分布式系统理论和方案总结
1、分布式理论
1、CAP理论
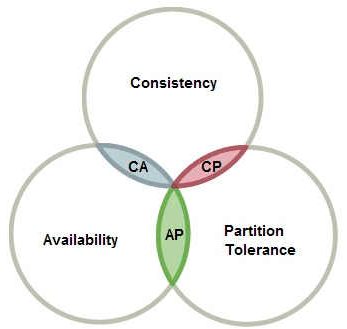
CAP理论指的是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
一致性,分布式系统中的服务的同一个信息的状态是一致的
可用性,只要用户请求,服务就需要给出响应
分区容错性,大多数分布式系统都分布在多个子 网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
CAP理论表明一个系统最多只能同时满足两个特性,而一般分区容错性是一定满足的。所以都是在一致性和可用性上进行取舍。类似于Zookeeper就是舍弃了可用性选择了分区容错性和一致性。因为Zookeeper在follower和Leader挂掉的时候会进行重新选举,在选举的时候集群就无法被访问。而Netflix的Eureka就是相反选择了可用性,只保证了最终一致性。其实在服务发现治理中,Eureka这样的作法更符合使用常见。
保障CP

在电商购买服务中,下订单时往往会调用卡劵服务进行扣除,如果此时订单服务和卡券服务出现了调用超时或者是连接不通时,在保障CP时,会让交易失败从而保障订单服务和卡券服务的数据一致性。
保障AP
上述的购买情形如果是在AP下,订单服务的购买是可以继续的,但是卡券并没有修改。而是等到卡券服务正常的时候自动去扣除。典型如手机抢购场景,几秒前可以看到手机的数量不为0,等点击进去的时候系统提示下单失败,商品已经售罄。这是用可用性来保证系统方面的可用性服务,在数据的正确性上做出牺牲。虽然会影响一些用户体验但是不至于对用户购买流程造成阻塞。
2、BASE理论
BASE理论是对于CAP理论中的一致性和可用性无法做到兼得的一种权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的核心思想是,即使无法做到强一致性,单每个应用都可以结合自身的特点采用适当的方式来使系统达到最终一致性
- BA(Basic Availability 基本业务可用性)
- S(Soft state 柔性状态)
- E(Eventual consistency 最终一致性)
基本可用
分布式系统在出现不可预知的错误时,允许损失部分可用性,保持系统的基本功能可用。
损失响应时间
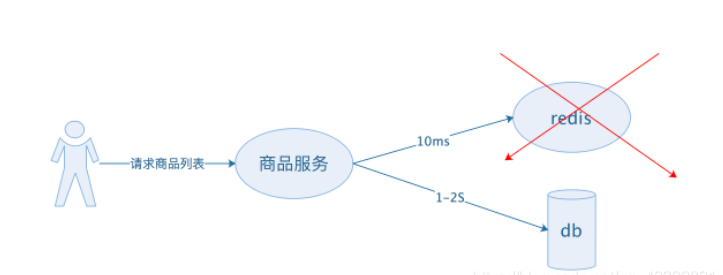
如上图,当Redis服务不可用时,可以直接通过数据库来查询,数据库的响应速度要比Redis肯定要慢一些,但是这样可以保证服务基本可用。
损失部分系统功能
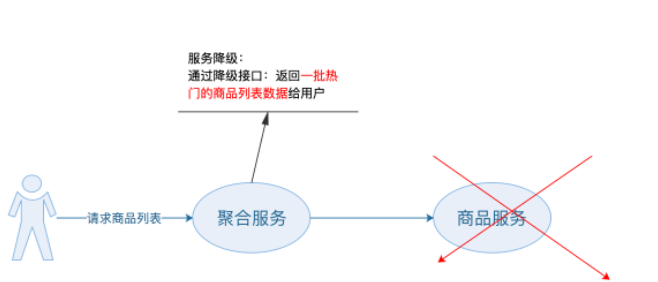
如图示,当请求量过大时,服务暂时不可用,可以通过展示降级页面给用户。
软状态
与之对应的硬状态就是要求多个副本的数据都是一致的,软状态指的是 允许系统中存在中间状态。并认为该状态不影响系统整体的可用性,即系统允许在不同节点的数据副本存在数据延时。
硬状态
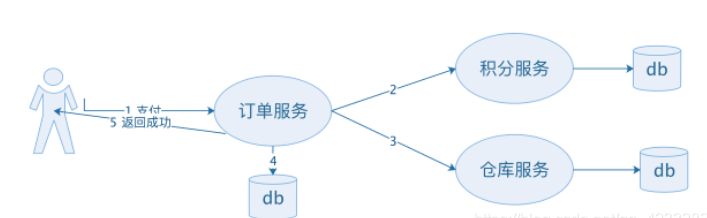
用户点击支付后会顺序的操作3个DB,三者同时成功才能算一个事务完成,即满足ACID强一致性。
软状态
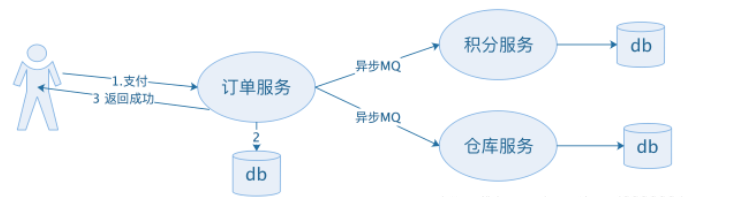
