
Ollama和vLLM大模型推理性能对比实测
 在部署大模型推理服务的时候,Ollama和vLLM是目前最常见的两个大模型部署工具,这里选择英伟达的RTX 3090比较Ollama和vLLM这两个工具在大语言模型推理场景下性能表现,使用Qwen3模型、控制同样的API推理参数,测试并发调用下的性能表现,来看看Ollama和vLLM分别适用于什么场景?
在部署大模型推理服务的时候,Ollama和vLLM是目前最常见的两个大模型部署工具,这里选择英伟达的RTX 3090比较Ollama和vLLM这两个工具在大语言模型推理场景下性能表现,使用Qwen3模型、控制同样的API推理参数,测试并发调用下的性能表现,来看看Ollama和vLLM分别适用于什么场景?
在部署大模型推理服务的时候,选择合适的部署工具可以让我们事半功倍,怎么在对应的场景下选择合适的部署工具,用于平衡部署的成本和推理的性能?
Ollama和vLLM是目前最常见的两个大模型部署工具,我们先问问DeepSeek看看这两个部署工具的功能特性,分别适用于什么场景?
Ollama和vLLM特性比较
| 特性维度 | Ollama | vLLM |
|---|---|---|
| 设计定位 | 开发者友好的本地体验工具 | 生产级的高性能推理引擎 |
| 架构特点 | 单体应用,内置模型管理 | 专注推理后端,需要API封装 |
| 核心技术 | 基于GGML/GGUF优化,CPU+GPU混合 | PagedAttention,连续批处理 |
| 易用性 | ⭐⭐⭐⭐⭐(极简) | ⭐⭐⭐(需要集成) |
| 性能 | ⭐⭐⭐(良好) | ⭐⭐⭐⭐⭐(卓越) |
| 生态系统 | ⭐⭐⭐⭐(丰富模型库) | ⭐⭐⭐⭐(工业标准) |
| 资源需求 | 相对较低 | 相对较高 |
| 适用场景 | 1. 个人开发与实验 2. 资源受限环境 3. 多模型管理需求 |
1. 高并发生产环境 2. 对吞吐量要求极高的场景 3. 企业级部署 |
这里选择英伟达的RTX 3090比较Ollama和vLLM这两个工具在大语言模型推理场景下性能表现,控制同样的模型、同样的API推理参数,并测试并发调用下的性能表现。
在GPU算力租用平台 晨涧云 分别租用3090显卡资源的Ollama和vLLM的云容器进行测试。
模型选择与参数控制
这里选择 Qwen3的模型进行测试,考虑到3090的显存是24GB,选择一个FP16精度的qwen3:8b模型进行测试。
