Seata用法
概念
事务分组(tx-service-group):Seata 中用于隔离事务流量的 “逻辑分组”,每个分组对应一组 Seata Server 集群(如 core_biz_group 对应核心业务集群,non_core_biz_group 对应非核心业务集群)。
使用场景:以 “双 11 大促” 为例,假设需要隔离 核心业务(订单支付) 和 非核心业务(物流预约) 的事务流量,避免非核心业务的事务压力影响核心支付流程,具体操作如下:
全局事务状态

AT模式
使用 AT 模式可以最小程度减少业务改造成本。性能相对差些。
数据库性能AT 模式依赖数据库完成事务分支的提交 / 回滚,且需要写入 undo 日志、全局锁查询等额外操作。数据库的并发能力(如连接池大小、索引优化、磁盘 IO)是最大瓶颈。
简单全局事务(2-3 个服务节点,单表 CRUD):TPS 通常在 1000-5000 之间
复杂场景(如:跨机房部署、多服务多表关联、长事务、数据库压力大):TPS 可能降至 100-1000,甚至更低(取决于具体瓶颈)。
- 在Springboot启动程序加上,@EnableAutoDataSourceProxy 确保数据源被代理
- 在全局事务启动的方法上加 @GlobalTransactional
分支事务代码无需做任何处理。
TCC
优势:TCC 完全不依赖底层数据库,能够实现跨数据库、跨应用资源管理,可以提供给业务方更细粒度的控制。
缺点:TCC 是一种侵入式的分布式事务解决方案,需要业务系统自行实现 Try,Confirm,Cancel 三个操作,对业务系统有着非常大的入侵性,设计相对复杂。
适用场景:TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
实现类加上
@LocalTCC
其他参考
https://seata.apache.org/zh-cn/docs/user/mode/tcc
SAGA模式
Saga 模式是 SEATA 提供的长事务解决方案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
适用场景:
业务流程长、业务流程多
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
一阶段提交本地事务,无锁,高性能
事件驱动架构,参与者可异步执行,高吞吐
补偿服务易于实现
缺点:
不保证隔离性(应对方案见后面文档)
Saga 的场景:流程步骤通常是跨微服务的(分布式环境)。Saga 的场景:必须保证跨服务操作的最终一致性,失败后需要 “补偿回滚”。跟Liteflow还是有本质区别。
配置
之前参考官方saga的demo,把xml改成Configuration形式来注册bean导致启动报错
java.lang.NullPointerException: Cannot invoke "io.seata.saga.engine.StateMachineEngine.forward(String, java.util.Map)" because the return value of "io.seata.saga.rm.StateMachineEngineHolder.getStateMachineEngine()" is null
🧐 根本原因分析:重复配置冲突
在 Seata 2.5 版本中,当您使用了官方提供的 org.apache.seata:seata-spring-boot-starter:2.5.0 依赖时:
该 Starter 会通过 SeataSagaAutoConfiguration 自动配置并创建所有必要的 Saga Bean,包括 DbStateMachineConfig、StateMachineEngine,并最终通过内部机制将 StateMachineEngine 实例设置到静态的 io.seata.saga.rm.StateMachineEngineHolder 中。
您手动定义了 SeataSagaConfig 配置类,它也定义了 DbStateMachineConfig、ProcessCtrlStateMachineEngine,以及一个名为 "stateMachineEngineHolder" 的 StateMachineEngineHolder Bean。
解决办法:
解决方案:移除手动配置,启用自动配置
seata:
saga:
enabled: true
# 配置状态机定义文件路径(关键的触发条件之一)
statelang:
resources: statelang/*.json
# 配置 Saga 引擎需要的事务组
tx-service-group: default_tx_group
2.3 版本注解式用法
commit 失败,不会重试,会触发调用rollback方法。如果要实现自定义重试策略,要使用状态机控制
rollback 失败会不停地重试
状态机用法