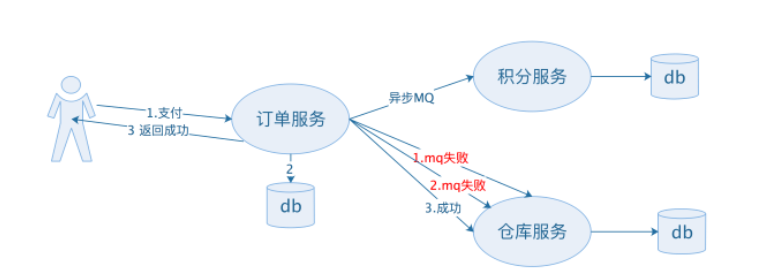
在分布式系统中,很多时候订单服务,积分服务,仓库服务都是不同的微服务,这个时候就不能当作一个数据库的事务了,这个时候可以将请求放入到MQ中,然后等待其他微服务消费MQ中的请求。而在其他微服务尚未消费时,订单服务就已经将订单的状态变成支付成功并返回给了用户。这个时候订单服务,积分服务,仓库服务中的订单状态并不一致。
最终一致性
软状态不可能一直是软状态,会有一个时间期限。在期限时间过后所有的系统中的状态都是一致的。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。
2、分布式选举协议
主节点,在一个分布式集群中负责对其他节点的协调和管理,也就是说,其他节点都必须听 从主节点的安排。 主节点的存在,就可以保证其他节点的有序运行,以及数据库集群中的写入数据在每个节点 上的一致性。这里的一致性是指,数据在每个集群节点中都是一样的,不存在不同的情况。
当然,如果主故障了,集群就会天下大乱,就好比一个国家的皇帝驾崩了,国家大乱一样。 比如,数据库集群中主节点故障后,可能导致每个节点上的数据会不一致。 这,就应了那句话“国不可一日无君”,对应到分布式系统中就是“集群不可一刻无主”。 总结来说,选举的作用就是选出一个主节点,由它来协调和管理其他节点,以保证集群有序 运行和节点间数据的一致性。

Bully 协议
Bully算法是一种霸道的集群选主算法,为什么说是霸道呢?因为它的选举原则是“长 者”为大,即在所有活着的节点中,选取 ID 最大的节点作为主节点。 在Bully算法中,节点的角色有两种:普通节点和主节点。 初始化时,所有节点都是平等 的,都是普通节点,并且都有成为主的权利。但是,当选主成功后,有且仅有一个节点成为 主节点,其他所有节点都是普通节点。当且仅当主节点故障或与其他节点失去联系后才会重新选主。
触发条件
- 比主节点ID大的节点加入集群
- 主节点失去响应
优点:实现简单,算法复杂度低,选举速度快
缺点:每个节点需要存储所有的节点信息,存储量较大。节点故障恢复可能导致多次主从切换
在
mongoDB中就采用了Bully算法
Bully协议有三种消息:
Election发起选举Alive对选举消息做应答Victory发布竞选成功消息
具体流程
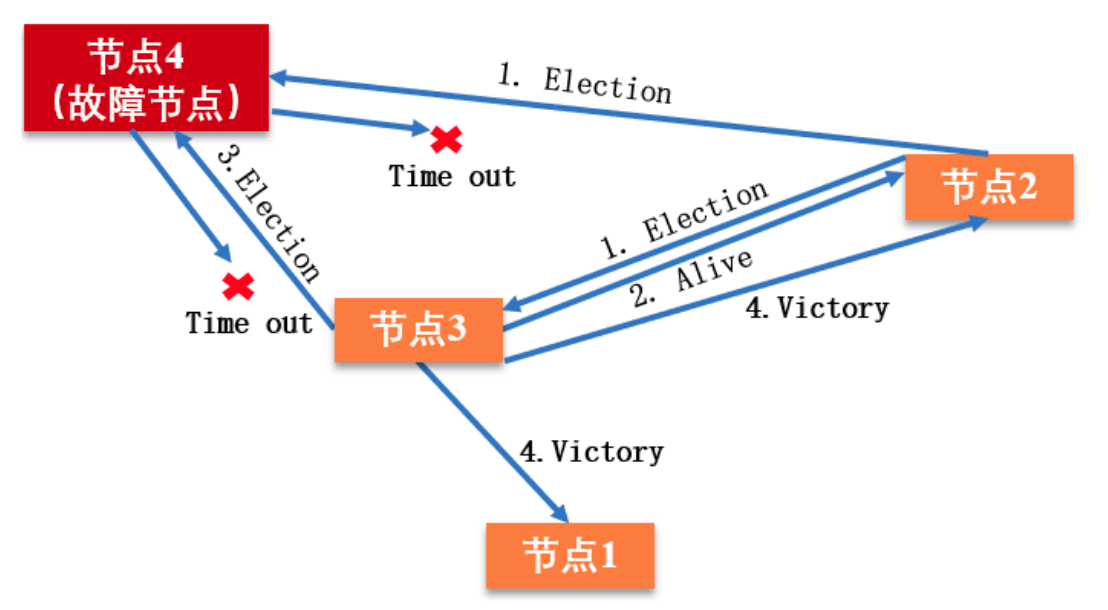
Bully 算法选举的原则是“长者为大”,意味着它的假设条件是,集群中每个节点均知道其 他节点的 ID。
- 集群中每个节点判断自己的ID是否为当前活着的最大的,如果是直接向其他节点发送
Victory - 如果当前节点不是活着的最大节点,则向比自己ID大的节点发送
election消息,等待回应 - 若等待一定时间没有任何节点回应消息则向所有节点发送
victory消息宣布自身为头结点,若收到其他节点的alive消息则等待其他节点竞选成功 - 若本节点收到比自己 ID 小的节点发送的
Election消息,则回复一个Alive消息
Gossip协议
Gossip protocol也叫Epidemic Protocol(流行病协议),实际上它还有很多别名,比如:“流言算法”、“疫情传播算法”等。这个协议的作用就像其名字表示的意思一样,非常容易理解,它的方式其实在我们日常生活中也很常见,比如电脑病毒的传播,森林大火,细胞扩散等等。
