
vLLM实测大模型多卡推理场景显卡性能表现
 使用vLLM测试下多卡推理场景下3090和4090两张显卡的性能表现,看下4090是否在多卡高并发场景下更加具备性能优势。选择 Qwen3的模型进行测试,考虑到是两张显卡,每张都是24GB的显存,选择的是FP16精度的qwen3:14B模型进行测试。3090显卡和4090显卡在多卡模型推理过程中的显存和GPU使用率都比较接近,主要看平均耗时及平均吞吐量两个指标。
使用vLLM测试下多卡推理场景下3090和4090两张显卡的性能表现,看下4090是否在多卡高并发场景下更加具备性能优势。选择 Qwen3的模型进行测试,考虑到是两张显卡,每张都是24GB的显存,选择的是FP16精度的qwen3:14B模型进行测试。3090显卡和4090显卡在多卡模型推理过程中的显存和GPU使用率都比较接近,主要看平均耗时及平均吞吐量两个指标。
之前使用vLLM测试过3090和4090两张显卡大模型单卡推理的性能比较:
这里使用vLLM测试下多卡推理场景下3090和4090两张显卡的性能表现,看下4090是否在多卡高并发场景下更加具备性能优势。
还是在AI算力租赁平台 晨涧云 分别租用3090显卡和4090显卡的vLLM云容器,实例配置选择两张显卡进行测试。
大模型选择
选择 Qwen3的模型进行测试,考虑到是两张显卡,每张都是24GB的显存,选择的是FP16精度的qwen3:14B模型进行测试。
