
测试不同显卡加速GROMACS分子动力学模拟计算的性能
 GPU算力资源在科研、密集计算等专业领域也发挥着至关重要的作用,这里测试下不同显卡在分子动力学模拟计算场景下的性能表现。比较3080、3090、4090三种不同算力的GPU对Gromacs加速的效果。测试结果显示:Gromacs非常依赖CPU,优先选择高性能的CPU,同时需要结合数据集的大小,配置更好的CPU及更多的CPU核数,才能体现出高性能GPU的算力。
GPU算力资源在科研、密集计算等专业领域也发挥着至关重要的作用,这里测试下不同显卡在分子动力学模拟计算场景下的性能表现。比较3080、3090、4090三种不同算力的GPU对Gromacs加速的效果。测试结果显示:Gromacs非常依赖CPU,优先选择高性能的CPU,同时需要结合数据集的大小,配置更好的CPU及更多的CPU核数,才能体现出高性能GPU的算力。
GPU算力资源不仅可以用于深度学习、大语言模型等AI应用领域,同样在科研、密集计算等专业领域也发挥着至关重要的作用,这里测试下不同显卡在分子动力学模拟计算场景下的性能表现。比较3080、3090、4090三种不同算力的GPU对Gromacs加速的效果。
GROMACS是一款开源的高性能分子动力学(MD)模拟软件,主要用于研究蛋白质、脂质、核酸等生物分子体系在溶液或晶体中随时间的动态行为,也可模拟聚合物和材料等非生物系统。
这里还是租用晨涧云AI算力平台的GROMACS云容器进行测试。
GROMACS测试用例
这里参考了AutoDL上Gromacs的测试用例,这个测试用例的输入数据集较小,所以可能有一定的应用场景局限性,CPU核数配置及GPU的选择需要用户根据自己的输入数据集大小进行灵活调整。
各显卡测试对比