Gossip过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。在
Redis Cluster上应用了Gossip协议
动画示意图:
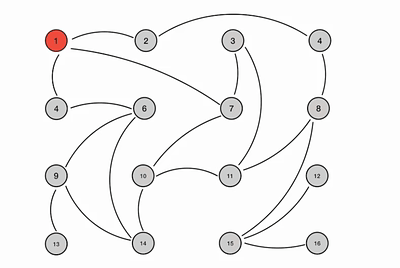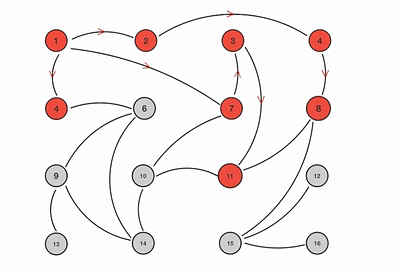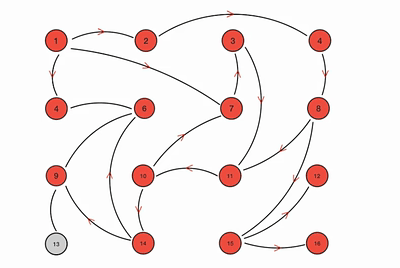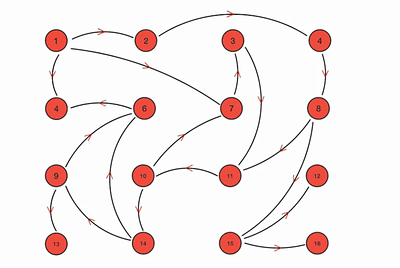
优点:
- 扩展性,网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
- 容错,网络中任何节点的宕机和重启都不会影响
Gossip消息的传播,Gossip协议具有天然的分布式系统容错特性。 - 去中心化,
Gossip协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。 - 简单,
Gossip协议的过程极其简单,实现起来几乎没有太多复杂性
缺点:
- 消息延迟,在
Gossip协议中每个节点扩散只会随机几个少量节点发送消息,消息最终是由多次扩散完成一致性。因此Gossip协议造成不可避免的消息延迟。 - 消息冗余,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余。
运行描述:
1、Gossip 是周期性的散播消息,把周期限定为 1 秒
2、被感染节点随机选择 k 个邻接节点(fan-out)散播消息,这里把 fan-out 设置为 3,每次最多往 3 个节点散播。
3、每次散播消息都选择尚未发送过的节点进行散播
4、收到消息的节点不再往发送节点散播,比如 A -> B,那么 B 进行散播的时候,不再发给 A。
Gossip类型
- Anti-Entropy(反熵),以固定的概率传播所有的数据。会造成数据量传输的开销较大,但是最终能达到一致性
- Rumor-Mongering(谣言传播):仅传播新到达的数据。消息只包含最新 update,体积更小。而且,一个
Rumor消息在某个时间点之后会被标记为removed,并且不再被传播,因此,Rumor-Mongering 下,系统有一定的概率会不一致。
Raft 协议
Raft 算法是典型的多数派投票选举算法,其选举机制与我们日常生活中的民主投票机制类 似,核心思想是“少数服从多数”。也就是说,Raft 算法中,获得投票最多的节点成为主。Google 开源的
Kubernetes就是采用Raft协议选主的。 集群中的角色有三种
Leader主节点,负责管理和协调其他节点Candidate候选者,在该角色状态下才可以被选举为新的LeaderFollower跟随者,不可以发起选举触发条件
- Leader节点任期到了
- Leader节点失去响应
优点:有选举速度快、算法复杂度低、易于实现。可以解决
Bully协议中的节点恢复导致主从切换的痛点缺点:集群内的所有节点需要互相通信,通信量大
具体流程
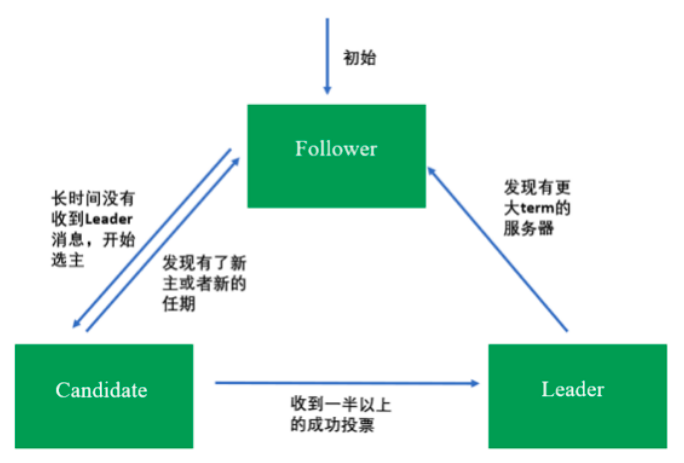
- 初始化时所有节点都是