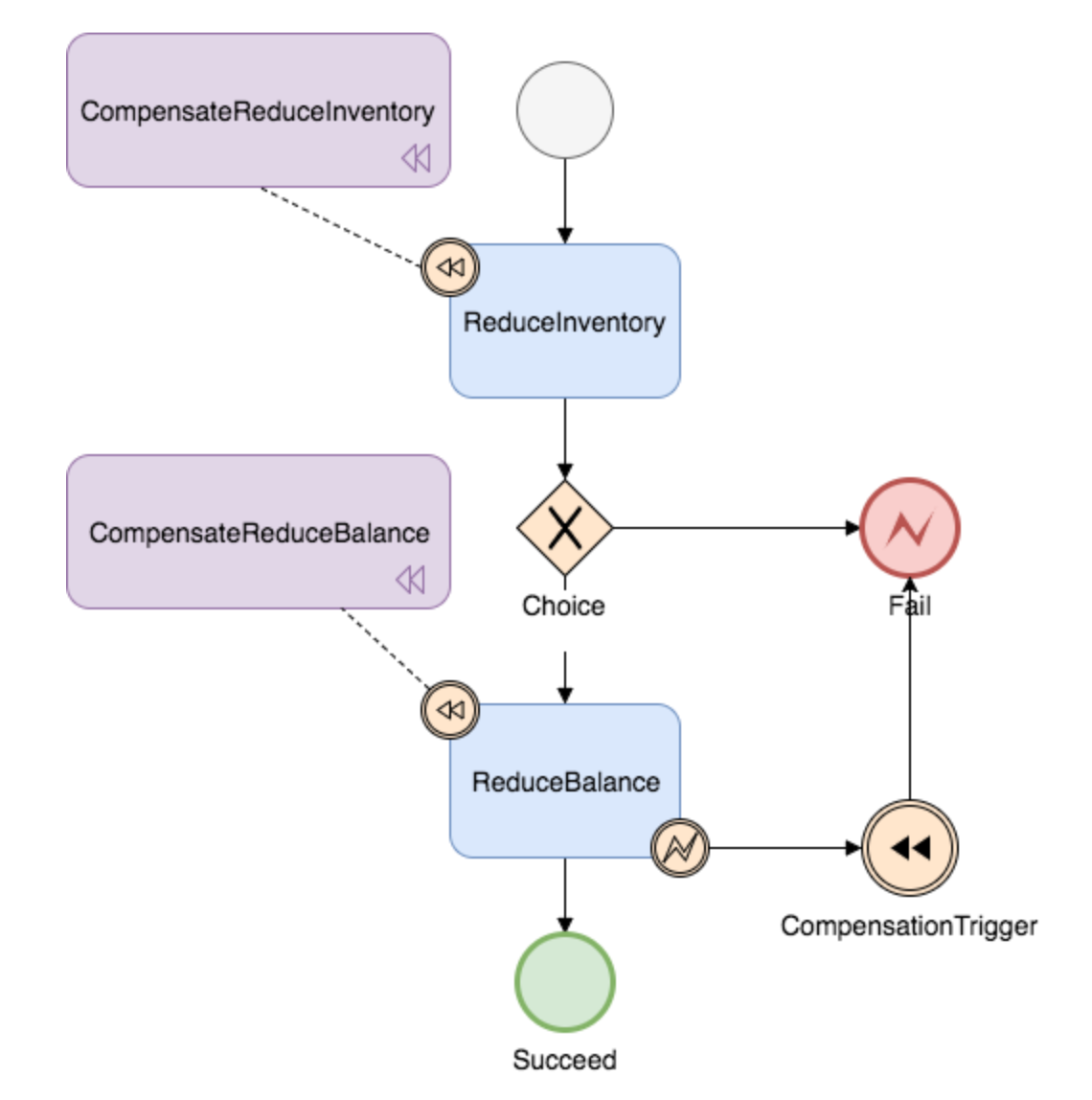

-
有个最终的成功节点。
如果某个节点失败,状态设置为Fail,那么后续节点将不再执行。 -
有个最终的失败节点
-
当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚。使用CompensationTrigger 解决saga链反向回滚。
并不是某个节点的异常都选择反向补偿(回滚),得看具体的业务场景。
场景1:最终一致性,经过多次重试后停止,不做回滚补偿(回滚的例子)。比如在B端的电商系统,履约系统生成履约单后推送WMS出库失败。这个时候是不适合回滚的。就要不停地重试,经过几次重试后,还是失败,人工介入修数据,重新调用接口。因为:履约做了大量的事情(人工评审,系统分仓等),次数回滚的代价很大,不停重试代价更小。
场景2:关键节点失败,回滚该节点之前的所有节点。
比如电商,下单,占可销售库存。如果占可销售库存失败,那么下单就要回滚(报下单失败),避免超卖。
Status
Status: 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知, 我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个 map 结构,key 是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是 SpringEL 表达式判断服务返回参数,带$Exception{开头表示判断异常类型。value 是当这个条件表达式成立时则将服务执行状态映射成这个值
好的,关于 Seata Saga 模式下,状态机中服务执行状态(Status)映射为 FA (失败) 和 UN (未知) 时,Seata 框架的处理逻辑如下:
🔄 Seata Saga 框架对 FA (失败) 状态的处理
当服务的执行状态被映射为 FA (Failure/失败) 时,框架会根据 Saga 状态机中的定义,立即触发补偿(Compensation)或回滚逻辑。
1. 立即停止正向执行
- 中断流程: 全局事务的正向执行会被立即中断。
- 不会执行后续节点: 状态机不会再尝试执行当前节点之后的任何正向执行服务(除非有明确的异常捕获/路由机制,但在标准失败情况下,会直接进入回滚)。
2. 启动回滚/补偿流程
- 逆向执行: 框架会沿着已成功执行的节点,逆序触发它们的补偿(Compensation)服务。
- 补偿服务(Compensation Service): 在 Saga 状态机中,每个正向服务(
action)都应该定义一个对应的compensation字段,指向一个用来撤销该服务影响的补偿服务。 - 目标: 将整个 Saga 事务恢复到初始状态,确保数据最终的一致性。
saga出现异常不回滚,经过多次重试后停止,不做回滚补偿(回滚的例子)。
状态机编写注意事项
- 节点不需要做 choice判断,直接 "Next" 下个节点
- 节点内的Status子节点后增加 Retry节点,做异常重试
状态机配置例子
{
"Name": "pushSupplyChainAndBpm_retry",
"Comment": "push SupplyChain and Bpm with retry, no compensation; pushBpm success→Succeed, fail→Fail",
"StartState": "pushSupplyChain",
"Version": "0.0.1",
"States": {
"pushSupplyChain": {
"Type": "ServiceTask",
"ServiceName": "sagaStateSupplyChainClient",
"ServiceMethod": "commit",
"Next": "pushBpm",
"Input": ["$.[businessKey]", "$.[order]"],
"Output": { "pushSupplyChainResult": "$.#root" },
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
},
"Retry": [
{
"Exceptions": ["java.lang.Throwable"],
"IntervalSeconds": 1.5,
"MaxAttempts": 3,
"BackoffRate": 1.5
},
{
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 1.5
}
]
},
"pushBpm": {
"Type": "ServiceTask",
"ServiceName": "sagaStateBpmClient",
"ServiceMethod": "commit",
"Input": ["$.[businessKey]", "$.[order]", { "throwException": "$.[mockPushBpmFail]" }],
