
docker底层原理
1. Docker底层技术支撑
Linux 命令空间、控制组和UnionFS三大技术支撑了目前Docker的实现:
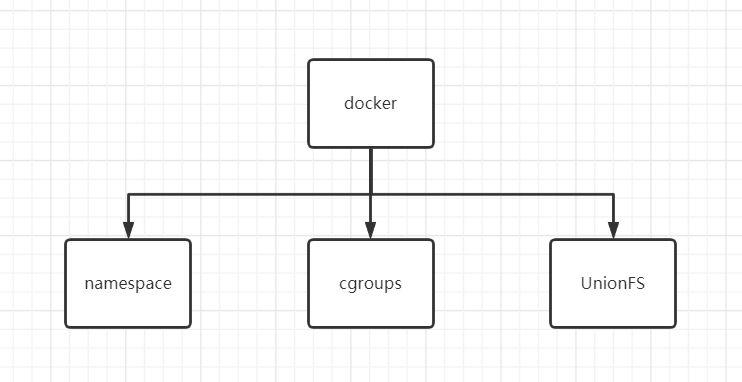
- namespace命名空间:容器隔离的基础,保证A容器看不到B容器
- cgroups控制组:容器资源统计和隔离
- UnionFS联合文件系统:分层镜像实现的基础
实际上Docker使用了很多Linux的隔离功能,让容器看起来是一个轻量级的虚拟机在独立运行,容器的本质就是被限制了namespace和cgroup,具有逻辑上独立的独立文件系统的一个进程
2. namespce
在Linux系统中,namespace是在内核级别以一种抽象的形式来封装系统资源,通过将系统资源放在不同的namespace中,来实现资源隔离的目的
不同的namespace程序,都可以拥有一份独立的系统资源
namespace是linux为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法
Linux的namespace机制提供了以下七种不同的命名空间,包括:
- CLONE_NEWCGROUP
- CLONE_NEWIPC:隔离进程间通信
- CLONE_NEWNET:隔离网络资源
- CLONE_NEWNS:隔离文件系统挂载点
- CLONE_NEWPID:隔离进程PID
- CLONE_NEWUSER
- CLONE_NEWUTS:隔离主机名和域名信息
docker使用的是PID隔离
2.1 PID隔离
如果现在在宿主机上启动两个容器,在这两个容器内各自都有一个PID=1的进程,但是众所周知,PID在linux中是唯一的,那么两个容器是怎么做到同时拥有PID=1的不同进程的?
本来,每当我们在宿主机上运行一个/bin/sh程序,操作系统就会分配给他一个PID,这个PID是进程的唯一标识,而PID=1的进程是属于 /sbin/init 的
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Mar21 ? 00:00:03 /sbin/init noibrs splash
root 2 0 0 Mar21 ? 00:00:00 [kthreadd]
root 4 2 0 Mar21 ? 00:00:00 [kworker /0 :0H]
root 6 2 0 Mar21 ? 00:00:00 [mm_percpu_wq]
root 7 2 0 Mar21 ? 00:00:11 [ksoftirqd /0 ]
什么是/sbin/init?这个进程是被linux中的上帝进程 idle 创建出来的,主要负责执行内核的一部分初始化工作和系统配置,也会创建一些类似于 getty 的注册进程
现在我们通过docker在容器运行 /bin/sh 就会发现PID=1的进程其实就是我们创建的这个进程,而不再是宿主机上那个 /sbin/init
UID PID PPID C STIME TTY TIME CMD
mysql 1 0 0 Mar21 ? 00:10:24 mysqld
root 86 0 0 09:14 pts /0 00:00:00 /bin/bash
root 429 86 0 10:15 pts /0 00:00:00 ps -ef
这种技术就是linux的 PID namespace隔离
namespace的使用就是linux在创建进程的一个可选参数
我们知道,在linux中创建进程的系统调用是clone()方法:
int pid = clone(main_function, stack_size, SIGCHLD, NULL)
这个系统调用会为我们创建个新的进程,并返回它的PID
当我们使用clone()系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL)
此时,新创建的这个进程就是一个隔离的进程,它看不到宿主机上的任何进程
实际上,docker容器的pid隔离,就是在使用clone()创建新进程时传入CLONE_NEWPID来实现的,也就是使用linux的命名空间来实现进程的隔离,docker容器内部的任意进程都对宿主机的进程一无所知
每次当我们运行 docker run 时,都会在下面的方法中创建一个用于设置进程间隔离的spec:
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf( "linux spec namespaces: %v" , err)
}
return &s, nil
}
在setNamespaces方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC以及UTS相关的命名空间:
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error {
// user
// network