follower - 开始选举时,所有节点从
follower转为candidate状态,并向其他节点发送选举请求 - 根据接收到的选举请求的先后顺序,回复是否同意成为主。在每一轮选举中,一个节点只能投出一张票。(需要对比请求节点的term和index是否比当前节点要旧,如果是 则拒绝投票)
- 若发起选举的节点的得票数超过了集群的半数则超过选举为
leader,其他节点由candidate变成follwer,Leader节点与Follower节点之间会 定期发送心跳包,以检测主节点是否活着。当选举未产生结果则说明没有选举大多数选票的节点,则随机超时一个candidate将term加一,并展开新的选举 - 当
Leader的任期到了会进行下一轮的选举
ZAB 协议
ZAB(
ZooKeeper Atomic Broadcast)选举算法是为了ZK实现分布式协调功能设计的,相较于Raft算法的投票机制,ZAB算法增加节点ID和数据ID作为选主参考,节点ID和数据ID越大数据越新。简而言之就是Raft算法的改进。角色:
- Leader 主节点
- Follower 跟随者节点
- Observer 观察者,无投票权
节点状态:
- Looking,选举状态,集群中没有Leader节点
- Leading,领导状态,该节点为leader节点
- Following,leader节点的跟随者
- Observing,观察者,没有投票权
每个节点都有一个唯一的三元组(server_id,server_zxID,epoch)其中server_id表示本节点的唯一id,server_ZXID表示数据的版本,数字越大版本越新,epoch表示选举轮数。
具体流程
-> 翻阅Zookeeper笔记
3、分布式事务实现
事务,其实是包含一系列操作的、一个有边界的工作序列,有明确的开始和结束标志,且要 么被完全执行,要么完全失败,即 all or nothing。通常情况下,我们所说的事务指的都是 本地事务,也就是在单机上的事务。 而分布式事务,就是在分布式系统中运行的事务,由多个本地事务组合而成。在分布式场景 下,对事务的处理操作可能来自不同的机器,甚至是来自不同的操作系统。
1、XA协议
基于 XA 协议的二阶段提交协议方法和三阶段提交协议方法,采用了强一致性,遵从 ACID
两步提交
XA是一个分布式事务协议,XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。
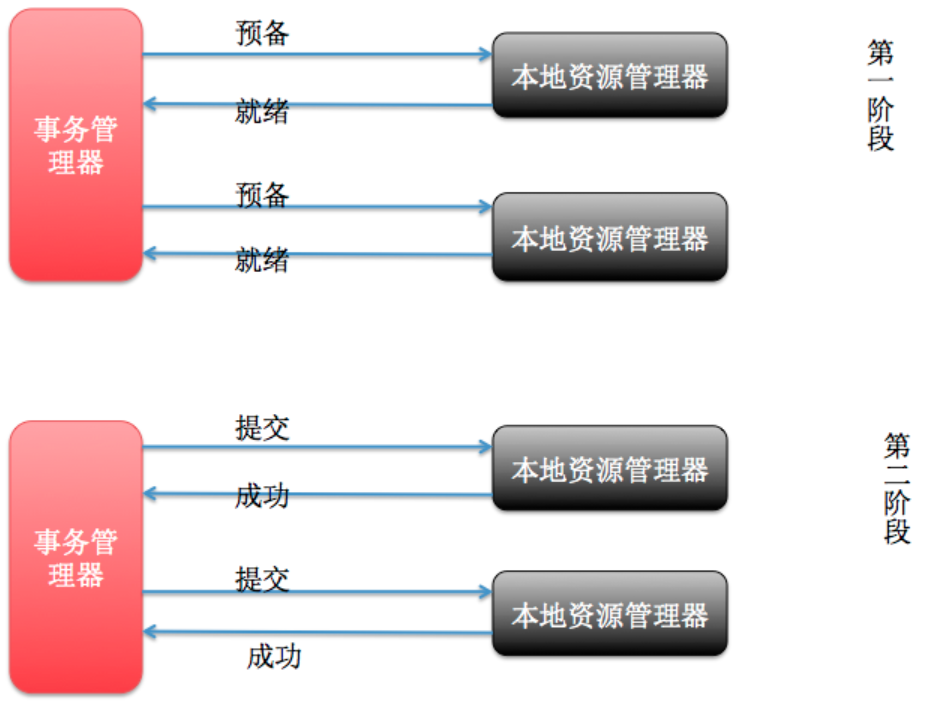
第一阶段,准备
- 事务管理器发送任务请求给各个本地资源管理器,询问是否可以发起事务
- 本地资源管理器执行操作,但是不提交。执行成功则发送成功标志给事务管理器
第二阶段,提交
- 所有参与者,都发送了成功标志
- 事务管理器发送提交指令
- 本地事务执行提交操作,数据持久化下来
- 解锁资源
- 有一个成员发送了未成功标志
- 发送回滚指令
- 事务执行回滚,Redolog
- 释放锁住资源
三阶段提交
为了解决两步提交中的三个痛点问题,引入了三阶段提交
- 同步阻塞问题,所有参与事务的线程都会被阻塞,等待提交或者回滚
- 单点问题,事务管理器如果宕机会导致事务一直被锁住
- 脑裂问题,提交阶段可能存在部分本地资源提交失败的可能
