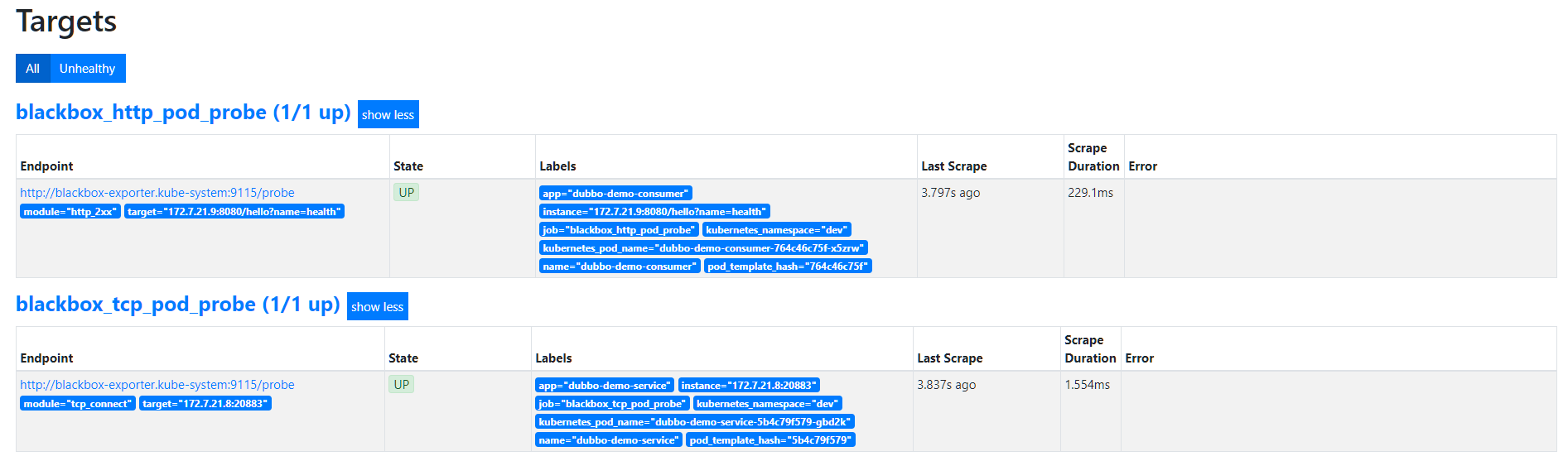
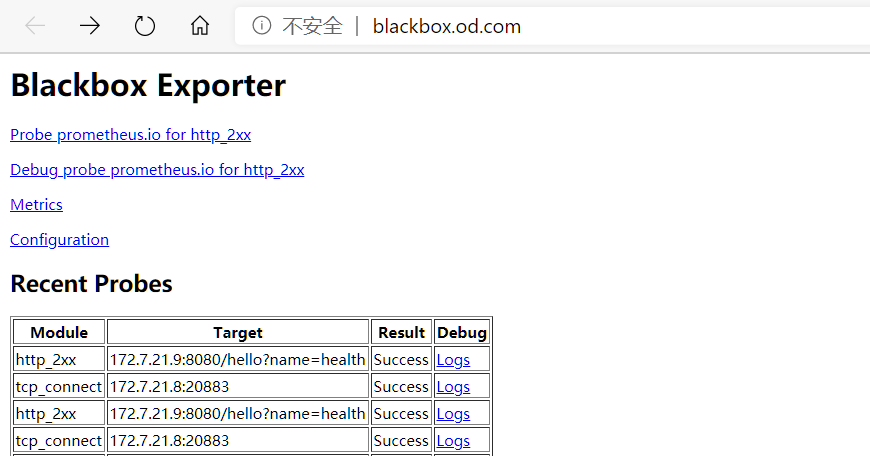
6.2.2. 接入Blackbox监控
# 在对应pod的注释中添加,以下分别是TCP探测和HTTP探测,Prometheus中没有定义其它协议的探测
annotations:
blackbox_port: "20880"
blackbox_scheme: tcp
annotations:
blackbox_port: "8080"
