
YOLO 模型训练显卡性能实测:如何选择合适的 GPU ?
 本文基于 YOLO 的模型训练场景对不用的显卡进行性能测试,选择 RTX 3090、4090,A100 40G 三张显卡比较训练耗时。结果显示 A100 具有最好的性能及稳定性,同时测试了不同 batch size 下面的性能表现,3090 在大 batch size 下出现明显的性能衰竭。因此,模型训练场景需要根据输入图像大小,batch size 大小选择最合适的 GPU 进行训练。
本文基于 YOLO 的模型训练场景对不用的显卡进行性能测试,选择 RTX 3090、4090,A100 40G 三张显卡比较训练耗时。结果显示 A100 具有最好的性能及稳定性,同时测试了不同 batch size 下面的性能表现,3090 在大 batch size 下出现明显的性能衰竭。因此,模型训练场景需要根据输入图像大小,batch size 大小选择最合适的 GPU 进行训练。
YOLO(You Only Look Once) 是目前计算机视觉领域最流行的目标检测和图像分割模型。YOLO 一般需要基于图像标注数据对模型进行训练,因此 GPU 资源变成了一个必需项,现在越来越多的人通过算力云平台租用 GPU 的方式来进行 YOLO 的模型训练或者推理。
晨涧云算力平台云容器 支持 YOLO 镜像,创建实例就可以使用,我们基于这个即开即用的环境选择不同显卡进行测试。
显卡选择及测试环境
显卡选择
这里选择 GPU 算力平台上最常见的三张显卡:3090 24G、4090 24G、A100 40G 进行YOLO模型训练的测试。
先来看下这3张显卡的参数对比:
| RTX3090 | RTX4090 | A100 40G | |
|---|---|---|---|
| 架构 | Ampere | Ada Lovelace | Ampere |
| CUDA核心数 | 10,496 | 16,384 | 6,912 |
| 显存容量 | 24 GB GDDR6X | 24 GB GDDR6X | 40GB HBM2 |
| 显存带宽 | 936 GB/s | 1,008 GB/s | 1,555 GB/s |