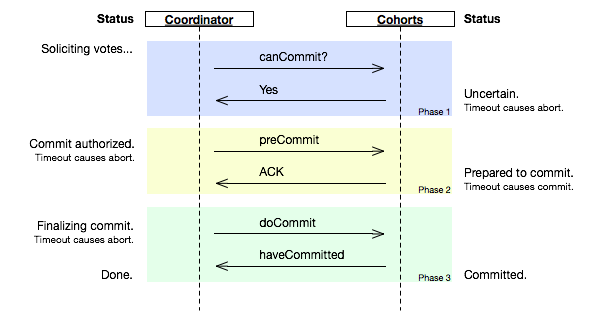
第一阶段:canCommit
- 事务管理器向所有成员询问是否可以执行事务,并同步等待
- 参与者发送响应
第二阶段,preCommit
- 预执行事务,将资源锁定,不提交
- 成员向管理器发送响应,是否执行成功
第三阶段,DoCommit
- 所有参与者,都发送了成功标志
- 事务管理器发送提交指令
- 本地事务执行提交操作,数据持久化下来
- 解锁资源
- 有一个成员发送了未成功标志
- 发送回滚指令
- 事务执行回滚,Redolog
- 释放锁住资源
- 参与者成功完成事务会向协调器发送ack
- 事务完成
优势:
- 降低同步阻塞,三阶段提交在第二阶段才锁定资源,锁的粒度更细
- 成员等待超时,如果参与者没有收到协调者的消息时,他不会一直阻塞,过一段时间之后,他会自动执行事务。
无法解决的问题:
协调器在挂掉之后发送了一条命令,恰好接受到的成员也宕机了,这个时候重新选举上来的协调器也不知道之前的状态是成功还是失败。
在提交阶段,如果协调器发送的回滚指令由于网络问题参与者没接收到时,参与者会在等待后去提交,这个时候数据就不一致了,目前最优解是Paxos算法。
总结
XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
2、最终一致性
消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败
基于消息的最终一致性方法,采用了最终一致性,遵从 BASE 理论。
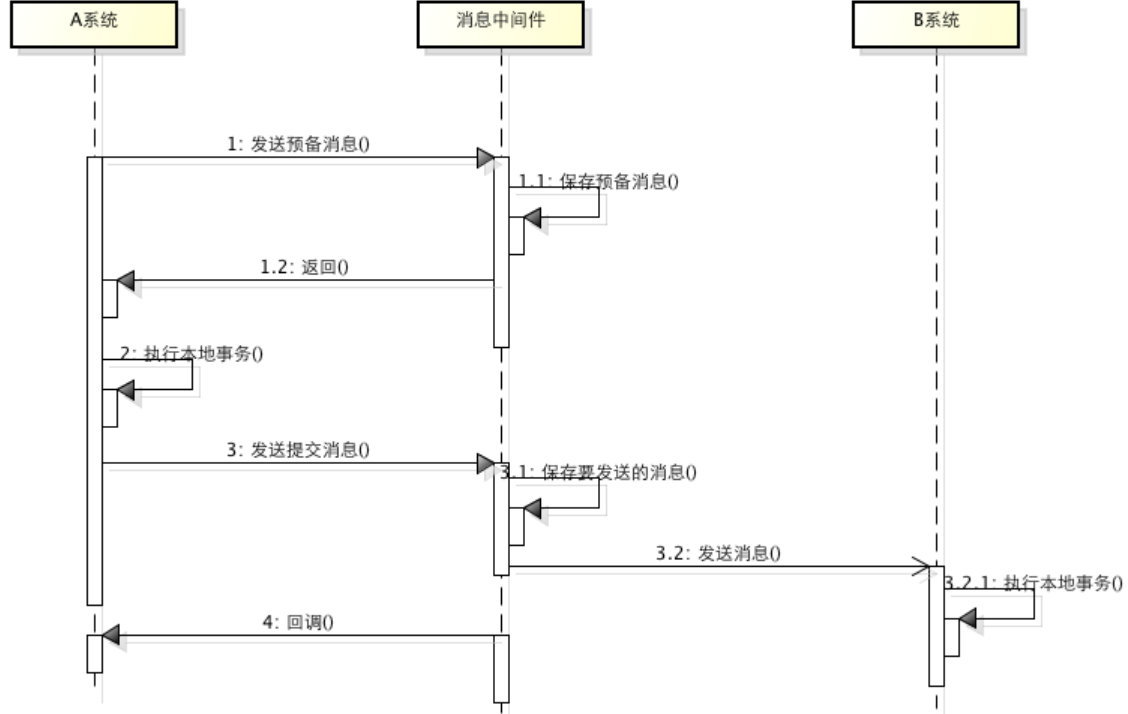
- A系统向消息中间件发送一条预备消息
- 消息中间件回复应答给A系统
- A系统执行事务操作,再向消息中间件发送消息
- 消息中间件收到消息,发送应答给A系统
步骤1,2失败时都可以本地进行回滚 ,步骤3失败时消息队列会一直回调A系统的一个回调接口,判断如果已经提交且消息中间件并未收到系统的消息,则将消息中间件预备消息拿出来回滚。
但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。
1、消息事务
事务消息适用的场景主要是那些需要异步更新数据,并且对数据实时性要求不太高的场景。且消息事务需要MQ的支持如RocketMQ和Kafka都支持消息事务,注意的是消费接口必须要实现幂等性。
如下图: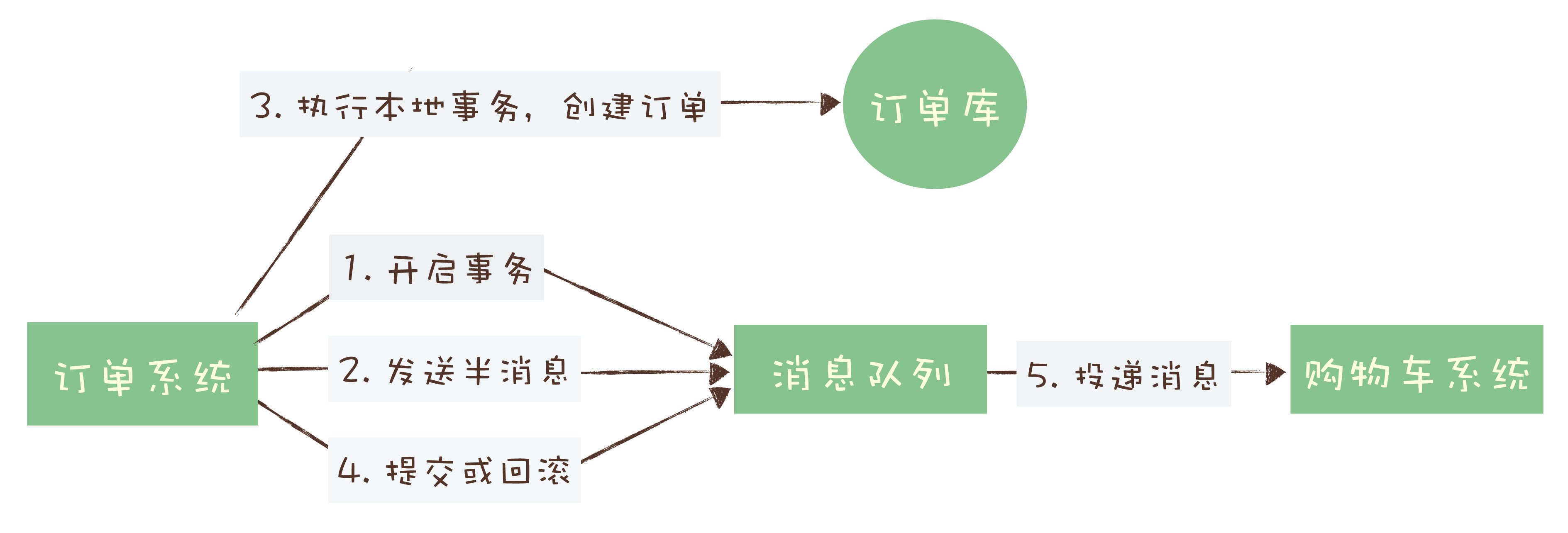
- 订单系统先开启事务并向消息队列发送一个半消息
- 订单系统在本地执行事务,将执行事务的结果(commit或rollback)发送给消息队列
- 消息队列根据订单系统执行情况来判断是否完成消息的创建
- 如果消息创建成功,那么购物车系统就能消费到订单系统投递的消息,如果购物车系统消费失败会周期进行消费(没用提交消费确认)
定时反查机制
如果在第四步的时候提交事务状态时失败了,那么消息队列将会陷入等待状态。RocketMQ会定时去Producer上去反查这个事务对应的状态。所以需要给事务消息指定一个事务反查回调接口。
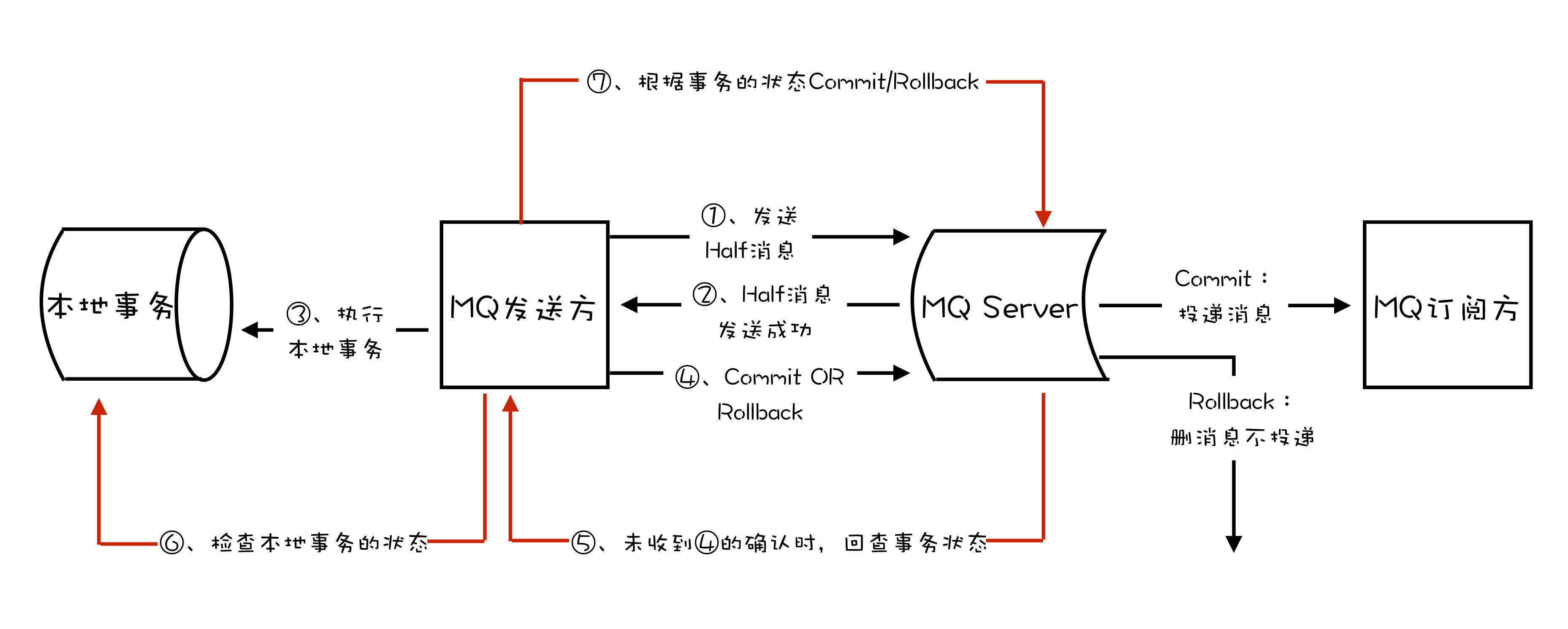
可靠消息最终一致性方案
①上游服务投递消息
