RAFT 共识算法
Leader - Follower 消息同步
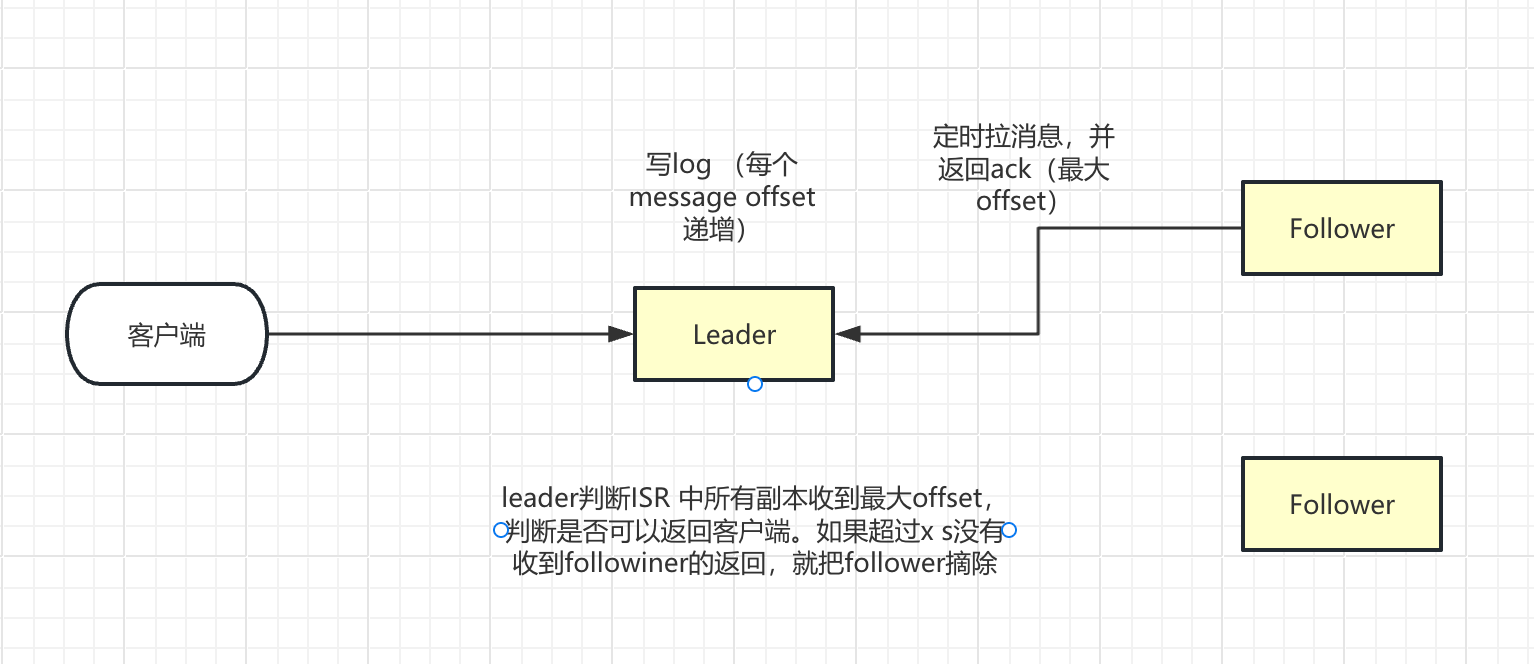
- 当client端写请求给follower,请求会被重定向到leader
- follower定时批量拉取leader数据
- l
以Kafka为例子
在 Kafka 中,Leader 节点确保所有 Follower 节点成功接收消息的机制,主要通过 ISR(In-Sync Replicas,同步副本列表) 和 acks 消息确认机制 实现,具体流程如下:
1. 核心机制:ISR 列表与同步确认
-
ISR 列表:每个分区的 Leader 会维护一个 ISR 列表,记录与自己保持同步的 Follower 节点(包括 Leader 自身)。
Follower 需满足两个条件才能留在 ISR 中:- 与 Leader 保持网络连接(通过定期 heartbeat 心跳机制确认存活);
- 消息同步进度不落后于 Leader 太多(可通过
replica.lag.time.max.ms配置容忍的最大同步延迟,默认 30 秒)。
-
消息同步流程:
- 生产者发送消息到 Leader 后,Leader 将消息写入本地日志;
- Follower 定期向 Leader 发送拉取请求(
FetchRequest),同步新消息并写入本地日志; - Follower 同步完成后,向 Leader 返回确认(
FetchResponse); - Leader 收到 Follower 的确认后,更新该 Follower 的同步进度,确保其留在 ISR 中。
2. 确保所有 Follower 接收的关键配置:acks 参数
生产者通过设置 acks 参数,控制 Leader 何时向生产者返回“消息发送成功”的确认,从而间接确保 Follower 同步状态:
-
当
acks=all(或-1)时:
Leader 必须等待 ISR 中所有副本(包括所有 Follower) 都成功写入消息后,才向生产者返回确认。
这是最严格的配置,可确保消息被所有同步的 Follower 接收(只要它们在 ISR 中)。 -
其他
acks配置的区别:acks=1(默认):仅 Leader 写入成功后即返回确认,不等待 Follower 同步(可能存在 Follower 未收到的风险);acks=0:Leader 接收消息后立即返回确认,不等待写入本地日志(可靠性最低)。
3. 异常处理:Follower 同步失败的情况
- 若某个 Follower 长时间未同步(超过
replica.lag.time.max.ms),Leader 会将其从 ISR 中移除; - 此时若
acks=all,Leader 只需等待 剩余 ISR 中的副本 确认即可(无需等待已脱离 ISR 的 Follower); - 若需严格确保“最初配置的 2 个 Follower 都必须收到”,需结合以下配置:
min.insync.replicas=N(例如设置为 3,即 Leader + 2 Follower 都在 ISR 中才允许写入);- 同时保证
acks=all,此时若任何一个 Follower 脱离 ISR,生产者会收到异常(NotEnoughReplicasException),需重试直到所有 Follower 同步完成。
总结
要确保 2 个 Follower 都收到消息,需满足:
- 生产者配置
acks=all; - 2 个 Follower 均处于 ISR 列表中(同步正常);
- 可选配置
min.insync.replicas=3(强制要求 Leader + 2 Follower 都同步成功,否则拒绝写入)。
通过这套机制,Kafka 既能保证消息可靠同步到 Follower,又能通过 ISR 动态调整同步范围,避免因个别节点故障导致整个集群不可用。
RAFT 共识算法
解决什么问题?