| TDP功耗 | 350W | 450W | 250W |
| FP32 算力 | 35.6 TFLOPS | 82.6 TFLOPS | 19.5 TFLOPS |
| Tensor FP16 算力 | 142 TFLOPS | 330 TFLOPS | 312 TFLOPS |
CPU和内存
CPU:16核
内存:48GB
测试模型及数据集
训练模型:yolo11n.pt
训练数据集:coco.yaml
参数控制
因为原始的 coco 数据集较大,为了节省训练测试的时间,仅使用20%的样本进行训练,设置 fraction = 0.2 ;因为只是测试显卡性能,这里仅训练3轮,设置 epochs = 3 ;同时配置 batch_sizes = [16, 32, 64, 128] ,测试每个 batch_size 下的训练耗时。
控制其他的训练参数保持一致,图像大小使用640。
统计每张显卡模型训练3轮 总耗时 , 平均每轮Epoch耗时 ,同时采集训练过程中的GPU指标:GPU利用率 ,显存占用 等。
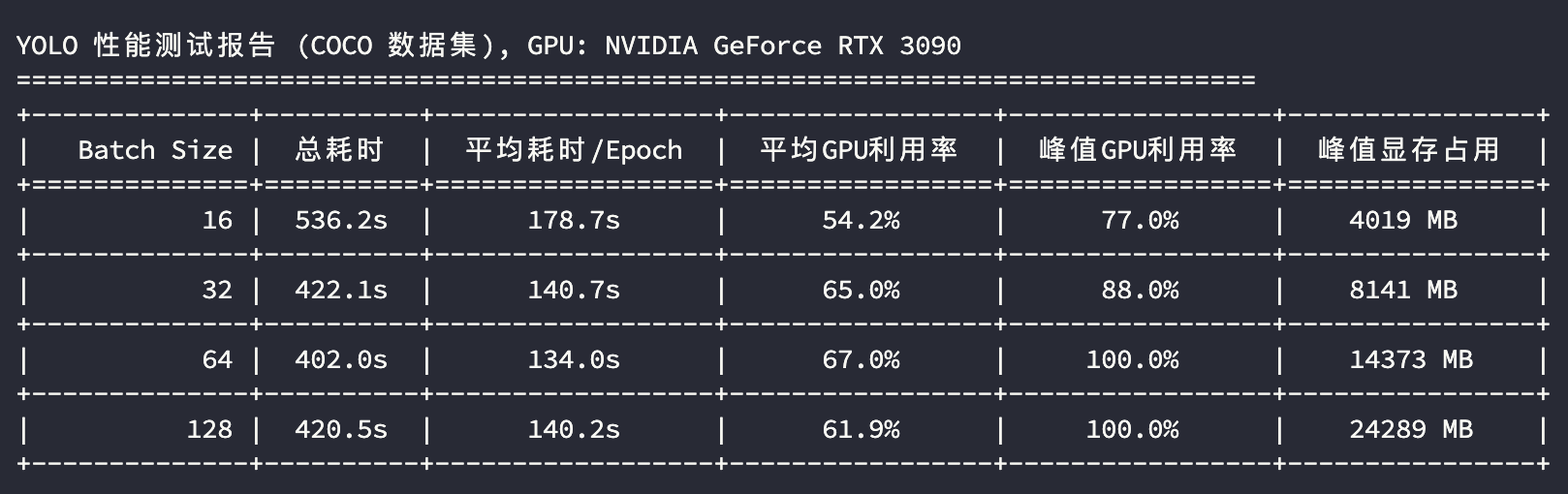
3090 模型训练测试
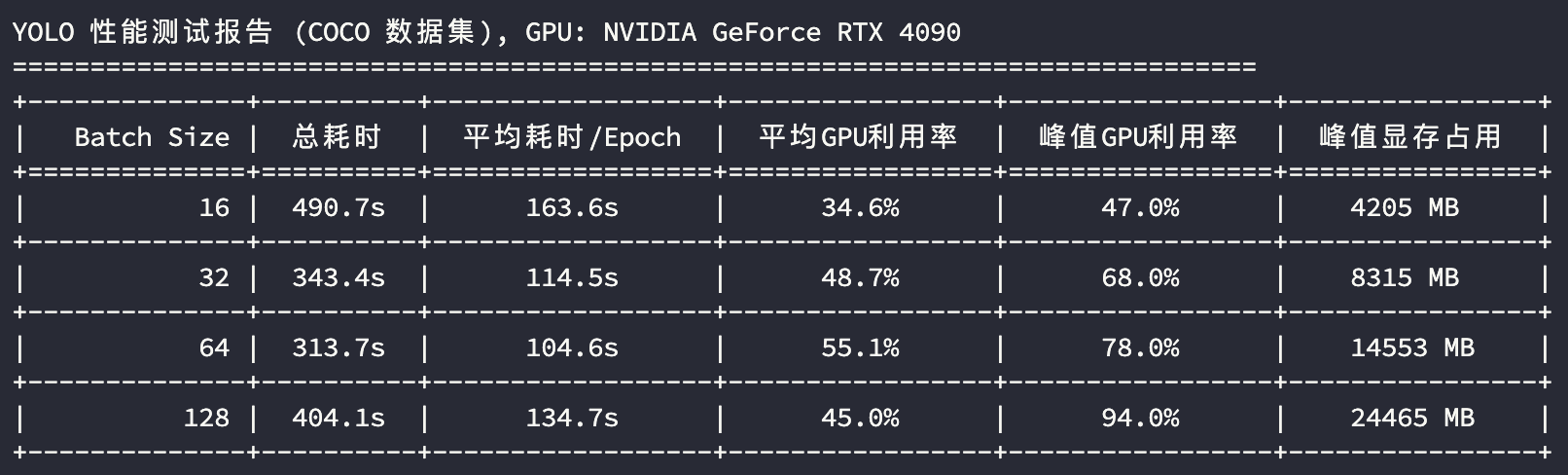
4090 模型训练测试
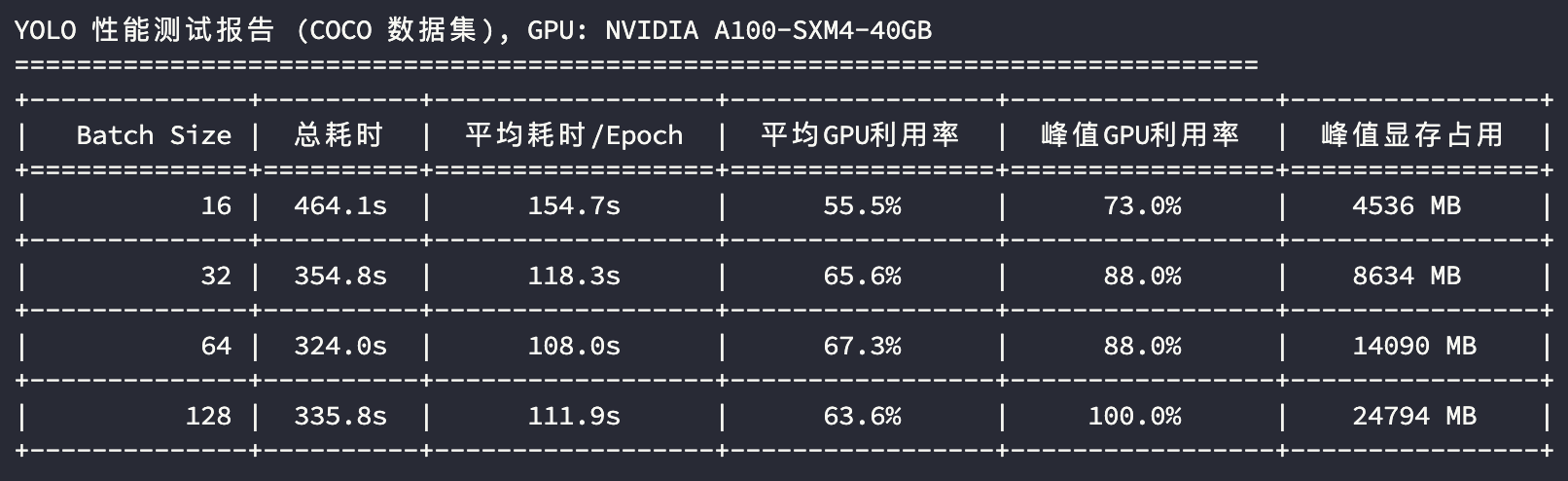
A100 模型训练测试
测试结果分析
从 GPU 使用指标分析,3090 和 4090 都是 24GB 的显存,3090 在batch_size=64的时候已经接近性能上限;在 batch_size=128 的时候3090和4090显存几乎占满,峰值GPU利用率接近压满,性能出现衰退;A100 凭借其 40GB 的显存及较大的显存带宽,在训练场景性能的上限更高。
⚠️ 注意:因为图片需要在CPU解码, batch_size 较大的时候CPU的负荷会上升,当CPU性能不足时会变成瓶颈,从而制约 GPU 的性能。
因此,针对大 batch_size 的训练场景,需要控制:
- 配置更多的CPU核数,比如 batch_size=128 建议16核及以上