如果要实现可靠消息最终一致性方案,一般你可以自己写一个可靠消息服务,实现一些业务逻辑。
首先,上游服务需要发送一条消息给可靠消息服务。这条消息说白了,你可以认为是对下游服务一个接口的调用,里面包含了对应的一些请求参数。
然后,可靠消息服务就得把这条消息存储到自己的数据库里去,状态为“待确认”。
接着,上游服务就可以执行自己本地的数据库操作,根据自己的执行结果,再次调用可靠消息服务的接口。
如果本地数据库操作执行成功了,那么就找可靠消息服务确认那条消息。如果本地数据库操作失败了,那么就找可靠消息服务删除那条消息。
此时如果是确认消息,那么可靠消息服务就把数据库里的消息状态更新为“已发送”,同时将消息发送给 MQ。
这里有一个很关键的点,就是更新数据库里的消息状态和投递消息到 MQ。这俩操作,你得放在一个方法里,而且得开启本地事务。
啥意思呢?如果数据库里更新消息的状态失败了,那么就抛异常退出了,就别投递到 MQ;如果投递 MQ 失败报错了,那么就要抛异常让本地数据库事务回滚。这俩操作必须得一起成功,或者一起失败。
如果上游服务是通知删除消息,那么可靠消息服务就得删除这条消息。
②下游服务接收消息
下游服务就一直等着从 MQ 消费消息好了,如果消费到了消息,那么就操作自己本地数据库。
如果操作成功了,就反过来通知可靠消息服务,说自己处理成功了,然后可靠消息服务就会把消息的状态设置为“已完成”。
③如何保证上游服务对消息的 100% 可靠投递?
上面的核心流程大家都看完:一个很大的问题就是,如果在上述投递消息的过程中各个环节出现了问题该怎么办?
我们如何保证消息 100% 的可靠投递,一定会从上游服务投递到下游服务?别着急,下面我们来逐一分析。
如果上游服务给可靠消息服务发送待确认消息的过程出错了,那没关系,上游服务可以感知到调用异常的,就不用执行下面的流程了,这是没问题的。
如果上游服务操作完本地数据库之后,通知可靠消息服务确认消息或者删除消息的时候,出现了问题。
比如:没通知成功,或者没执行成功,或者是可靠消息服务没成功的投递消息到 MQ。这一系列步骤出了问题怎么办?
其实也没关系,因为在这些情况下,那条消息在可靠消息服务的数据库里的状态会一直是“待确认”。
此时,我们在可靠消息服务里开发一个后台定时运行的线程,不停的检查各个消息的状态。
如果一直是“待确认”状态,就认为这个消息出了点什么问题。此时的话,就可以回调上游服务提供的一个接口,问问说,兄弟,这个消息对应的数据库操作,你执 行成功了没啊?
如果上游服务答复说,我执行成功了,那么可靠消息服务将消息状态修改为“已发送”,同时投递消息到 MQ。
如果上游服务答复说,没执行成功,那么可靠消息服务将数据库中的消息删除即可。
通过这套机制,就可以保证,可靠消息服务一定会尝试完成消息到 MQ 的投递。
④如何保证下游服务对消息的 100% 可靠接收?
那如果下游服务消费消息出了问题,没消费到?或者是下游服务对消息的处理失败了,怎么办?
其实也没关系,在可靠消息服务里开发一个后台线程,不断的检查消息状态。
如果消息状态一直是“已发送”,始终没有变成“已完成”,那么就说明下游服务始终没有处理成功。
此时可靠消息服务就可以再次尝试重新投递消息到 MQ,让下游服务来再次处理。
只要下游服务的接口逻辑实现幂等性,保证多次处理一个消息,不会插入重复数据即可。
⑤如何基于 RocketMQ 来实现可靠消息最终一致性方案?