Gromacs会使用CPU的并行计算能力,在多核多线程场景下可以看到几乎所有核的CPU利用率都跑满,但相应的GPU利用率不会跑满。Gromacs的CPU核GPU是协同工作的,且对CPU的依赖度更高,测试发现,不同显卡不同数据集使用场景需要调整合适的CPU核数和GPU的配比,才能使性能最优。
而且,算力越强大的GPU需要对应主频更强劲的CPU,或者配置更多的CPU核数,才能使GPU的算力尽可能的用起来。详见测试:
3080 测试
CPU型号:Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
16核
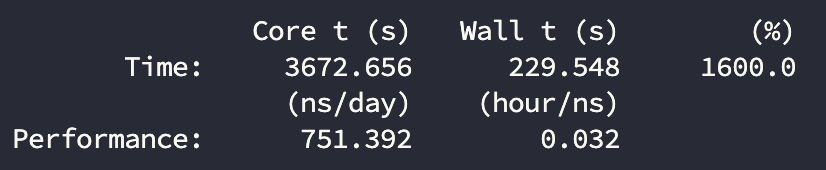
计算结果:
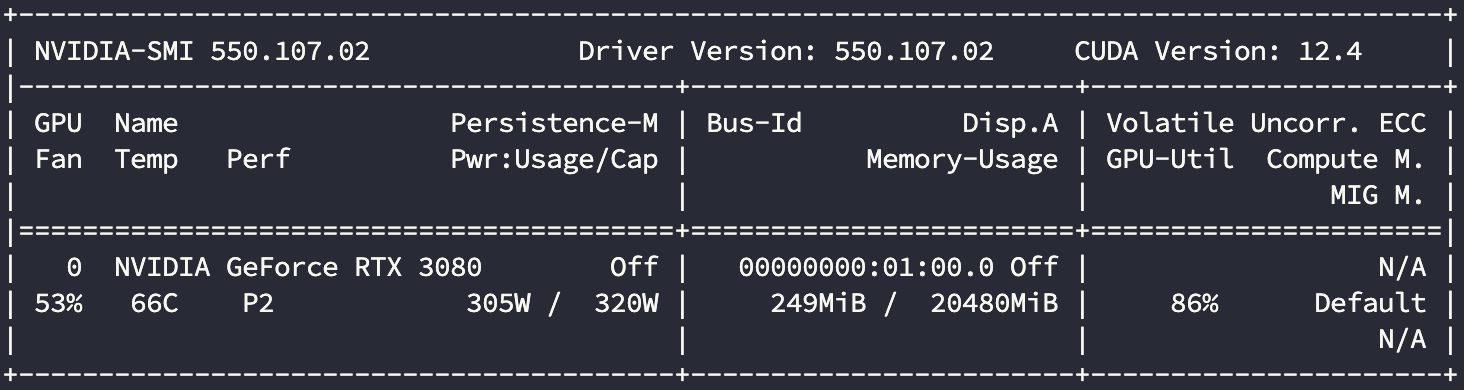
显卡使用情况:
24核
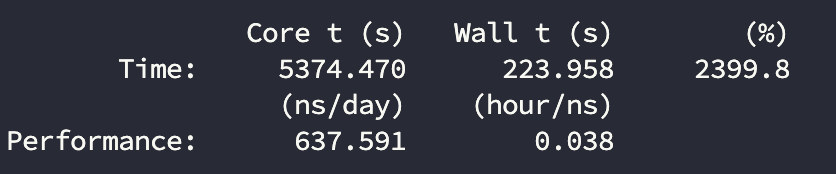
计算结果:
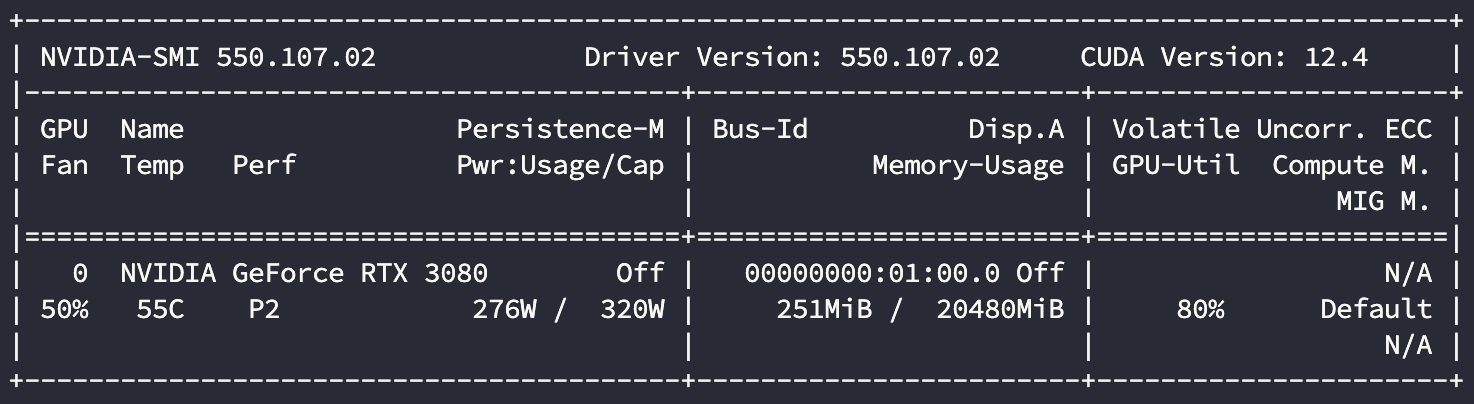
显卡使用情况:
3090 测试
CPU型号:Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
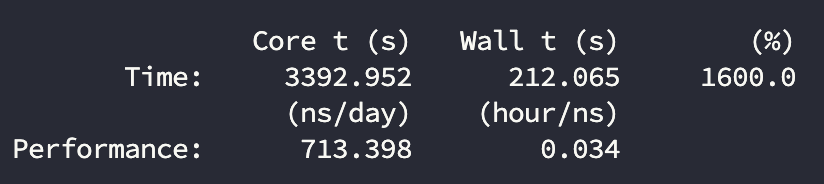
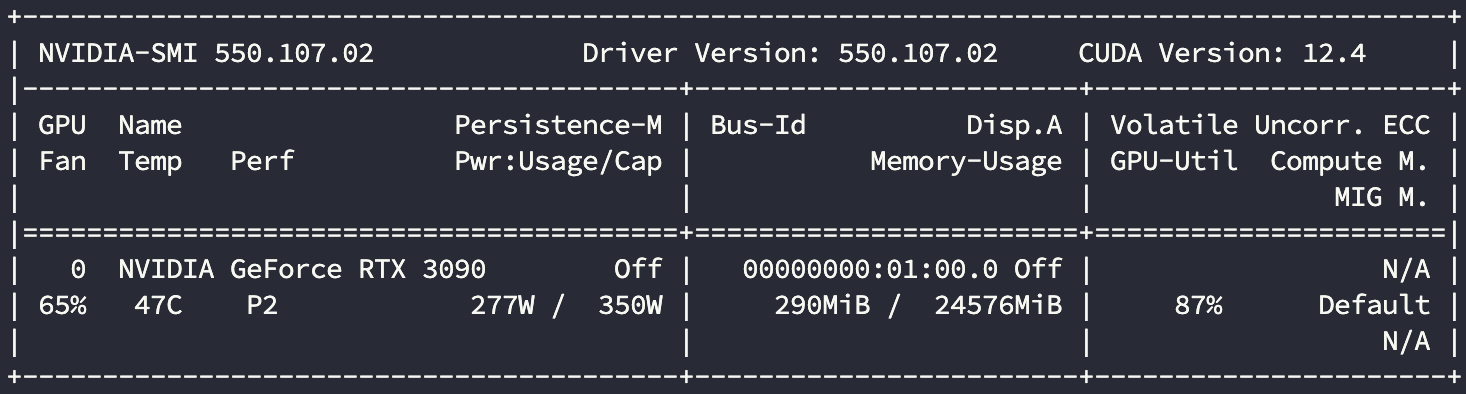
16核
计算结果:
显卡使用情况:
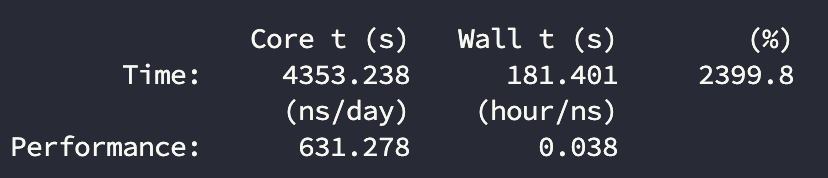
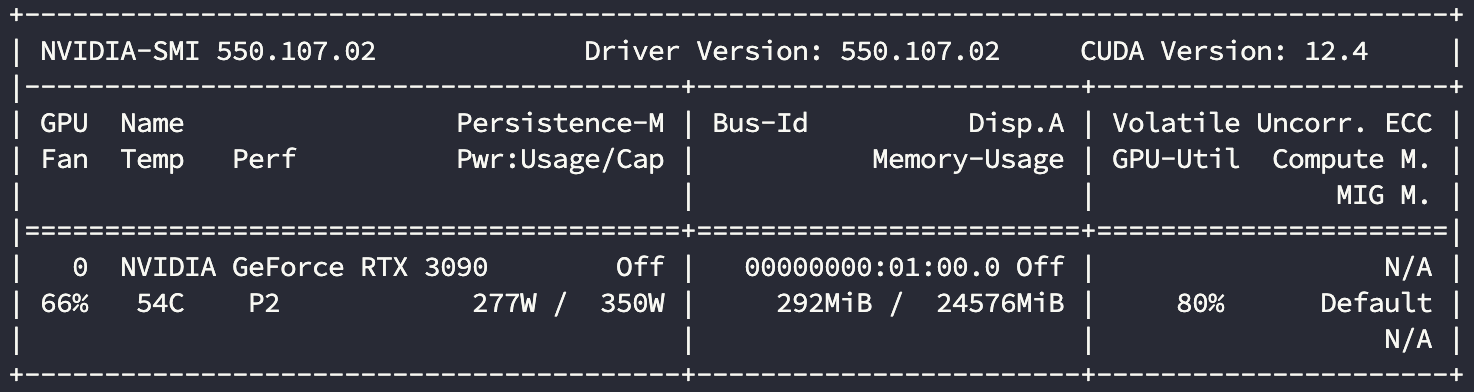
24核
计算结果:
显卡使用情况:
4090 测试
