
raft协议数据结构和RPC设计
1. 状态机
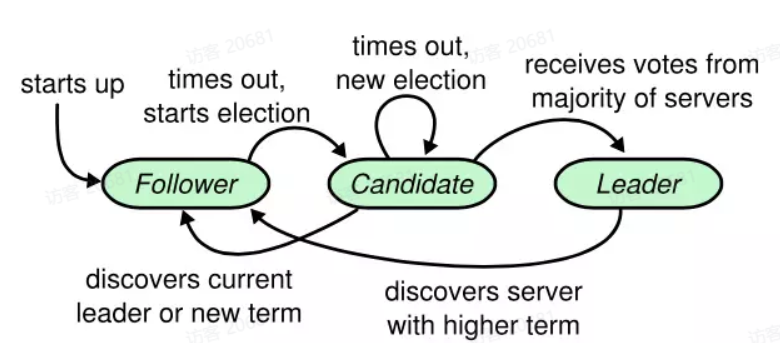
从中我们可以得到几个我们需要实现的过程
- 初始化所有节点为follower
- 需要一个选举超时定时器,当定时器超时时,一个follower状态转为candidate
- candidate向其他节点请求投票,得到半数以上票数成为leader
- candidate发现新的leader或者自己的term不够大时,转为follower
- leader在复制日志或者传递心跳的过程中,发现更新的term,会转为follower
2. 通用数据结构
不论是一个节点位于哪种形态,都必须具备这些数据结构,其中一些是该节点独有的信息,而更多是关于集群的日志同步相关的
| 参数 | 解释 |
| currentTerm | 服务器当前已知最新的term,初始化为0,单调增加 |
| voteFor | 当前任期内收到选票的候选人id,如果不投票则为-1 |
| NodeID | 当前节点在集群中的ID,全局唯一 |
| []log | 日志条目,每个条目包含了用于状态机的命令,以及领导者接收到该条目的term、index信息 |
| commitIndex | 已知已提交的最高的日志条目的索引(提交到大多数节点),单调递增 |
| lastApplied | 已经被应用到状态机的最高的日志条目的索引,单调递增 |
其实 commitIndex 和 lastApplied 可以看做是 []log 数组中的两个指针,表明了有多少日志被集群提交了,有多少已经被应用到状态机了
其实在这里可以发现,已经应用到状态机的日志是不必继续保存的,后面会有一个快照机制,既可以压缩数据又可以迅速向新节点同步数据
我们可以简单梳理一下 []log 的结构:
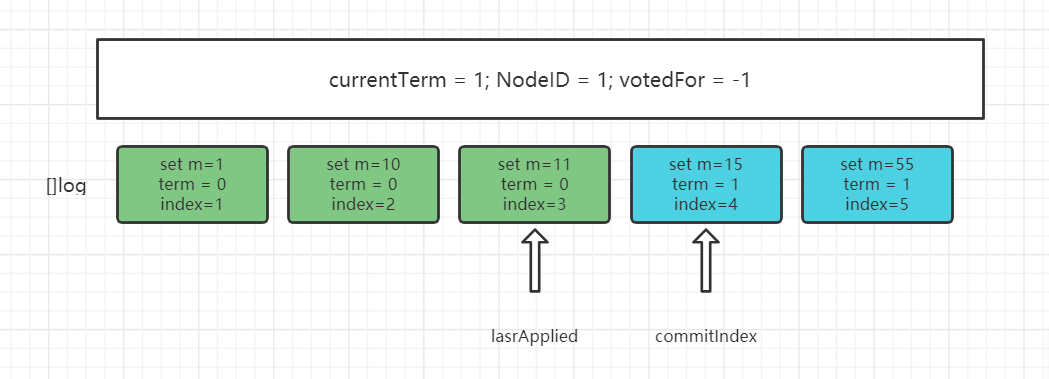
观察 []log 的结构,我们可以发现一个日志所包含的基础字段,分别是 command、term、index
term就是同步这条日志的 leader 的 term ,index是一个全局单调递增的数字,用于和 term 标识唯一的 leader,并配合 lastApplied 和 commitIndex 使用
那么 lastApplied和commitIndex 是什么关系呢?
lastAppiled <= commitIndex,二者中间日志就是已经提交到集群,但还没有应用到状态机的
这里就会有一个关于更新lastApplied的问题,当 lastApplied < commitIndex 时,lastApplied +1,并把 log[lastApplied] 应用到状态机
以上的这些数据基本都记录的是单机信息,raft 中最重要的日志同步,也就是 leader 向 follower 同步日志时需要怎么做呢?