- Leader恢复后,不能成为leader,只能成为Candidate参与竞选
- 解决投票分裂的问题
关键设计
- 投票超时时间轮,
- term轮数
follower 150-300 ms收不到leader请求,就转化为候选人角色,开启投票。给自己投一票,然后把自己节点日志的数据量,term的轮数广播出去,让大家投票。
投票过程
其他节点(Follower 或 Candidate)收到 “RequestVote” 后,根据以下规则决定是否投票:
规则 1:若请求的 “任期号” < 当前节点的 “任期号”,拒绝投票(旧任期请求无效);
规则 2:若请求的 “任期号” > 当前节点的 “任期号”,更新自身任期号为请求的任期号,转为 Follower,并给该 Candidate 投票;
规则 3:若任期号相同,但已给其他 Candidate 投过票,拒绝投票(每个任期仅投 1 票);
规则 4:若 Candidate 的日志 “完整性”(日志长度 + 最后一条日志的任期号)低于自身,拒绝投票(确保 Leader 的日志是最完整的,避免数据丢失)。
如果发生投票分裂的情况怎么解决?
ABCDE(Leader), 假如AB同时发现 E挂了,AB转化为候选人先给自己投一票,然后广播让别人给自己投票。 由于AB的数据是一样的,C给A投,D给B投,结果没有超过半数。 那么投票时间超时后还要进行下一轮投票。 当C也感知到E挂了,也参与选举,C的term最大,大家都投给C,,,C编程leader
Term 计算规则
在RAFT共识算法中,Term(任期)是一个核心概念,用于标识选举周期和确保分布式系统的一致性。每个节点独立维护一个Term轮数,其定义和规则如下:
1. Term的本质
- 逻辑时钟:Term是一个连续递增的整数,作为节点的逻辑时钟,用于区分不同的选举周期。
- 全局唯一性:同一时刻,集群中所有节点的Term值可能不同,但通过通信机制最终会达成一致。
- 阶段划分:每个Term由选举开始,可能持续到下一选举触发,期间最多产生一个Leader。
2. Term的初始值与递增规则
- 初始状态:所有节点启动时Term为1,且处于Follower状态。
- 选举触发递增:
- 当Follower因未收到Leader心跳而超时,会转为Candidate并将Term加1,发起新一轮选举。
- 若选举失败(如投票分裂),所有Candidate的Term再次递增,重新发起选举。
- 被动更新:
- 当节点收到包含更大Term的RPC请求(如AppendEntries或RequestVote),会立即更新本地Term为该值,并转为Follower。
- 即使当前节点是Leader或Candidate,只要发现其他节点的Term更大,必须无条件降级为Follower。
3. Term在选举中的作用
- 避免脑裂:每个Term内最多产生一个Leader。若多个Candidate竞争,只有获得超过半数投票且Term最大的Candidate才能成为Leader。
- 投票规则:
- 节点在一个Term内只能投一次票,且优先投票给Term更大的Candidate。
- 若Candidate的Term等于接收者的Term,接收者会比较日志新旧(最后一条日志的Term和索引),仅当Candidate日志更新时才投票。
4. Term与日志一致性
- 日志安全保证:Leader在复制日志时会携带当前Term,确保Follower只接受Term不小于本地的日志条目。
- 日志冲突解决:
- 当Follower发现日志与Leader不一致时,会根据Term和索引回滚到最近的匹配点,再重新复制Leader的日志。
- 已提交的日志(被多数节点确认)不会因Term变化而被覆盖,因为新Leader必须包含所有已提交日志。
5. Term的通信机制
- RPC携带Term:所有RPC请求(如AppendEntries、RequestVote)和响应都会包含发送方的Term。
- 过期请求处理:
- 若接收方的Term大于发送方,直接拒绝请求。
- 若接收方的Term小于发送方,更新本地Term并转为Follower。
6. 特殊场景处理
- 网络分区:
- 分区内可能产生临时Leader,但一旦分区恢复,持有更大Term的节点会成为新Leader,旧Leader自动降级。
- 成员变更:
- 在配置变更期间(如添加或移除节点),Term机制确保新旧配置交替时不会出现脑裂。
总结
Term是RAFT算法的核心机制,通过逻辑时钟、选举规则和日志复制的约束,确保了分布式系统的一致性和容错性。其核心规则包括:
- 递增性:Term始终递增,永不回退。
- 唯一性:每个Term内最多一个Leader。
- 权威性:节点始终信任更大的Term,并据此调整状态。
这一设计使得RAFT在复杂的网络环境中仍能高效、安全地运行,成为分布式系统中广泛采用的共识算法之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号