CPU型号:Intel(R) Xeon(R) Platinum 8473C
16核
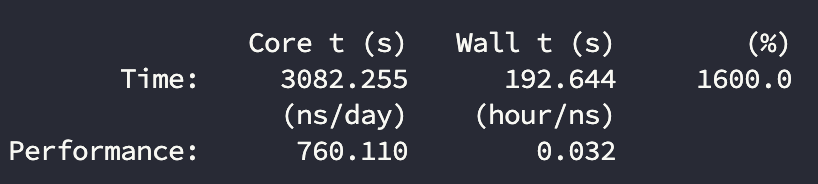
计算结果:
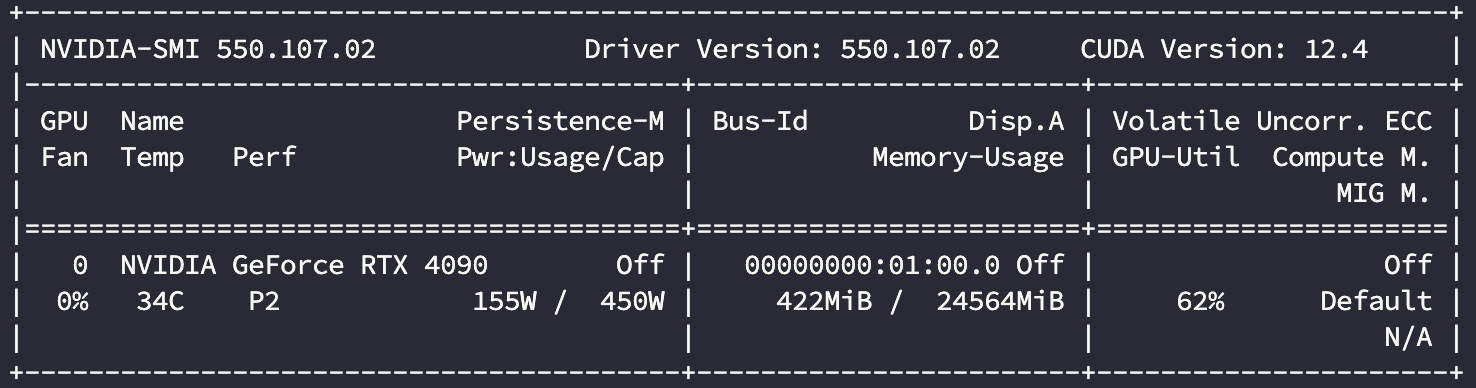
显卡使用情况:
24核
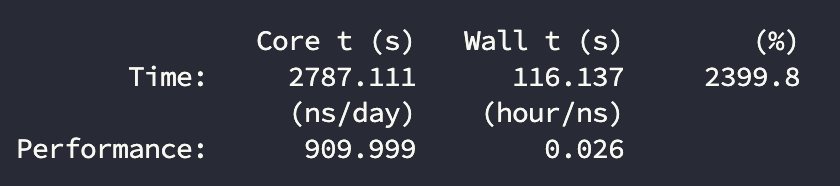
计算结果:
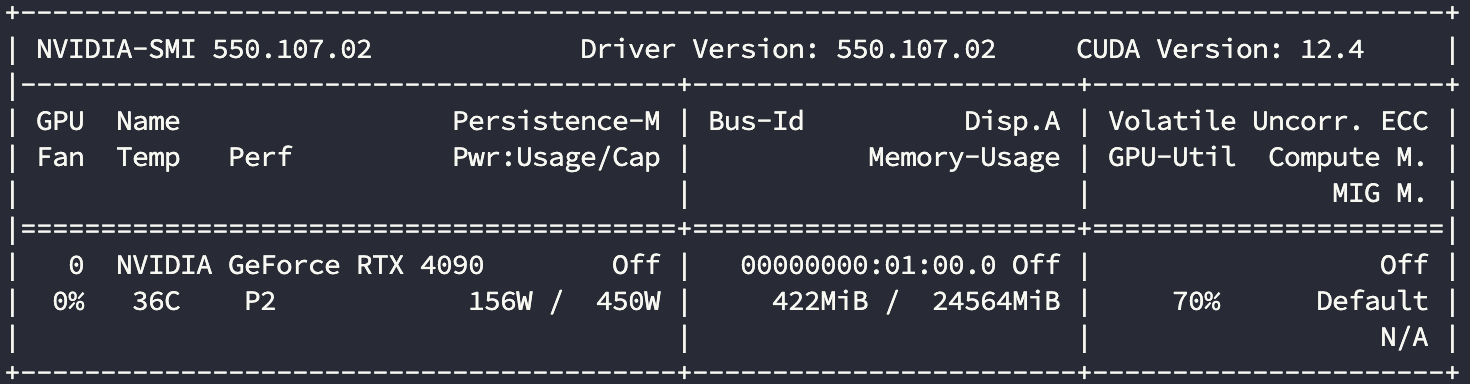
显卡使用情况:
4090同时测试了32核的性能表现:
32核
计算结果:
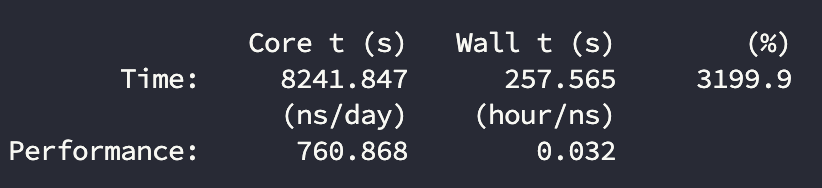
显卡使用情况:
测试结果解释
计算结果的指标解释:
- Core t (s):总 CPU 时间 (Total CPU Time)。是所有 CPU 核心或线程在模拟过程中消耗的时间总和,单位为秒 (s)。
- Wall t (s):墙钟时间 / 实际运行时间 (Wall-Clock Time / Elapsed Time)。 是从模拟开始到结束所实际流逝的时间,单位为秒 (s)。
- (%):并行效率 (Parallel Efficiency) 或加速比 (Speedup) 百分比。计算方式通常是 $\text{Core t (s)} / \text{Wall t (s)} \times 100%$。理想情况下,如果使用了 $N$ 个核心,这个百分比应该接近 N * 100%。数值越大越好。
- (ns/day):关键性能指标,模拟速度 (Simulation Speed),单位是每天模拟多少纳秒。
