JMeter 核心解读之正则表达式提取器组件实现关联上下文实战
1)实战步骤
- JMX 脚本解析:
- 添加 Thread Group (线程组)组件
- 添加 jp@gc - Dummy Sampler (虚拟模拟器)组件
- 添加 Regular Expression Extractor(正则表达式提取器)组件
- 添加 View Results Tree (察看结果树)组件
2)具体步骤
-
添加 Thread Group (线程组)组件,并默认填写
-
添加 jp@gc - Dummy Sampler (虚拟模拟器)组件,定义好返回信息

-
添加 JSON Extractor (JSON 提取器)组件
-
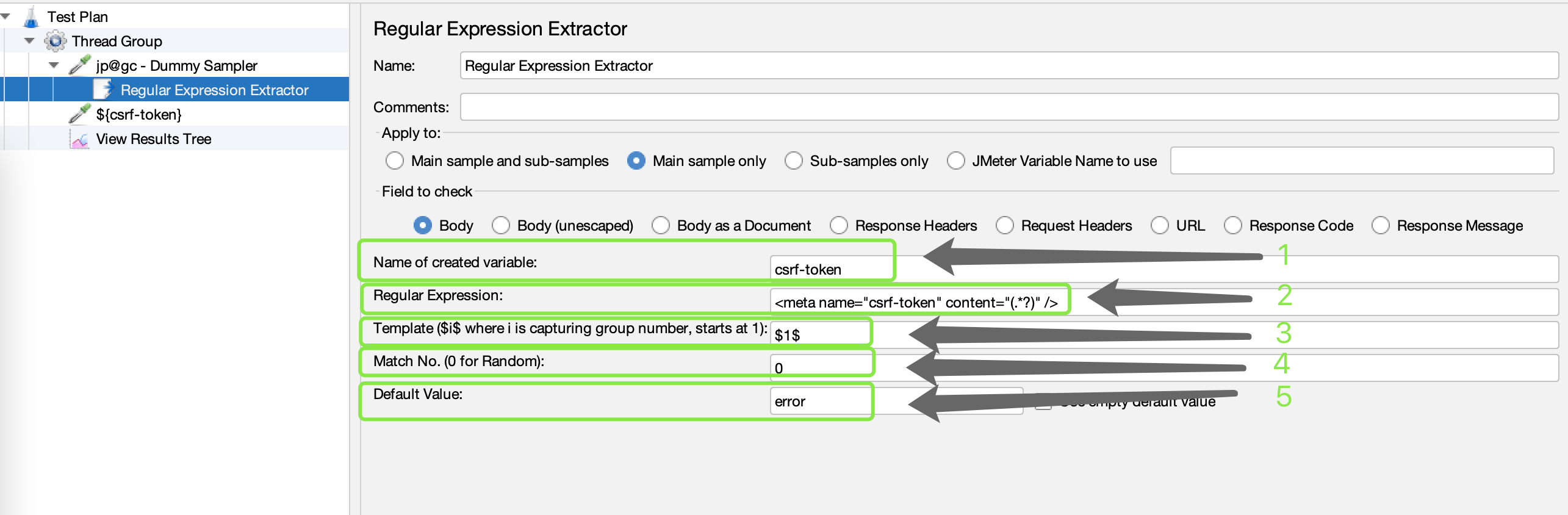
第一处 Names of created variables 表示需要输入变量名称,例如: csrf-token
-
第二处 Regular expressionn 表示需要输入 JSON 提取表达式,例如:*
<meta name="csrf-token" content="(.*?)" />-
正则表达式快速解析
()表示需要提取的内容,用来书写正则表达式
.表示匹配任何单个字符
?表示匹配 0 次或 1 次
*表示匹配 0 次或 多 次出现的字符
+表示匹配 1 次或 多 次出现的字符
^表示匹配行 开始 的空字符
$表示匹配行 结束 的空字符
\w表示匹配任意 字母、数字、下划线、汉字
\W表示匹配任意不是 字母、数字、下划线、汉字 的字符
\d表示任意 一个 数字 [0-9]
\d+表示匹配 一个 或 更多连续 的数字
\D表示匹配任意非数字的字符 [^0-9],相当于 \w
{N}表示精准匹配 N 次之前的字符
{N,}表示匹配之前的字符 N 次或者 更多 次