让大模型帮忙写个测试脚本,调整脚本控制变量:
-
使用复杂度近似的N个prompts;
-
MAX_TOKENS配置256,让每次请求需要一定的生成时长便于采样显卡的使用指标,减少波动; -
选择
[1, 4, 8, 16]4种BATCH_SIZES测试不同并发度下的性能表现; -
每轮测试执行3次推理,指标取平均;
-
同时需要模型预热,消除第一次推理响应延时过大的问题;
-
显卡的显存占用和GPU使用率指标使用两卡相加的值。
然后执行测试脚本,查看输出结果。
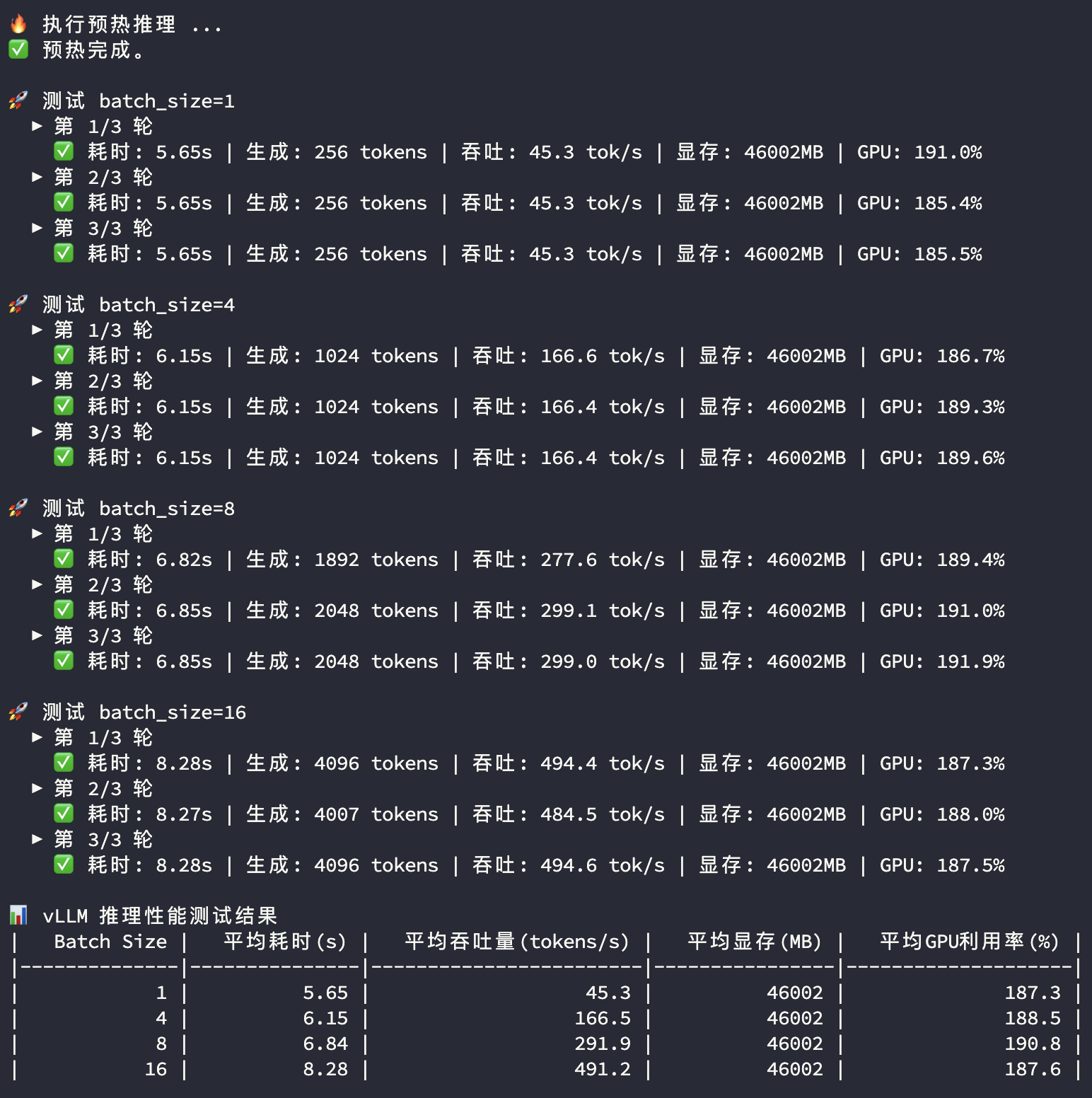
3090多卡推理测试
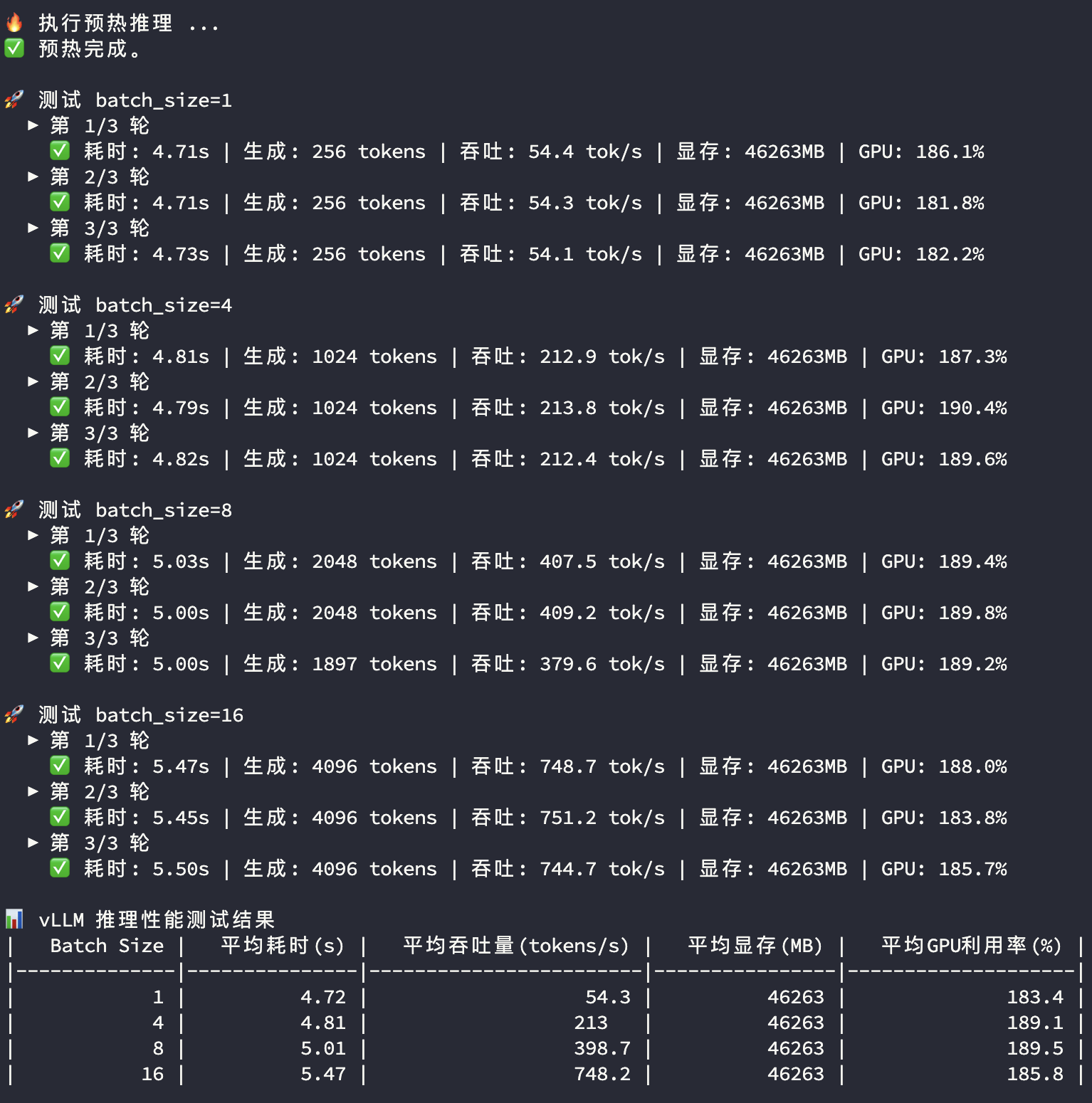
4090多卡推理测试
测试结果解释
-
Batch Size:一次推理调用的并发prompt数量
-
平均耗时 (s):多次推理平均响应时长
-
平均吞吐量 (tokens/s):多次推理平均Token生成速度
-
平均显存 (MB):多次推理平均显存使用量,两卡相加
-
平均GPU使用率(%):多次推理平均GPU使用率,两卡相加
3090显卡和4090显卡在多卡模型推理过程中的显存和GPU使用率都比较接近,主要看平均耗时及平均吞吐量两个指标:
| Batch Size | 指标 | 双卡 3090 | 双卡 4090 | 对比 |
|---|---|---|---|---|
| 1 | 平均耗时(s) | 5.65 | 4.72 | |
| 1 | 平均吞吐量(tokens/s) | 45.3 | 54.3 | 119.9% |
| 4 | 平均耗时(s) | 6.15 | 4.81 | |
| 4 | 平均吞吐量(tokens/s) | 166.5 | 213.0 | 127.9% |
| 8 | 平均耗时(s) | 6.84 | 5.01 | |
| 8 | 平均吞吐量(tokens/s) | 291.9 | 398.7 | 136.6% |
| 16 | 平均耗时(s) | 8.28 | 5.47 | |
| 16 | 平均吞吐量(tokens/s) | 491.2 | 748.2 | 152.3% |
从平均耗时来看,4090在1~8并发度下耗时增加不多,性能接近线性增长,16并发度下面略微衰减;3090在1~8并发度下耗时逐步增加,并且在16并发度下耗时明显增大,性能衰减比4090更加明显。
平均吞吐量指标也能说明相应的情况,对比数据可以看出4090和3090在1~16的并发度下面,差异被逐渐拉大,16并发度下面4090的性能是3090的1.5倍左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号