- (hour/ns):每纳秒模拟时间所需的实际时间,单位是每纳秒 (ns) 需要多少小时 (hour)。是模拟速度 ($\text{ns/day}$) 的倒数形式,表示模拟的“成本”,是模拟速度 ($\text{ns/day}$) 的倒数形式,表示模拟的“成本”,数值越小越好。
主要看(hour/ns)这个指标,反应计算的性能表现。
| GPU | 核数 | ns/day | 峰值GPU利用率 |
|---|---|---|---|
| 3080 | 16 | 751.4 | 86% |
| 3080 | 24 | 637.6 | 80% |
| 3090 | 16 | 713.4 | 87% |
| 3090 | 24 | 631.3 | 80% |
| 4090 | 16 | 760.1 | 62% |
| 4090 | 24 | 910.0 | 70% |
| 4090 | 32 | 760.9 | 61% |
测试中发现,当CPU核数太少或者太多时都不利用Gromacs性能指标ns/day的最大化,且不同GPU需要适配不同的CPU核数。
当CPU核数较少时,没办法充分释放GPU的算力,导致整体性能表现不佳,这个比较好解释;但当CPU核数过大是也会导致模拟速度的下降,问了下大模型,解释如下:
GROMACS 在 GPU 加速计算中常见的性能瓶颈问题,主要与 CPU-GPU 通信、负载平衡以及 Amdahl 定律有关。
当 GROMACS 使用 GPU 进行计算加速时(特别是对于较小的模拟体系),增加分配给模拟的 CPU 核数反而可能导致性能下降 ($\text{ns/day}$ 减小) 和 GPU 利用率降低。核心原因在于任务分配不均和数据传输开销。
在 GROMACS 中,计算任务通常被分配如下:
- GPU 任务(计算密集型): 主要负责非键相互作用(Non-bonded forces)的计算,这是 MD 模拟中最耗时的部分。