其实每个 leader,或者说每个节点,因为每个节点都有可能成为 leader,都会存在两个数组,用于向 follower 同步日志
| 参数 | 解释 |
| []nextIndex | 对于每一台服务器,发送到该服务器的下一个日志条目的索引(初始值为领导者最后的日志条目索引+1) |
| []matchIndex | 对于每一台服务器,已知的已经复制到该服务器的最高日志条目的索引(初始值为0,单调递增) |
其实简单来说就是:对于每一个follower,leader应该知道它要发给这个节点哪些日志
3. RPC
最简单的 raft 算法实现需要两个RPC:日志追加/心跳RPC和选举投票RPC
其中日志追加RPC是由 leader 发送给 follower,选举投票RPC是由 candidate 发送给 candidate 和 follower
3.1 选举投票RPC
在选举定时器超时后,follower 会转为 candidate,然后开启选举投票RPC
这个RPC请求的关键是让其他节点给自己投票,那么需要的请求参数就必须要表明该 candidate有成为一个 leader 的资格
发起投票请求的简单逻辑如下:
- 选举定时器超时,follower转为candidate
- 新增当前自己的term currentTerm+=1
- 给自己的投票
- 重置选举超时定时器
- 发送投票请求RPC
- 如果收到了大多数服务器的选票,则成为新的 leader
- 如果收到了返回信息中发现更大了 term 或者直接收到 leader 的心跳或者日志RPC,则转为 follower
- 如果选举过程超时,再次发起一轮选举
candidate 的请求参数主要包括了:
| 参数 | 解释 |
| term | candidate的任期号 |
| candidateID | candidate的ID |
| lastLogIndex | 候选人的最新日志条目的索引值 |
| lastLogTerm | 候选人最新日志条目的任期号 |
在其他节点收到投票请求后,主要会做一下term和index的校验:
- 检查自己的 voteFor 是否等于-1,如果是表示已经投过票了,拒绝投票请求
- 检查 term 是否比自己的 term 新,如果不是表示 candidate 没有资格成为新的 leader,因为集群中已经存在比它数据更新的节点了
- 检查lastLogTerm,如果自己最新日志的 term 比candidate 的大,说明自己的日志更新,拒绝投票
- 检查lastLogIndex,在lastLogTerm相等时检查,如果自己的 index 比 candidate 的大,说明自己有更新的数据,拒接投票
- 所有的检查完毕,为 candidate 投上宝贵一票,同时更新自己的 term 为 candidate 的 term
那么响应结构应该怎么设计?最简单的响应只需要两个返回值
| 参数 | 解释 |
| term | 当前任期号,以便于candidate发现更大的term从而转为follower,不要影响投票 |
| voteGranted | 是否为该candidate投票 |
3.2 日志追加和心跳RPC
日志追加和心跳可以何合为一个RPC是因为当日志中没有 command 就可以当成心跳来发送
leader 调用该RPC的时机主要有以下几个情况:
- 客户端发起写请求
- 发送心跳
- 日志匹配失败
下面只简单说一下日志追加的过程
- 一旦成为 leader,发送空的附加日志RPC给其他所有的服务器,在一定的空余时间之后不停地重复发送,阻止 follower 选举定时器超时
- 如果接收到客户端写请求,附加条目到本地日志中,在条目被应用到状态机后响应客户端
- 如果对一个跟随者,最后日志条目的索引大于或者等于 nextIndex,那么 leader 会发送从nextIndex开始的所有日志条目
- 如果成功,更新 follower 的nextIndex 和 matchIndex
- 如果因为日志不一致而失败,减小 nextIndex 重试
- 如果存在一个满足 N > commitIndex 的 N,并且大多数的matchIndex[i] >= N 成立,并且 log[N].term == currentTerm 成立,那么令 commitIndex等于这个N
在请求参数中,需要包含以下几个部分:
| 参数 | 解释 |
| term | 当前leader的任期 |
| leaderID | 当前leader的id,主要用于跟随者对客户端进行重定向 |
| prevLogIndex | 紧邻新日志条目之前的那个条目的索引 |
| prevLogTerm | 紧邻新日志条目之前的那个条目的任期 |
| []entries | 需要被保存的日志条目 |
| leaderCommit | 领导者的已知已提交的最高的日志条目的索引 |
当 follower 收到日志追加或者心跳RPC时,会进行日志相关的操作
- 如果 leader 的任期小于自己,那么返回自己的任期,并拒绝日志,之后就会开始新一轮的 leader 选举了
- 在 follower 日志中,如果能找到一个和 prevLogIndex 和 prevLogTerm 匹配的日志条目,则继续执行,否则拒绝日志,做冲突处理
- 如果一个已经存在的条目和新条目发生了冲突,则删除这个已经存在的条目以及它之后的所有条目
- 追加日志中尚未存在的任何新条目
- 如果 leader 的已知的已经提交的最高日志索引 leaderCommit 大于自己的,则 follower 把已知的已经提交的最高日志条目索引 commitIndex重置为 leaderCommit和最新日志条目索引的最小值
所以在响应结构的设计中,主要包括了以下几部分:
| 参数 | 解释 |
| term | 当前已知的最大任期 |
| success | 是否匹配index和term,并接受了日志 |
| conflictLogIndex | 和prevLogIndex不匹配的的log index |
| conflictLogTerm | 和prevLogTerm不匹配的的log term |
至此通过两个RPC,就可以实现一个简单的raft协议
4. 工程优化
(1)平均故障时间大于信息交换时间,系统没有一个稳定的领导者,集群不可用
解决:广播时间 << 心跳超时时间 << 平均故障时间
(2)多个candidate同时发起选举RPC,选票被瓜分
解决:给选举定时器加上一个随机数,将超时时间分散
(3)客户端如何知道哪个节点是 leader?
解决:客户端不需要知道leader节点,如果其写请求是发给了 follower,follower会重定向给leader节点
(4)客户端从少数节点读取未同步的信息?
解决:每个客户端应该维护一个latestIndex值,每个节点在接受读请求时与自己的lastApplied值比较,如果这个值大于自己的lastApplied,那么就会拒绝这次读请求,客户端做重定向到一个可读的节点
(5)快照
(6)apply和commit异步处理,提高client的并发性
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号