Lora微调- Rank 参数设置
明白,这个问题涉及 LoRA 的核心机制:低秩矩阵注入 + 参数量控制,面试官问就是想看你对 rank 和泛化的理解,而不仅仅是背公式。我们一步步拆开。
一、LoRA rank 的含义
LoRA 微调的本质是给原模型添加一个 低秩矩阵 ΔW:
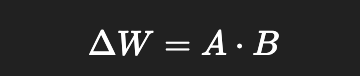
-
A: (output_dim × r)
-
B: (r × input_dim)
-
r = rank,控制 LoRA 学习能力的“容量”
-
r 越大 → ΔW 能表示的变化空间越大
-
r 越小 → ΔW 变化空间受限,只能学粗粒度调整
二、rank 太低 → 学不到细节
- 理解:低 rank 相当于你给模型的“自由度”太小
- 后果:模型只能做粗调
- 训练指标表现:
| 指标 | 典型表现 |
|---|---|
| train loss | 下降缓慢或达不到很低值 |
| val loss | 可能比 train 高,但变化幅度小 |
| 输出行为 | 只能学到大方向,细节(语法、风格、专业知识)不够 |
理解方式:
rank 太低就像画图只用 1-2 条线条,你只能勾出轮廓,细节画不出来。训练指标里 loss 下降慢、最终 loss 较高,就是“学不到细节”的信号。
三、rank 太高 → 容易记住训练集(过拟合)
- 理解:高 rank → ΔW 变化空间大 → LoRA 能把训练集内容“记死”
- 后果:loss 降得很低,但泛化差(测试集 / 新 prompt 上表现不好)
- 训练指标表现:
| 指标 | 典型表现 |
|---|---|
| train loss | 很低,趋近零 |
| val loss | 明显高于 train,gap 很大 |
| 输出行为 | 对训练集 prompt 准确但对新 prompt 错误或跑偏 |
理解方式:
rank 太高就像画图用全套彩笔,你可以把训练集每个细节画出来,但一遇到新场景就乱了。loss 曲线 train vs val 差距大就是典型过拟合信号。
四、从训练指标判断 rank 是否合适
- loss 曲线对比
- train loss 高 → rank 太低
- train loss 很低,但 val loss 高 → rank 太高 / 过拟合
- train & val loss 都稳定下降 → rank 合理
- 输出质量 / 泛化测试
-
构建小型验证集 / prompt set
-
输出行为:
- rank 太低 → 模型回答“模糊、概括性强”
- rank 太高 → 模型对训练 prompt 精准,但新 prompt 幻觉多 / 偏离风格
- 指标总结公式化(面试回答可用):

五、可用面试回答模板
“LoRA 的 rank 控制了微调自由度。
- rank 太低 → 参数量受限,模型只能学粗粒度调整,训练 loss 下降慢,输出粗略,学不到细节。
- rank 太高 → 参数量过大,容易记住训练集,train loss 很低,但 val loss 高,泛化差。
因此,我会通过观察 train/val loss 曲线和小型验证 prompt 集的输出行为来判断 rank 是否合适。”
rank太低
这个问题问得非常到位,而且你已经抓住了 LoRA 调参里最容易被忽略的一半:
👉 rank 太低不只是“loss 下不去”,验证阶段也会暴露出一整组非常典型的问题。
我按“本质 → 验证集现象 → 业务层面表现 → 面试话术”来讲。
一、先给一句总判断(面试可用)
rank 太低本质上是模型表达能力不足,在验证阶段表现为“整体提升有限、边界样本处理能力差、对复杂语义不稳定”。
二、rank 太低时,验证集常见的 5 类问题
1️⃣ 验证集准确率整体偏低(但 train / val 差距不大)
现象:
- train accuracy:比如 70%
- val accuracy:比如 68%
- 两者差距不大,但都不理想
解读:
- 不是过拟合
- 是模型“学不动”——典型 欠拟合
2️⃣ 对高混淆类别几乎没有改善
在意图 / action / phase 分类中很常见:
- 相似意图之间仍然频繁混淆
- LoRA 加与不加,混淆矩阵变化不明显
说明:
LoRA 没有足够自由度去拉开决策边界。
3️⃣ 对复杂 / 复合语义输入表现不稳定
验证集中一旦出现:
- 多意图句
- 长句
- 上下文依赖句
常见现象是:
- 输出随机
- 主意图能对,但细分类不准
这是 rank 不足最典型的“能力天花板”。
4️⃣ 对新表达方式泛化能力弱
你会看到:
- 标准话术还能勉强判断
- 换种说法(同义改写)就容易错
这说明:
模型没有学到抽象语义,只是“浅层匹配”。
5️⃣ 指标对训练轮数不敏感
再训练几轮:
- train loss 继续缓慢下降
- val 指标几乎不变
这是一个非常明确的欠拟合信号:
模型容量不足,而不是数据或训练策略问题。
三、和“rank 太高”的验证现象对比(帮你建立直觉)
| 情况 | 训练集 | 验证集 | 结论 |
|---|---|---|---|
| rank 太低 | 都不高 | 都不高 | 欠拟合 |
| rank 合理 | 稳步提升 | 同步提升 | 最优 |
| rank 太高 | 很高 | 明显下降 | 过拟合 |
四、你在面试中可以这样说(推荐版本)
“当 rank 设得过低时,除了训练 loss 下降缓慢,验证阶段通常会看到整体指标提升有限、对高混淆类别和复杂语义几乎没有改善,而且验证指标对训练轮数不敏感。这种情况下问题不在数据,而在 LoRA 的表达能力不足。”
这是非常成熟的工程判断。
五、一句话帮你记住
rank 太低 = 模型“想学,但学不会”。
如果你愿意,下一步我可以帮你做一个完整的 LoRA rank 调参流程图,告诉你什么时候该加 rank,什么时候该停,而不是靠感觉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号