"Output": { "bpmPushResult": "$.#root" },
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
},
"Retry": [
{
"Exceptions": ["java.lang.Throwable"],
"IntervalSeconds": 1.5,
"MaxAttempts": 3,
"BackoffRate": 1.5
},
{
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 1.5
}
],
"Next": "Fail"
},
"Succeed": { "Type": "Succeed" },
"Fail": {
"Type": "Fail",
"ErrorCode": "PUSH_BPM_FAILED",
"Message": "pushBpm failed after 4 retries, need manual handling"
}
}
}
package com.example.order.facade;
import com.example.order.client.ItemFeignClient;
import com.example.order.client.SagaStateBpmClient;
import com.example.order.client.SagaStateSupplyChainClient;
import com.example.order.client.SupplyChainClient;
import com.example.order.entity.Order;
import com.example.order.service.AtOrderService;
import com.example.order.service.TccOrderService;
import jakarta.annotation.Resource;
import org.apache.seata.core.context.RootContext;
import org.apache.seata.saga.engine.StateMachineEngine;
import org.apache.seata.saga.engine.impl.ProcessCtrlStateMachineEngine;
import org.apache.seata.saga.statelang.domain.ExecutionStatus;
import org.apache.seata.saga.statelang.domain.StateMachineInstance;
import org.apache.seata.spring.annotation.GlobalTransactional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.HashMap;
import java.util.Map;
@Component
public class OrderFacadeImpl {
@Autowired
private StateMachineEngine stateMachineEngine;
public String sagaStateTest(Order order) {
Map<String, Object> startParams = new HashMap<>(3);
String businessKey = String.valueOf(System.currentTimeMillis());
startParams.put("businessKey", businessKey);
startParams.put("count", 10);
startParams.put("amount", new BigDecimal("100"));
startParams.put("order", order);
StateMachineInstance inst = stateMachineEngine.startWithBusinessKey("pushSupplyChainAndBpm_retry", null,
businessKey, startParams);
ExecutionStatus status = inst.getStatus();
System.out.println(status.getStatusString());
return "success";
}
}
关键节点失败,回滚该节点之前的所有节点例子
参考官方的DEMO:https://seata.apache.org/zh-cn/docs/user/mode/saga/#demo-简介
StateMachineEngine
