LoRA微调-lora_alpha参数选择
目录
lora_alpha 用于调节 LoRA 低秩更新叠加到原模型上的强度,决定微调结果是“保守微调”还是“激进偏移”,其本质作用体现在 α / r 上。
lora_alpha本身没有独立意义,真正决定 LoRA 更新强度的是α / r。
α = 2r只是经验上的安全默认值,适合小 r、小数据、偏风格类任务,但并非通用最优。
lora_alpha / r才是真正有意义的量。
一、lora_alpha 在数学上到底干了什么
LoRA 实际生效的是这一项:
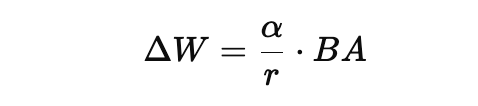
所以:
- 真正控制更新幅度的是
scale=α/r
换句话说
r→ 决定能学多少(容量)α / r→ 决定学到的东西有多“敢加”
这点非常关键。
三、什么时候 α = 2r 是合理的
以下场景下,它是安全且常见的选择:
| 条件 | 是否适合 |
|---|---|
| r ≤ 16 | ✅ |
| 样本量 < 5k | ✅ |
| 任务偏风格/对话/指令跟随 | ✅ |
| 只 LoRA attention / q,v | ✅ |
| 学习率 ≤ 2e-4 | ✅ |
在这些条件下:
scale = α / r = 2- 更新强度中等
- 不容易把基座模型“拽坏”
四、什么时候 不应该 用 α = 2r
1. r 很大(≥64)
例如:
- r = 64
- α = 128
- scale = 2
问题在于:
- 子空间已经很大
- 再用 scale=2,会让更新过猛
- 容易出现 loss 震荡、泛化变差
👉 此时更合理的是:
α ≈ r或- 固定
α / r ∈ [0.5, 1]
2. 数据噪声大 / 标签不干净
- 高 α 会放大错误梯度
- LoRA 很容易“学歪”
👉 推荐:
- α = r 或 α = 0.5r
- 或者降低学习率,而不是硬顶 α
3. 做的是“知识注入型任务”
例如:
- 专业 QA
- 法律 / 医疗
- 事实性增强
这种任务:
- 不需要大幅度权重偏移
- 更需要稳定、精确
👉 常用:
α / r ≈ 0.5 ~ 1
五、工程上更“正确”的设置方式(推荐)
不要问 “α 该不该等于 2r”
而是问:
我希望 LoRA 的有效更新强度是多少?
一个实用表(可直接用)
| 场景 | 推荐 α / r |
|---|---|
| 指令 / 对话 / 风格 | 1.5 ~ 2 |
| 通用微调 | 1 |
| 小样本 + 噪声 | 0.5 ~ 1 |
| 大 r(≥64) | ≤ 1 |
| 多模块 LoRA(q,k,v,o + FFN) | 0.5 ~ 1 |
然后反推:
[
\alpha = r \times (\alpha / r)
]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号