blackbox_scheme: http
blackbox_path: /hello?name=health
6.2.3. Pod接入监控
# 在对应pod的注释中添加,该信息是jmx_javaagent-0.3.1.jar收集的,开的端口是12346。true是字符串!
annotations:
prometheus_io_scrape: "true"
prometheus_io_port: "12346"
prometheus_io_path: /
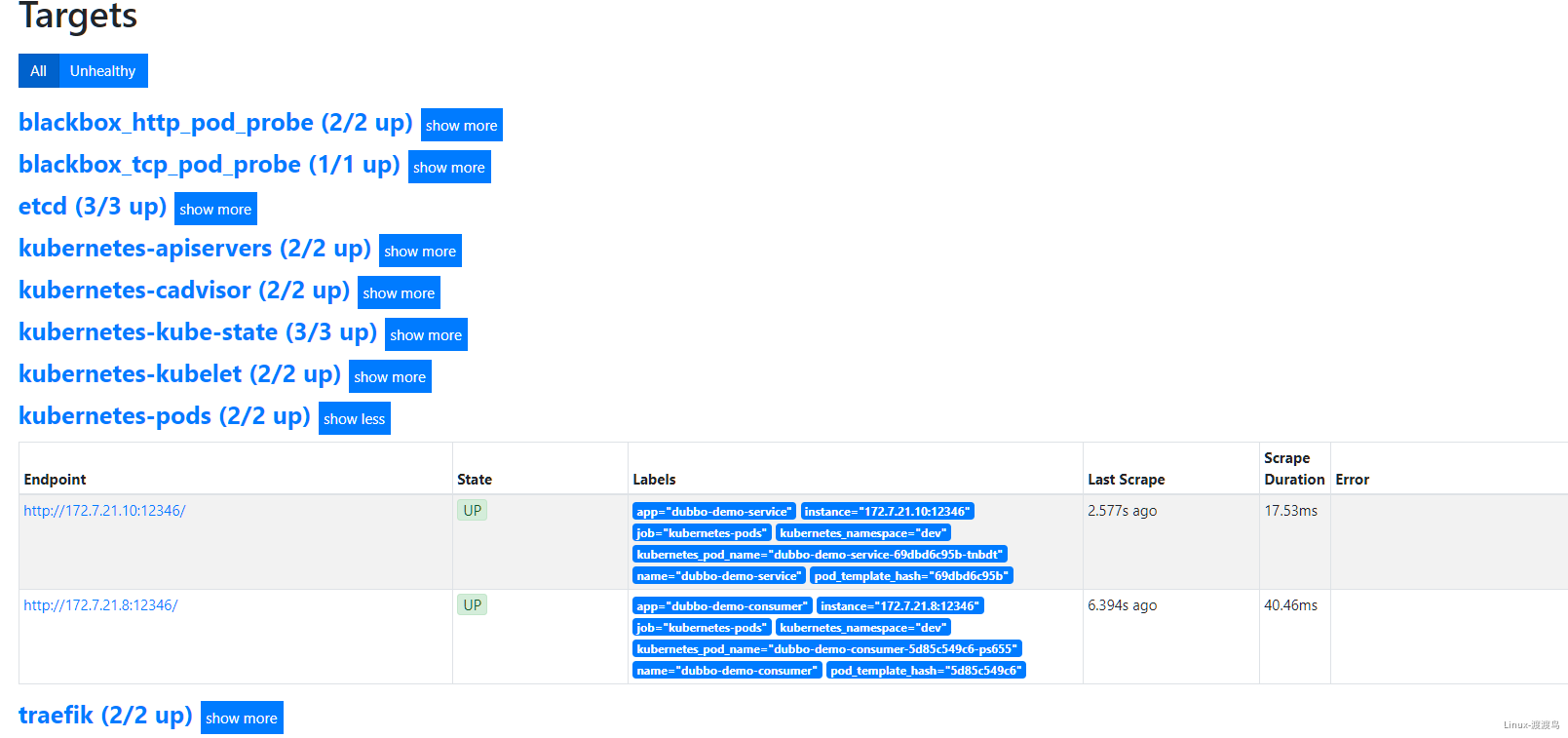
6.3. 测试Alertmanager
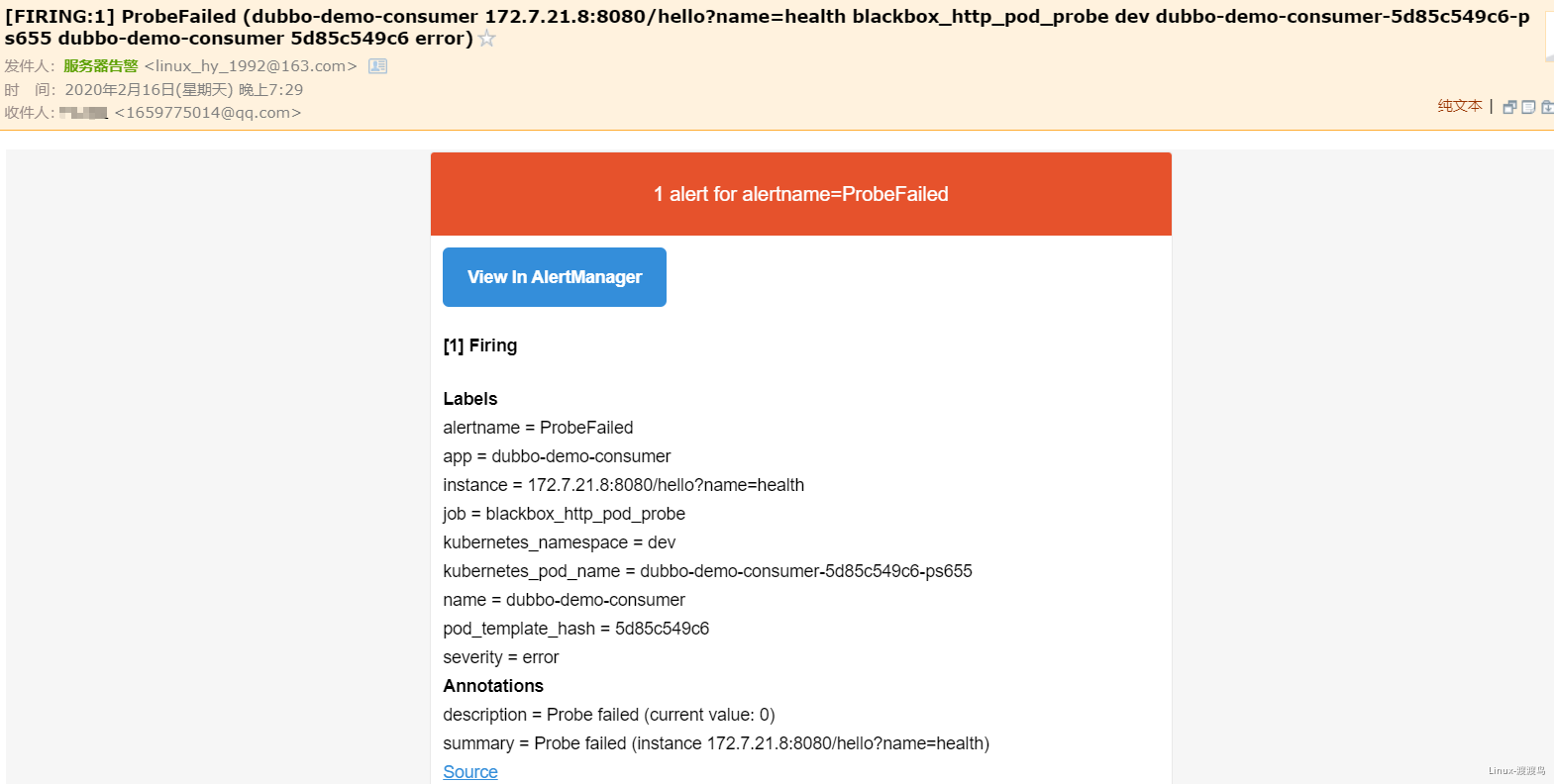