借助DeepSeek 生成测试脚本,调整脚本控制变量:
-
使用复杂度近似的N个prompts;
-
MAX_TOKENS配置256,让每次请求需要一定的生成时长便于采样显卡的使用指标,减少波动; -
选择
[1, 4, 8, 16]4种BATCH_SIZES测试不同并发度下的性能表现; -
每轮测试执行3次推理,指标取平均;
-
同时需要模型预热,消除第一次推理响应延时过大的问题。
然后就可以执行推理性能测试脚本,查看输出结果。
Ollama推理性能

vLLM推理性能
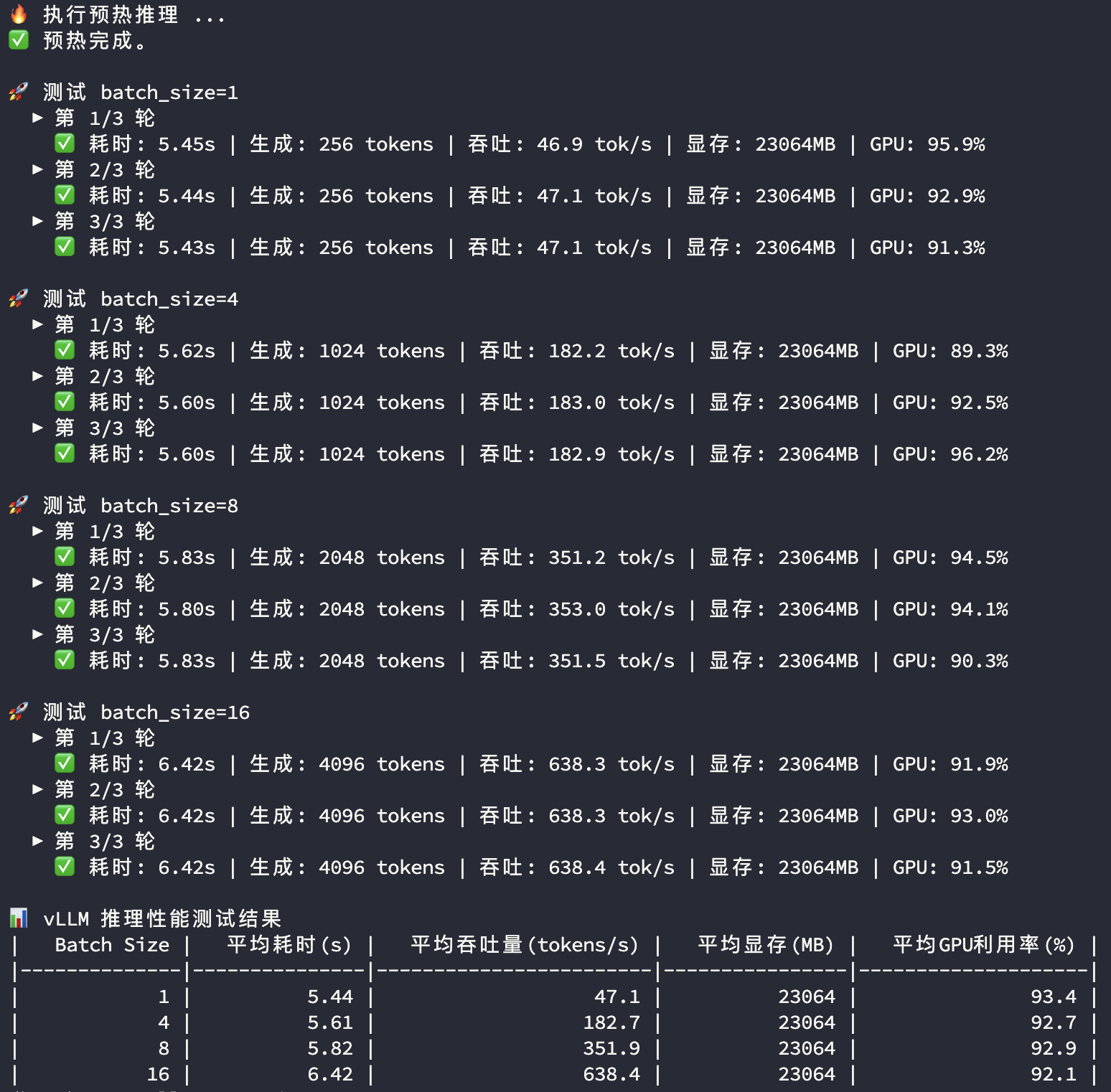
测试结果解释
-
Batch Size:一次推理调用的并发prompt数量
-
平均耗时 (s):多次推理平均响应时长
-
平均吞吐量 (tokens/s):多次推理平均Token生成速度
-
平均显存 (MB):多次推理平均显存使用量
-
平均GPU使用率(%):多次推理平均GPU使用率
vLLM的显存占用比Ollama略高,GPU使用率比较接近,主要比较平均响应时长及平均Token生成速度两个指标:
| Batch Size | 1 | 8 | 16 | |
|---|---|---|---|---|
| 响应时长(s) | Ollama | 5.68 | 7.64 | 15.6 |
| 响应时长(s) | vLLM | 5.44 | 5.82 | 6.42 |
| 响应时长(s) | 差异 | 104.4% | 131.3% | 243.0% |
| Token生成速度(tokens/s) | Ollama | 45.1 | 268.0 | 262.9 |
| Token生成速度(tokens/s) | vLLM | 47.1 | 351.9 | 638.4 |
| Token生成速度(tokens/s) | 差异 | 95.6% | 76.2% | 41.2% |
——Ollama的并发数量超过8之后有明显的性能瓶颈,调整 OLLAMA_NUM_PARALLEL 参数还是上不去,不知道是不是需要调整其他参数。
总体来说,顺序调用场景(Batch Size=1)Ollama和vLLM性能接近;并发调用场景vLLM的性能完胜,而且并发度越高的场景下vLLM的性能优势越明显。
这个测试基于单卡的推理场景,多卡下面并发调用的性能表现可能又会有差异。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号