StateMachineInstance startWithBusinessKey(String stateMachineName, String tenantId, String businessKey,
Map<String, Object> startParams) throws EngineExecutionException;
在 Seata Saga 的 StateMachineEngine.startWithBusinessKey 接口中,tenantId 和 businessKey 的作用如下:
businessKey:业务唯一标识符 (Business Unique Identifier)
businessKey 是由您的业务系统提供的一个唯一标识,它用于将 Saga 状态机实例与您实际的业务流程关联起来。
businessKey 是由您的业务系统提供的一个唯一标识,它用于将 Saga 状态机实例与您实际的业务流程关联起来。
| 作用 | 解释 |
|---|---|
| 业务关联 | 它是业务系统的视角,例如一个订单号、一个转账流水号等。通过它,您可以方便地从业务层面定位到对应的 Saga 事务。 |
| 幂等控制 | Saga 引擎在启动时,会检查是否存在相同 stateMachineName 和 businessKey 组合且尚未结束(处于运行中)的实例。这有助于防止重复提交,实现业务层的幂等性。 |
| 查询依据 | 它是事后查询和跟踪 Saga 事务状态的主要依据。您可以通过 businessKey 快速查找对应的 StateMachineInstance。 |
作用,解释
业务关联,它是业务系统的视角,例如一个订单号、一个转账流水号等。通过它,您可以方便地从业务层面定位到对应的 Saga 事务。
幂等控制,Saga 引擎在启动时,会检查是否存在相同 stateMachineName 和 businessKey 组合且尚未结束(处于运行中)的实例。这有助于防止重复提交,实现业务层的幂等性。
查询依据,它是事后查询和跟踪 Saga 事务状态的主要依据。您可以通过 businessKey 快速查找对应的 StateMachineInstance。
tenantId:租户标识符 (Tenant Identifier)
tenantId 是用于多租户隔离的标识符。
| 作用 | 解释 |
|---|---|
| 资源隔离 | 在一个多租户(Multi-Tenant)的环境中,不同的租户(例如不同的公司或部门)可能共享同一个 Saga 平台。tenantId 用于将属于不同租户的状态机实例、状态机定义和数据日志进行逻辑隔离。 |
| 查询过滤 | 在查询状态机实例时,可以根据 tenantId 缩小范围,确保每个租户只能看到自己的数据。 |
注意:
- 如果您的应用是单租户或没有多租户需求(例如您 Demo 中传入
null),则可以忽略此参数,或者传入一个默认值(如DEFAULT)。 - 在 Saga 引擎底层,
tenantId通常会作为查询条件的一部分,或者在数据库设计中作为表字段的一部分,以实现物理或逻辑上的数据隔离。
其他
RocketMQ 接入 Seata
然后通过SeataMQProducerFactory创建生产者,然后通过 SeataMQProducer 可以直接使用 RocketMQ 发送消息。以下是一个例子:
public class BusinessServiceImpl implements BusinessService {
private static final String NAME_SERVER = "127.0.0.1:9876";
private static final String PRODUCER_GROUP = "test-group";
private static final String TOPIC = "test-topic";
private static SeataMQProducer producer= SeataMQProducerFactory.createSingle(NAME_SERVER, PRODUCER_GROUP);
public void purchase(String userId, String commodityCode, int orderCount) {
producer.send(new Message(TOPIC, "testMessage".getBytes(StandardCharsets.UTF_8)));
//do something
}
}
这样达到的效果是:生产消息作为Seata分布式事务的参与者RM,当全局事务的一阶段完成,这个MQ消息会根据二阶段要求commit/rollback进行消息的提交或撤回,在此之前消息不会被消费。 注: 当前线程中如果没有xid,该producer会退化为普通的send,而不是发送半消息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号