- CPU 任务(管理与串行): 主要负责键合相互作用、水模型约束(如 P-LINCS/SETTLE)、长程静电(如 PME 粒子网格)的傅里叶变换部分、数据管理、I/O 以及 CPU-GPU 之间的数据传输。
当您增加 CPU 核数时,会发生以下情况:
- 并行开销增加: 额外的 CPU 核需要相互通信和同步,多核同步的开销(Overhead)会随着核数增加而非线性增长。
- PME 傅里叶瓶颈: GROMACS 的 PME (Particle Mesh Ewald) 算法在傅里叶空间部分的计算通常在 CPU 上运行,并且是串行或并行效率较低的部分。随着 CPU 核数的增加,分配给每个核的 PME 任务量相对减少,但通信和同步等待时间却显著增加。
另外,还有发现3090在这个数据集场景下整体算力性能还不如3080,这个比较奇怪,但3090和3080本身算力差异没有很大,所以可能也有测试本身的随机性影响。
GPU和CPU选择
从上述测试来看,根据输入数据的大小和计算复杂度选择合适的GPU和CPU,可以带来更有的算力性价比。
- Gromacs非常依赖CPU,优先选择高性能的CPU;
- 根据输入数据和计算的紧迫性选择合适的GPU,更高算力的GPU会带来更优的性能;
- 选择高性能的GPU的同时,需要配置更好的CPU及更多的CPU核数,才能体现出高性能GPU的算力;
- 根据数据集大小,结合GPU的性能,配置合理的CPU核数,小数据集较低GPU不要配置过多的CPU核数;
- 对于小数据集,3080 20G显卡具有非常不错的算力性价比。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号