// ipc
// uts
// pid
if c.HostConfig.PidMode.IsContainer() {
ns := specs.LinuxNamespace{Type: "pid" }
pc, err := daemon.getPidContainer(c)
if err != nil {
return err
}
ns.Path = fmt.Sprintf( "/proc/%d/ns/pid" , pc.State.GetPID())
setNamespace(s, ns)
} else if c.HostConfig.PidMode.IsHost() {
oci.RemoveNamespace(s, specs.LinuxNamespaceType( "pid" ))
} else {
ns := specs.LinuxNamespace{Type: "pid" }
setNamespace(s, ns)
}
return nil
}
所有命名空间相关得设置Spec最后都会作为Create函数的入参在创建新容器时进行设置:
daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
PID namespace隔离非常实用,它对进程PID重新标号,即两个不同namespace下的进程可以有同一个PID
每个PID namespace都有自己的计数程序。内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,我们称之为root namespace
他创建的新PID namespace就称之为child namespace(树的子节点),而原先的PID namespace就是新创建的PID namespace的parent namespace(树的父节点)
通过这种方式,不同的PID namespace会形成一个等级体系,所属的父节点可以看到子节点中的进程,并可以通过信号灯等方式对子节点中的进程产生影响
但是子节点不能看到父节点PID namespace 中的任何内容
- 每个PID namespace 中的第一个进程 PID=1,就会像传统linux进程中的init一样,起特殊作用
- 一个namespace中的进程,不可能通过 kill 或者 ptrace影响父节点或者兄弟节点中的进程
- 如果在新的PID namespace中重新挂载/proc文件系统,会发现其下只显示同属一个PID namespace中的其他进程
- 在root namespace中可以看到所有的进程,并且递归包含所有子节点中的进程
2.2 其它的操作系统基础组件隔离
不仅仅是PID,当启动容器之后,docker会为这个容器创建一系列其他namespaces
这些 namespaces 提供了不同层面的隔离,容器运行会受到各个层面 namesapce 的限制
Docker Engine 使用了以下 Linux 的隔离技术:
The pid namespace: 管理 PID 命名空间 (PID: Process ID)
The net namespace: 管理网络命名空间(NET: Networking)
The ipc namespace: 管理进程间通信命名空间(IPC: InterProcess Communication)
The mnt namespace: 管理文件系统挂载点命名空间 (MNT: Mount)
The uts namespace: Unix 时间系统隔离. (UTS: Unix Timesharing System)
通过这些技术,运行时的容器得以看到一个和宿主机上其他容器隔离的环境
3. cgroups
cgroups是linux内核中用来为进城设置资源闲置的一个重要功能
cgroups最主要的功能就是限制一个进程组能够使用的资源上限,包括CPU、内存、磁盘、网络带宽等
此外,cgroups还能对进程进行优先级设置、审计,以及将进程挂起和恢复等操作
linux使用文件系统来实现cgroups,我们可以直接使用命令来查看当前的cgroup有哪些子系统:
root@root:~ $ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/net_cls ,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpu ,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
可以看到,在/sys/fs/cgroup下面有很多诸如cpuset、cpu、memory这样的子目录,这些就是可以被cgroups限制的资源种类
而在子目录对应的资源种类下,可以看到这类资源具体可以被限制的方法,例如CPU:
root@root:~ $ ls /sys/fs/cgroup/cpu
aegis cgroup.sane_behavior cpuacct.usage_percpu cpuacct.usage_user cpu.stat system.slice