- 当停掉dubbo-demo-service的Pod后,blackbox的HTTP会探测失败,然后触发告警:
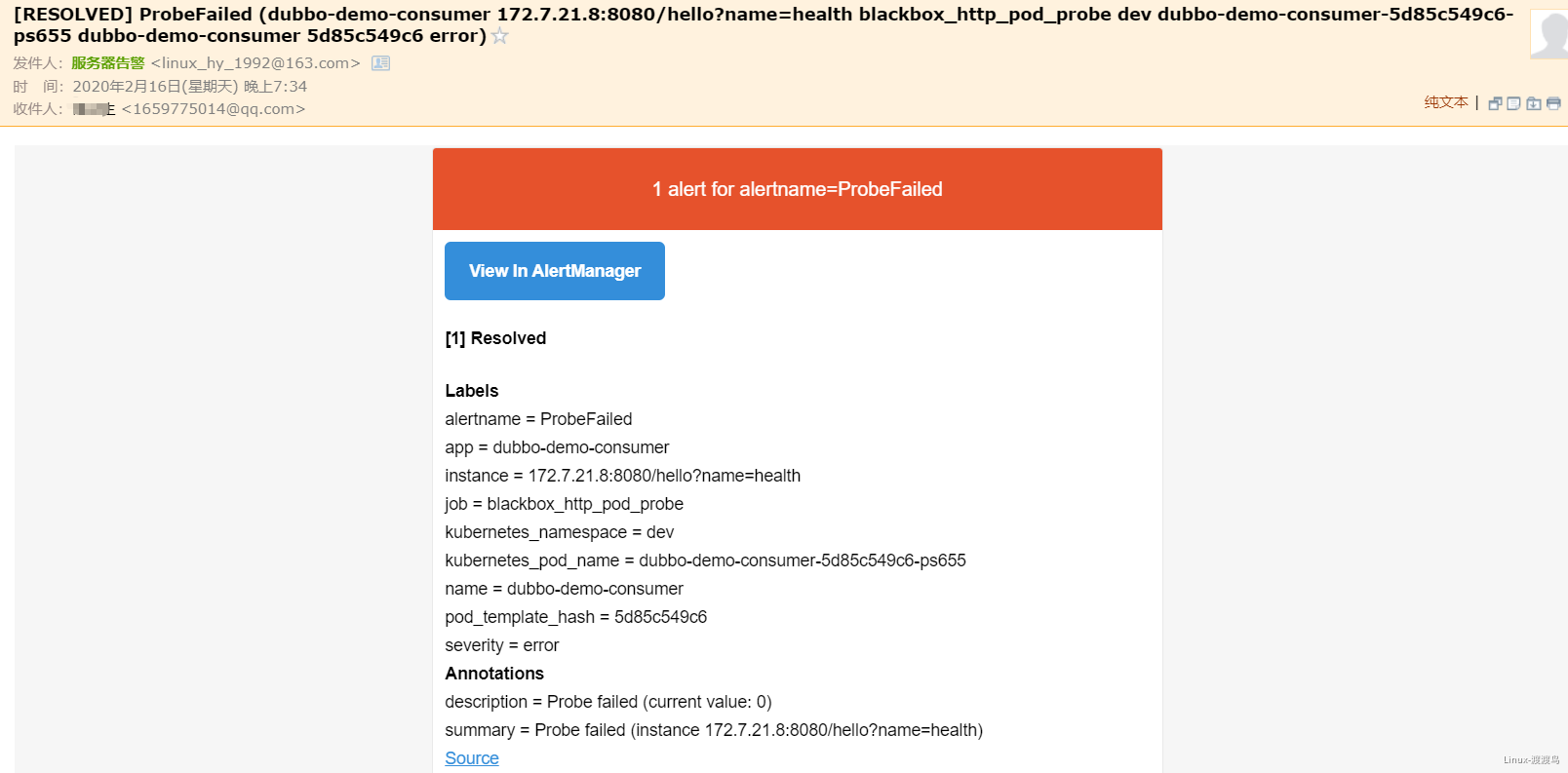
- 在此启动dubbo-demo-service的Pod后,告警恢复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号