LoRA 微调参数调优流程
【总结】
train loss 快速降到接近 0,但 val loss 高 → rank 太大 → 过拟合
train loss 降不下去 → rank 太小或模块少 → 欠拟合
rank 太大会直接导致过拟合 --->「train loss → 0」
👉 LoRA 失去“低秩约束”,退化为 全参数微调的近似版
高 rank = 高自由度 → 能学到:样本级别噪声,prompt 偏置,token 位置偶然相关性,数据集中特有的模式(spurious correlation)
rank 小: 👉 强迫模型只学「最重要的方向」,
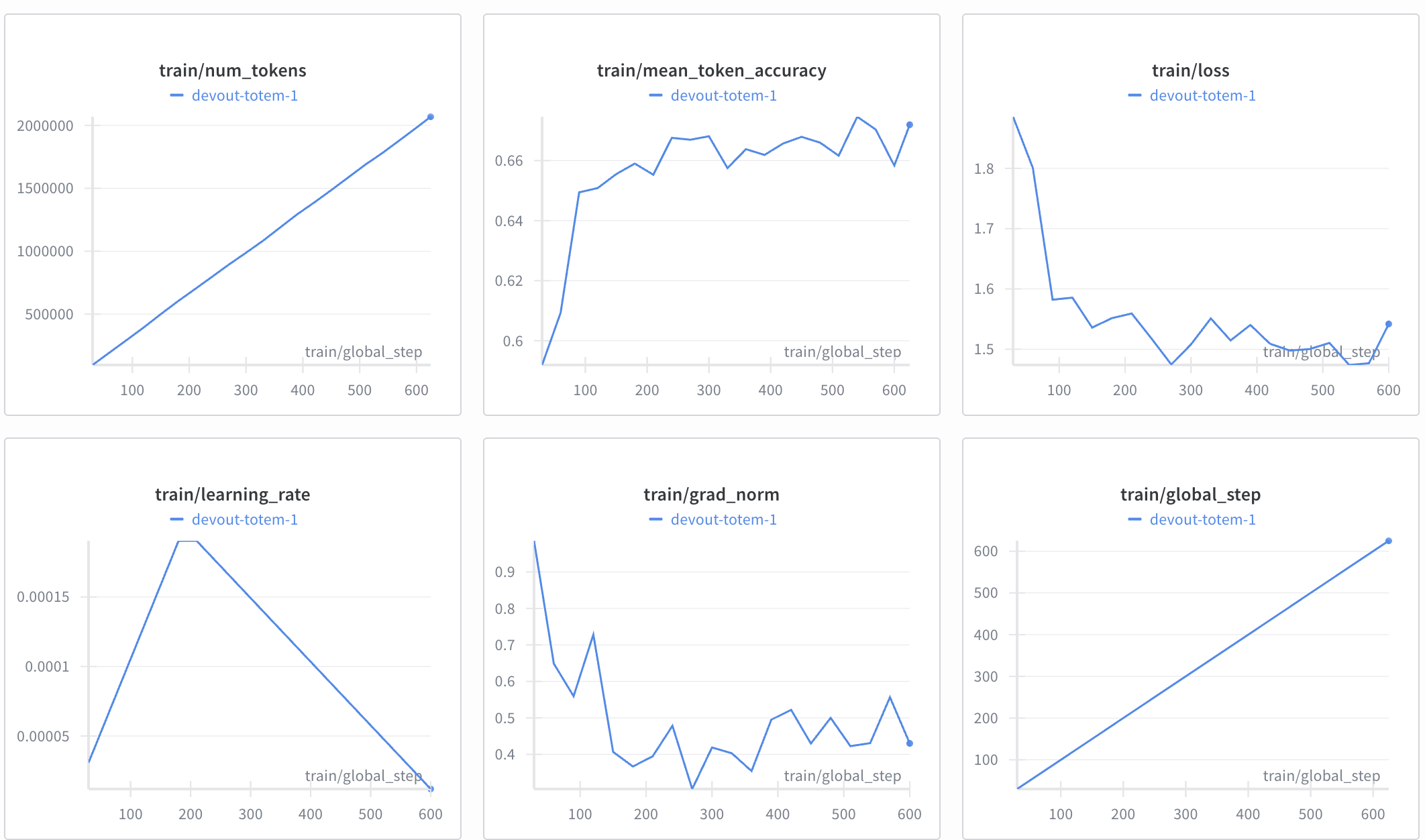
核心原则:一次只改一个变量,先确认最重要的容量参数(rank + target module)是否合理,再微调其他超参
在 LoRA 微调初始阶段,我们先用默认值设置 a、dropout、learning rate,先验证 rank 和 target module 的合理性。待训练曲线和验证表现正常后,再对学习
率、dropout 或 scaling 进行微调
一、准备阶段:评估任务 & 数据
-
评估任务复杂度
- 输出结构、语义歧义、分布偏移、决策边界等
- 例:客服意图分类 → 中等复杂
-
确定训练数据量
- 数据量 = 复杂度 × 期望泛化
- 检查数据质量:标注一致性、长尾覆盖、错别字、分布偏移
-
初步选择 LoRA 配置(默认保守策略)
- rank r:根据数据量与复杂度选中等值(如 8~16)
- target modules:核心 Q/V + 顶层 2~4 层 FFN
- a(LoRA scaling):默认 1.0 (初步选参,取默认值即可)
- dropout:默认 0.05~0.1(初步选参,取默认值即可)
- learning rate:默认较小,如 1e-4~5e-4(初步选参,取默认值即可)
目的:先有一个 安全可训练的起点,不会一上来就过拟合或梯度爆炸
二、训练观察阶段:小规模试验
-
运行短轮(1~3 epoch 或少量 step)观察指标
- 训练 loss:是否正常下降
- 验证 loss / 准确率:是否过拟合
- 是否有梯度异常、nan、loss 振荡
-
观察曲线判断 rank 是否合适