assist cpuacct.stat cpuacct.usage_percpu_sys cpu.cfs_period_us docker tasks
cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_user cpu.cfs_quota_us notify_on_release user.slice
cgroup.procs cpuacct.usage_all cpuacct.usage_sys cpu.shares release_agent
我们可以看到其中有一个docker文件夹,cd到docker文件下
其中四个带有序号的文件夹其实就是我们docker中目前运行的四个容器,启动这个容器时,docker会为这个容器创建一个与容器标识符相同的cgroup,在当前主机上cgroup就会有以下层级关系:
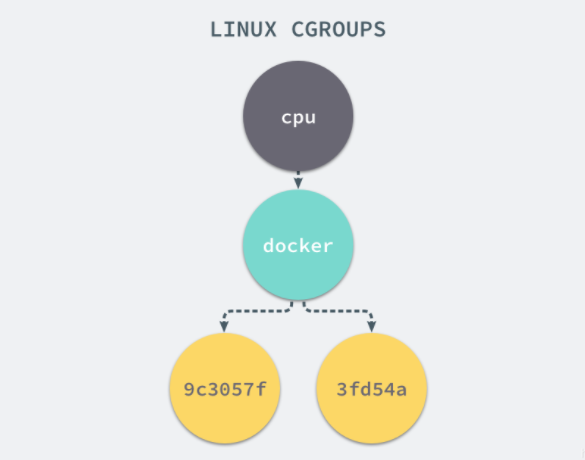
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统
cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%
如果系统管理员想要控制 Docker 某个容器的资源使用率就可以在 docker 这个父控制组下面找到对应的子控制组并且改变它们对应文件的内容,当然我们也可以直接在程序运行时就使用参数,让 Docker 进程去改变相应文件中的内容
当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除,Docker 在使用 CGroup 时其实也只是做了一些创建文件夹改变文件内容的文件操作,不过 CGroup 的使用也确实解决了我们限制子容器资源占用的问题,系统管理员能够为多个容器合理的分配资源并且不会出现多个容器互相抢占资源的问题
除了CPU子系统外,cgroups的每一项子系统都有其独有的资源限制能力:
- blkio:为块设备设定I/O限制,一般用于磁盘等设备
- cpuset:为进程分配单独的CPU核和对应的内存节点
- memory:为进程设定内存使用限制
linux cgroups的设计简单而言,就是一个子系统目录上加上一组资源限制文件的组合。而对于docker等linux容器项目来说,它们只需要在每个子系统下面为每个容器创建一个控制组,然后在启动容器进程之后,把这个进程的PID填写到对应控制组的tasks文件中即可。
至于在这些控制组下面的资源文件里填什么值,就是用户执行docker run 时指定的参数,例如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu- quota =20000 ubuntu /bin/bash
在启动这个容器后,就可以通过查看其资源文件的内容来确认具体的资源限制,这意味着这个docker容器只能使用20%的cpu带宽
4. UnionFS
UnionFS其实是一种为linux操作系统设计的用于把多个文件系统联合到同一个挂载点的文件系统服务
首先,我们建立company和home两个目录,并且分别为他们创建两个文件:
$ tree .
.
|-- company
| |-- code
| `-- meeting
`-- home
|-- eat
`-- sleep
然后我们将通过mount命令把company和home两个目录联合起来,建立一个AUFS的文件系统,并挂载到当前目录下的mnt目录:
$ mkdir mnt
$ ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 4 root root 4096 Oct 25 16:05 home/
drwxr-xr-x 2 root root 4096 Oct 25 16:10 mnt/
$ mount -t aufs -o dirs=./home:./company none ./mnt
$ ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 6 root root 4096 Oct 25 16:10 home/
drwxr-xr-x 8 root root 4096 Oct 25 16:10 mnt/
root@rds-k8s-18-svr0:~ /xuran/aufs # tree ./mnt/
. /mnt/
|-- code
|-- eat
|-- meeting
`-- sleep
4 directories, 0 files
通过 ./mnt 目录结构的输出结果,可以看到原来两个目录下的内容被合并到了一个mnt目录下
默认情况下,如果我们不对联合的目录指定权限,内核将根据从左到右的顺序将第一个目录指定为可读可写,其余的都为只读
那么,当我们向只读的目录做一些写入操作的话,会发生什么呢?
