
spring事务管理器设计思想(二)
对于第二个问题,涉及到事务的传播级别,定义如下:
PROPAGATION_REQUIRED-- 如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS-- 如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY-- 如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
在开启事务之前,正常情况下需要做两个事情
一:获取当前事务上下文信息
二:获取将要开启事务的传播属性
根据以上两个信息,来判断程序的处理方式,具体方式如下:
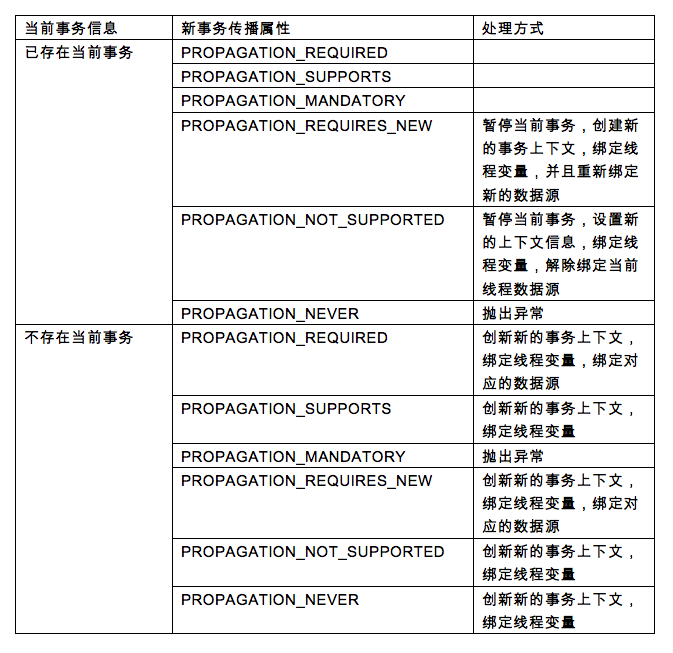
而处理流程则是如下:

其中上图标中英文简称对应的事务传播属性如下:
RE: PROPAGATION_REQUIRED-- 如果当前没有事务,就新建一个事务。这是最常见的选择。
SPT PROPAGATION_SUPPORTS-- 如果当前没有事务,就以非事务方式执行。
MA: PROPAGATION_MANDATORY-- 如果当前没有事务,就抛出异常。
RE_NEW: PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
NOT_SPT: PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
NEVER: PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
通过上面发现,只有新创建资源的时候,才会开启事务,在其他的情况下,只需要返回事务状态信息就可以了。其实这个状态信息,就是事务的上下文信息。
事务上下文
通过上面的分析,每次启动事务的时候,都会判断当前是否存在事务,要么抛出异常,否则都会创新事务上下文,但是对于数据源的处理方式则是不一样的,这个要根据当前事务传播属性和新的事务传播属性共同决定。
事务上下文信息到底是什么,这个完全是可以自定义的,在spring中,主要是表现为TransactionStatus,也就是事务状态信息。里面保存了事务相关的信息,
//事务对象信息,使用普通数据源的话,是DataSourceTransactionObject对象,保存//了事务对应的连接信息 private final Object transaction; //是否是新开启的事务信息,只有调用了开启事务的方法,这个才为true private final boolean newTransaction; //这个是事务同步器,不是事务要关心的,spring在事务提交之前或者之后座的hook private final boolean newSynchronization; //是否是只读事务 private final boolean readOnly; //日志debug信息,完全没有放在这里 private final boolean debug; //挂起的事务信息,如果没有,则为空 private final Object suspendedResources;
通过事务状态信息,就可以完全知道当前事务的所有信息,包括事务的对应的数据源连接信息,是否是新创建的事务,是否是只读事务,以及之前挂起的事务信息。这些对事务管理器起来说,都是必须的信息。但是个人觉得也存在一些问题,首先spring这个事务状态信息有两个使用者,一个是spring本身事务管理器使用,另外一个是应用程序接口。对应用程序接口暴露出来的状态信息以及内部使用的事务上下文信息应该隔离出来,避免应用程序人为的修改了事务上下文的属性信息。当然,可以用过接口的方式进行避免,但是如果知道实现原理的话,完全可以通过强制转化为实现对象,从而破坏事务其他的信息导致程序异常。当然,正常情况下不太可能有人会如此无聊。
从上面的分析来看,spring的事务管理器(这里都特指DataSourceTransactionManager)主要的工作流程就是创建事务信息,绑定数据源,获取数据库连接,提交活回滚事务,释放数据库连接,解绑数据源。其实整个事务管理器做的事情无非就是这些。让应用者更关注业务逻辑,而不是复杂的事务管理。

DataSourceTransactionManager事务管理器本身实现了ResouceManager的功能,就是返回对应的其注册的datasrouce。这是一种一对一的映射关系,也就是说一个事务管理器只能注册一个数据源,不支持多数据源的管理。一旦事务管理器开启事务,就和具体的数据源绑定了,你只能通过其对应的数据源获取数据库连接。所以在事务上下文里面操作多个数据库,是不可能的。同时也只支持单一物理数据源,也就是说一个数据源只能返回同一个数据库连接,不支持在同一个事务里面通过同一个逻辑数据源跨越多个物理库操作。下面的操作想通过ProxyDataSource切换实际的数据源的方式无法实现的。
for(String dbName : dbNames){
DataSourceContextHolder.set(“dbName”);
doSomeThing();
DataSourceContextHolder.clear();
}
想要支持跨库的事务操作,可以通过以下几种方式操作:
1 使用JtaTransactionManager,通过jta服务提供商来实现跨库事务
2 改写ProxyDataSource,通过返回其自己实现的Connection来实现跨库的事务。简单的说,返回一个逻辑的Connection,这个connection本身持有多个物理connection
3 自己实现TransactionManager,可以注册多个资源管理器,自己对多个数据源进行管理。
事务上下文的扩展
正常情通过况下,事务上下文信息都是保存在内存之中,相当于只能够支持单个jvm。可以想象一下,假设事务管理器把事务上下文信息持久化,并且通过远程调用的方式,把事务上下文信息传递给另外一个jvm,通过这样的设计思想,可以支持跨jvm间的事务一致性,也就是我们所说的分布式系统的事务。当然,这只是一中简单的想法,具体的实现会相当复杂,需要考虑点也有很多。