在上面的通用方案设计里,完全依赖可靠消息服务的各种自检机制来确保:
如果上游服务的数据库操作没成功,下游服务是不会收到任何通知。
如果上游服务的数据库操作成功了,可靠消息服务死活都会确保将一个调用消息投递给下游服务,而且一定会确保下游服务务必成功处理这条消息。
通过这套机制,保证了基于 MQ 的异步调用/通知的服务间的分布式事务保障。其实阿里开源的 RocketMQ,就实现了可靠消息服务的所有功能,核心思想跟上面类似。
只不过 RocketMQ 为了保证高并发、高可用、高性能,做了较为复杂的架构实现,非常的优秀。有兴趣的同学,自己可以去查阅 RocketMQ 对分布式事务的支持。
2、TCC事务
TCC 将事务提交分为 Try - Confirm - Cancel 3个操作。
- Try:预留业务资源/数据效验
- Confirm:确认执行业务操作
- Cancel:取消执行业务操作
TCC事务处理流程和2PC二阶段提交类似,不过2PC通常都是在跨库的DB层面,而TCC本质就是一个应用层面的2PC,TCC协调器需要将事务数据持久化下来到硬盘上,因为TCC协调器也可能会发送当宕机以外。TCC事务比SAGA事务的安全性要高一些,但是响应的性能消耗也高一些。可以使用TCC框架:
tcc-transaction,支持dubbo,thrift,webservice,http协议
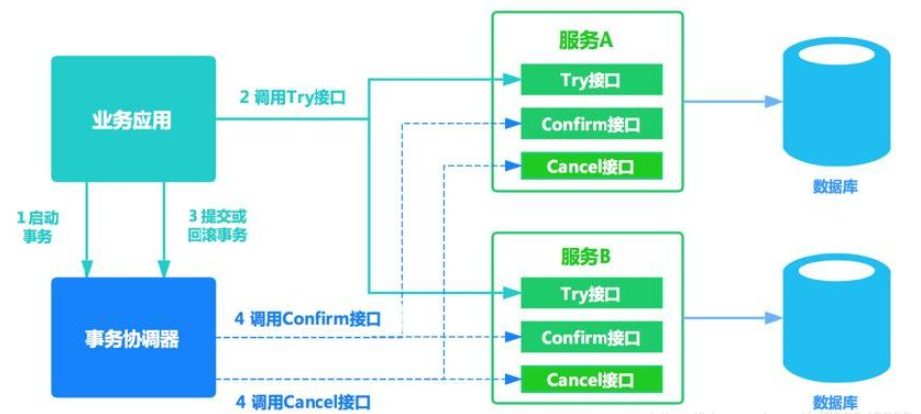
优势:实现异构系统之间的事务操作
缺点:
- 对于业务的侵入性强,业务逻辑需要分别实现:
Try,Confirm,Cancel实现 - 实现难度较大。需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。为了满足一致性的要求,
confirm和cancel接口必须实现幂等 Try阶段需要冻结信息,需要引入锁机制,开销较大适用于强一致性的场景
示例:
<!--try逻辑-->
<update id="increaseMoney">
UPDATE company SET frozen = frozen + #{money}
WHERE id = #{id}
</update>
<!--confirm逻辑-->
<update id="confirmIncreaseMoney">
UPDATE company SET money = money + #{money},frozen = frozen - #{money}
WHERE id = #{id}
</update>
<!--cancel逻辑-->
<update id="cancelIncreaseMoney">
UPDATE company SET frozen = frozen - #{money}
WHERE id = #{id}
</update>
3、SAGA模式
1987年普林斯顿大学的Hector Garcia-Molina和Kenneth Salem发表了一篇Paper Sagas,讲述的是如何处理long lived transaction(长活事务)。Saga是一个长活事务可被分解成可以交错运行的子事务集合。其中每个子事务都是一个保持数据库一致性的真实事务。
一般用于二次开发的项目,项目只提供了反交易接口。无法编写TCC接口
论文地址:sagas
相对于TCC模式来说,SAGA模式没有锁定数据这一步骤,也就是说SAGA在第一阶段就已经对真实数据进行了操作不需要再进行一次confirm操作。SAGA模式可以会产生读取到脏数据的问题,如果对于隔离性要求高则不可用。
以电商示例,API网关有四个服务:OrderService(订购) StockService(库存) PaymentService(支付) 和DeliveryService(货运)
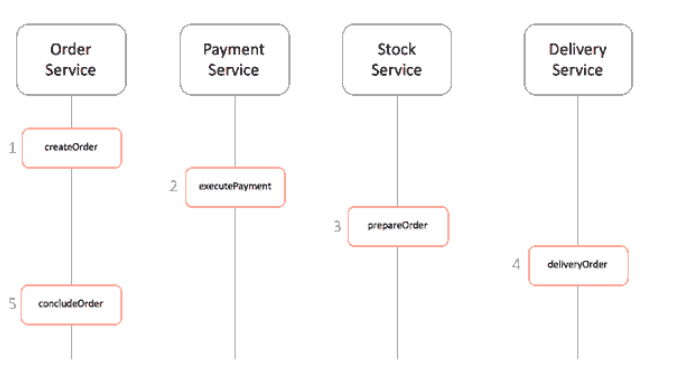
有两种不同的方式实现SAGA模式
事件驱动
第一个服务执行一个事务,然后发布一个事件。该事件被一个或多个服务进行监听,这些服务再执行本地事务并发布(或不发布)新的事件。当最后一个服务执行本地事务并且不发布任何事件时,意味着分布式事务结束,或者它发布的事件没有被任何Saga参与者听到都意味着事务结束。