$ echo apple > ./mnt/code
$ cat company/code
$ cat home/code
apple
通过对上面代码短的观察,可以看出当写入操作发生在company/code 文件时,对应的修改并没有反映到原始的目录中,而是在home目录下又创建了一个名为code的文件,并将apple写了进去
这就是Union File System:
- Union File System联合了多个不同的目录,并且把他们挂载到一个统一的目录上
- 在这些联合的子目录中,有一些是读写的,但有一部分是只读的
- 当对只读的目录内容做出修改时,其结果只会保存在可写的目录下,不会影响只读目录
这就是docker镜像分层技术的基础
4.1 docker镜像分层
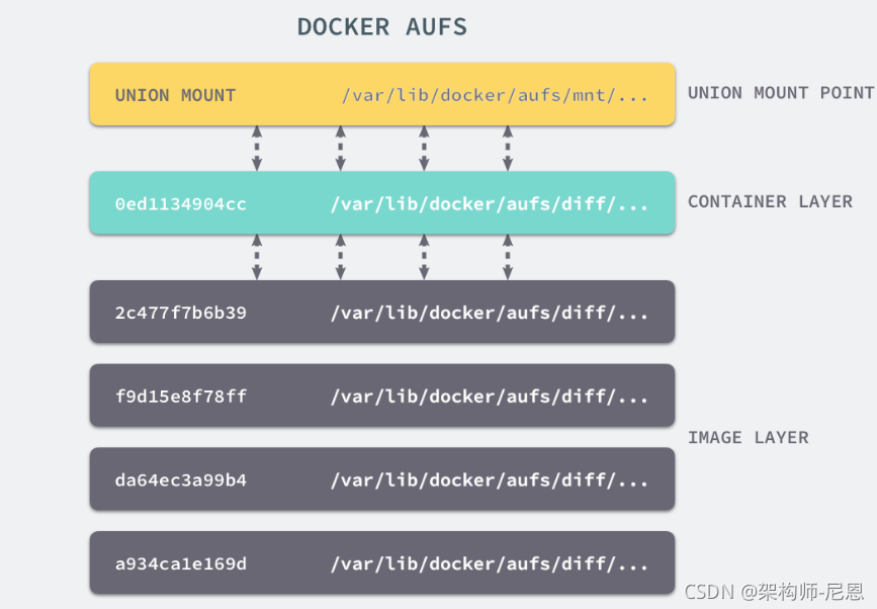
docker image有一个层级结构,最底层的layer为 baseimage(一般为一个操作系统的ISO镜像),然后顺序执行每一条指令,生成的layer按照入栈的顺序逐渐累加,形成一个image
每一层都是一个被联合的目录,大致如下图所示:
4.2 Dockerfile
简单来说,一个image是通过一个dockerfile来定义的,然后使用docker build命令构建它
dockerfile中的每一条指令的执行结果都会成为image中的一个layer
简单看一个dockerfile的内容,观察image分层机制:
# Use an official Python runtime as a parent image
FROM python:2.7-slim
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
# Run app.py when the container launches
CMD ["python", "app.py"]
构建结果:
root@rds-k8s-18-svr0:~/xuran/exampleimage# docker build -t hello ./
Sending build context to Docker daemon 5.12 kB
Step 1/7 : FROM python:2.7-slim
---> 804b0a01ea83
Step 2/7 : WORKDIR /app
---> Using cache
---> 6d93c5b91703
Step 3/7 : COPY . /app
---> Using cache
---> feddc82d321b
Step 4/7 : RUN pip install --trusted-host pypi.python.org -r requirements.txt
---> Using cache
---> 94695df5e14d
Step 5/7 : EXPOSE 81
---> Using cache
---> 43c392d51dff
Step 6/7 : ENV NAME World
---> Using cache
---> 78c9a60237c8
Step 7/7 : CMD python app.py
---> Using cache
---> a5ccd4e1b15d
Successfully built a5ccd4e1b15d
通过构建可以看出,构建的过程就是执行Dockerfile文件中我们写入的命令
构建一共进行了7个步骤,每个步骤执行完都会生成一个随机的ID来标识这一layer的内容,最后一行的 a5ccd4e1b15d 为镜像的ID
通过了解了 Docker Image 的分层机制,可以看出Layer 和 Image 的关系与 AUFS 中的联合目录和挂载点的关系比较相似
参考:
Docker底层原理(图解+秒懂+史上最全) - 疯狂创客圈 - 博客园 (cnblogs.com)
https://blog.csdn.net/wangqingjiewa/article/details/85000393
https://zhuanlan.zhihu.com/p/47683490
https://blog.csdn.net/weixin_37098404/article/details/102704159
《深入剖析Kubernetes》 张磊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号