- 训练参数
workers调到更大,比如 batch_size=128 建议 workers >= 8
如果我们使用每轮Epoch的平均耗时来评估显卡性能,将上述测试结果汇总成表格:
| BatchSize | RTX3090 | RTX4090 | A10040G | |
|---|---|---|---|---|
| 16 | 平均Epoch耗时(s) | 178.7 | 163.6 | 154.7 |
| 32 | 平均Epoch耗时(s) | 140.7 | 114.5 | 118.3 |
| 64 | 平均Epoch耗时(s) | 134.0 | 104.6 | 108.0 |
| 128 | 平均Epoch耗时(s) | 140.2 | 134.7 | 111.9 |
可以看到,A100 作为训练神卡,确实在整体性能上是最稳的。算力层面,从 平均Epoch耗时 分析执行效率,比较 batch_size=64 下的指标,A100 跟 4090 的性能接近,3090 比它们慢 30% 左右。
总结
- 如果 YOLO 训练的图像数据是普通大小,并且不需要使用较大的 batch_size 来提升训练精度,主流的 3090 和 4090 是不错的选择,建议 batch_size 最大 64 左右;
- 如果需要更快出结果可以选择 4090 ,当然相应的费用也会高一些;
- 如果训练数据较小,同时 batch_size 也使用较小的配置,可以选择更低端的显卡,比如
3080 20G,有更高的整体性价比。 - 如果训练的图像尺寸较大,或者想用更大的 batch_size 来提升模型训练的精度,建议使用 A100 ,更大的显存不至于让训练过程 OOM,同时更大的显存带宽保证训练过程的效率和稳定性。
- 另外对于使用较大 batch_size 的场景,魔改的
4090 48G也是一个不错的选择,毕竟4090 算力与 A100 相当,并且魔改后的48G显存让大 batch_size 的训练有更大的施展空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号