- train loss 快速降到接近 0,但 val loss 高 → rank 太大 → 过拟合
- train loss 降不下去 → rank 太小或模块少 → 欠拟合
-
观察模块选择效果
- 只选 Q/V → loss 收敛慢,val acc 不理想 → 可以增加顶层 FFN
- 全模块 → val acc 波动 → rank 或层数过多,需要控制
三、超参调优阶段
以 单变量调优 + 观察曲线 为主:
| 参数 | 调整原则 | 观察指标 |
|---|---|---|
| rank r | 数据少 → 8~12,数据多 → 16~32 | train/val loss 曲线过快下降或过慢 |
| target modules | 先核心模块 → 顶层 FFN → 全模块 | 收敛速度 vs 泛化能力 |
| a(scaling) | 1.0 左右 → 如果 loss 太小可增大 | 影响梯度规模,过大易发散 |
| dropout | 0.05~0.2 | 避免过拟合,观察 val loss 是否下降稳定 |
| lr | 默认 1e-4~5e-4 → 可尝试 ±2 倍 | loss 下降速度与稳定性 |
| batch size | 可根据 GPU 调整 | 小 batch 可缓解梯度噪声,大 batch 加快收敛 |
原则:一次只改一个参数,观察 loss/acc 曲线变化,再改下一个
四、迭代优化策略
-
先保证收敛
- train loss 正常下降,val loss 稳定
-
控制过拟合
- 调整 rank 或模块数量
- 增加 dropout
-
加速收敛
- 调整 learning rate
- 可调 a 或 lr scheduler
-
泛化测试
- 用时间切分验证集或新产品 / 新活动数据
- 观察是否过拟合历史话术
-
灰度上线
- 小比例用户先跑线上
- 收集真实日志 → 回流再训练
五、生产级经验总结
- 先保守:小 rank + 核心模块 + 默认超参
- 迭代:通过 loss/val acc 曲线逐步调整 rank / target modules → 再微调 lr/dropout/a
- 验证泛化:时间切分或新产品数据
- 上线回流:不断收集数据再迭代

 浙公网安备 33010602011771号
浙公网安备 33010602011771号