{N,M}表示匹配之前的字符 N 次,不大于 M 次- 正则表达式的贪婪模式:表示在正则表达式匹配成功下,尽可能多的匹配内容
- 正则表达式的非贪婪模式:表示在正则表达式匹配成功下,尽可能少的匹配内容 (推荐)
-
-
第三处 Template(
$i$where i is capturing group number, start at 1) 表示需要输入正则表达式解析模板,例如:- 如果只有一个正则表达式,则可输入
$1$ - 如果有两个正则表达式,则可输入
$1$,$2$ - 如果有多个正则表达式,则可输入
$1$,$2$;$3$
- 如果只有一个正则表达式,则可输入
-
第四处 Match No. (0 for Random) 表示需要输入匹配的编号,例如:
- 输出所有的值则输入:-1
- 随机输出一个值则输入:0
-
第五处 Default Values 表示需要输入提取不到值时候的输出值,例如:error
-
其他默认填写
-
-
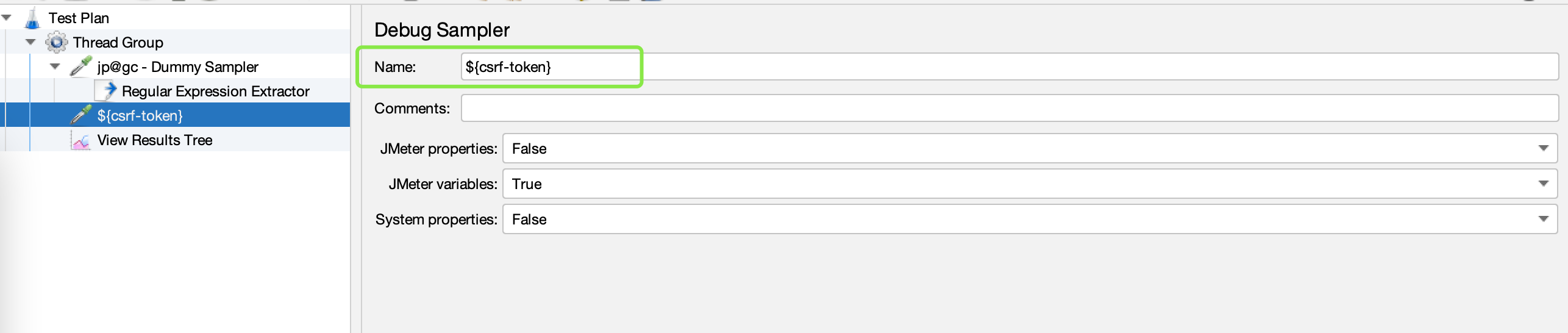
添加 Debug Sampler (调试取样器)组件,改为标题:
${csrf-token},易于查看调试结果
-
添加 View Results Tree (察看结果树)组件,查看执行结果
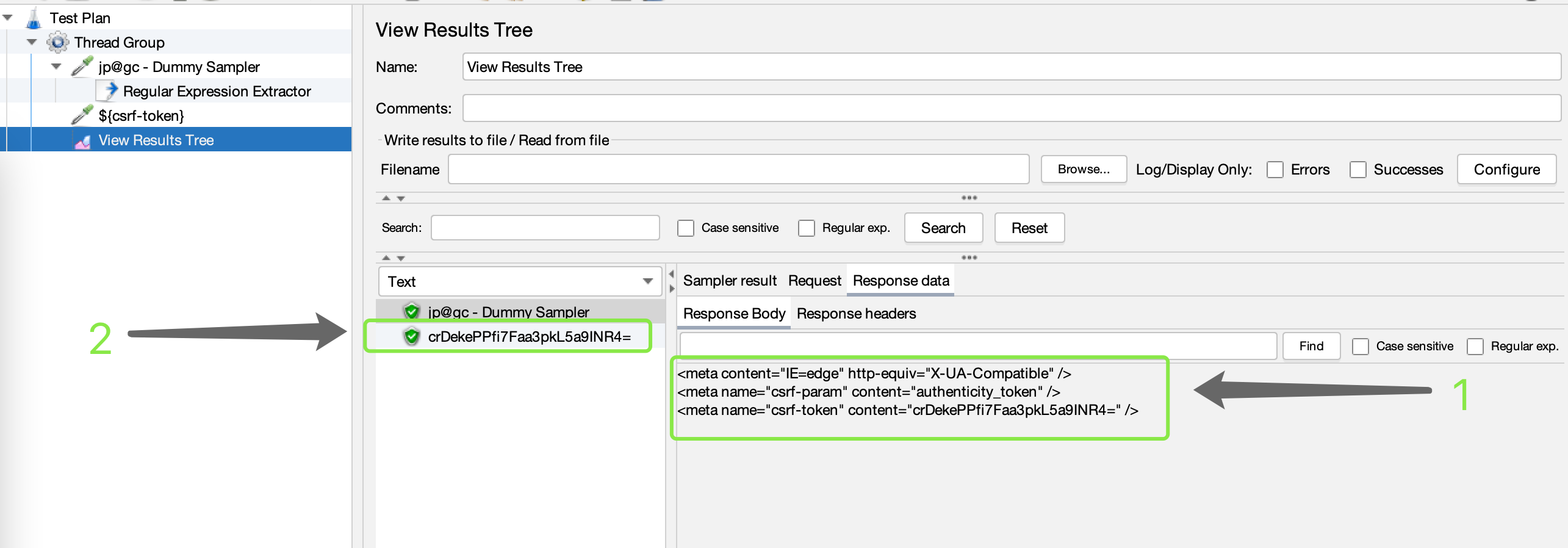
- 第一处表示输出的请求响应信息
- 第二处表示提取的 csrf-token 的值并打印输出
本文来自博客园,作者:那个曼巴,转载请注明原文链接:https://www.cnblogs.com/aharderbro/articles/15224314.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号