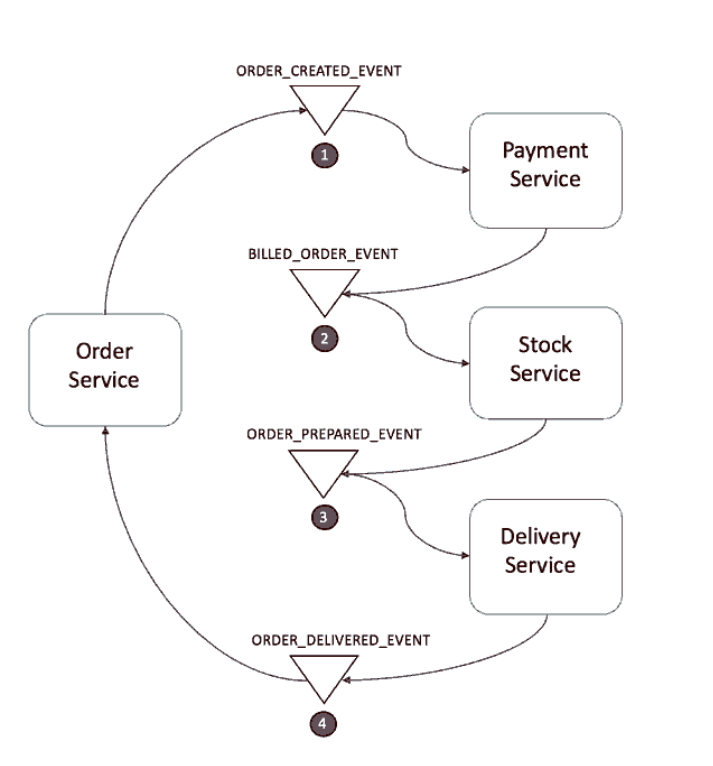
步骤
- 订单服务保存新订单,将状态设置为
pending,发布ORDER_CREATED_EVENT事件 - 支付服务监听事件
ORDER_CREATED_EVENT,完成支付后,发送事件BILLED_ORDER_EVENT - 库存服务监听
BILLED_ORDER_EVENT,更新库存,并发布ORDER_PREPARED_EVENT' - 货运服务监听
ORDER_PREPARED_EVENT,然后交付产品。最后,它发布ORDER_DELIVERED_EVENT - 订单服务侦听
ORDER_DELIVERED_EVENT并设置订单的状态改为完成
当其中一个环节执行失败时,上游服务会监听到执行失败的消息,并作补偿处理。如:在库存服务中出现库存量为0的情况,那么库存服务就会发送PRODUCT_OUT_OF_STOCK_EVENT ,这个时候支付服务和订单服务都会监听到,并执行自己的补偿业务。
优点:
设计简单,理解简单,所有参与者都是松耦合的
缺点:
当事项中步骤过多时,牵扯较多的微服务时事件监听会变得很复杂,不可控。
协调模式
这里我们定义了一项新服务,全权负责告诉每个参与者该做什么以及什么时候该做什么。saga协调器orchestrator以命令/回复的方式与每项服务进行通信,告诉他们应该执行哪些操作。
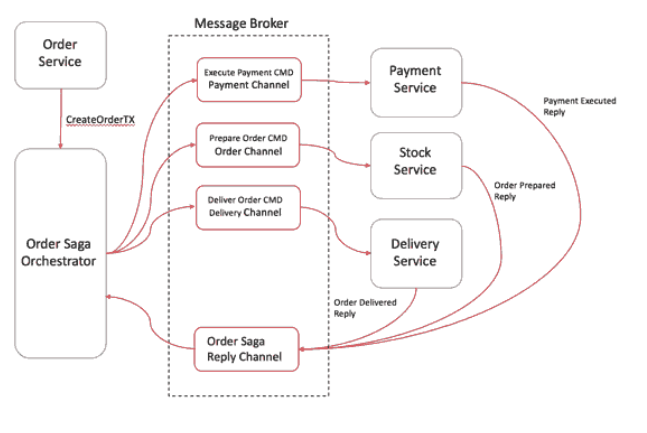
步骤
- 消息服务保存pedding状态,请求Saga协调器开启一个事务
- Saga协调器向支付微服务发送命令,支付微服务执行成功后返回成功响应
- 同理,Saga协调器向下面所有涉及到的微服务都发送命令,等待响应
- 如果全部执行成功,则Saga协调器会将订单状态改为完成
- 如果其中有服务失败,则会将所有执行成功的微服务进行补偿操作
优点:
- 避免服务之间的循环依赖关系
- 集中分布式事务的编排
- 降低复杂性
- 增加新步骤时也比较简单
缺点是引入了新的模块,要注意协调器的单点问题。
SAGA模式注意
- 某个事务都需要有一个唯一的事务ID,后续可以通过事务ID将这个流程中的数据串起来,方便追踪。
- 正反接口都需要做幂等处理,防止发送超时问题
- 尽量在命令中携带下游服务需要的信息,减少下游服务和上游之间的耦合关系
4、AT模式
Seata的AT事务是一种无侵入式的事务,基于XA事务改良后的产物。Seata 中有三大模块,分别是 TM、RM 和 TC。 其中 TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
TM(transcation manager):事务管理器
RM(resourcer manager):资源管理器
TC(Transaction Coordinator):事务协调器

4、分布式锁的实现
在单机多线程环境中,我们经常遇到多个线程访问同一个共享资源(这里需要注意的是:在 很多地方,这种资源会称为临界资源,但在今天这篇文章中,我们统一称之为共享资源)的 情况。为了维护数据的一致性,我们需要某种机制来保证只有满足某个条件的线程才能访问 资源,不满足条件的线程只能等待,在下一轮竞争中重新满足条件时才能访问资源。
分布式锁是指分布式环境下,系统部署在多个机器中,实现多进程分布 式互斥的一种锁。为了保证多个进程能看到锁,锁被存在公共存储(比如
Redis、Memcache、数据库等三方存储中),以实现多个进程并发访问同一个临界资源,同一时 刻只有一个进程可访问共享资源,确保数据的一致性。
1、数据库实现
要实现分布式锁,最简单的方式就是创建一张锁表,然后通过操作该表中的数据来实现。 基于数据库实现分布式锁,这里的数据库指的是关系型数据库; 当我们要锁住某个资源时,就在该表中增加一条记录,想要释放锁的时候就删除这条记录。 数据库对共享资源做了唯一性约束,如果有多个请求被同时提交到数据库的话,数据库会保 证只有一个操作可以成功,操作成功的那个线程就获得了访问共享资源的锁,可以进行操 作。
数据库的操作会导致IO操作的激增,过大的并发会使硬盘的IO承受不住,所以数据库实现的场景应该是并发低性能要求不高的场景。
场景
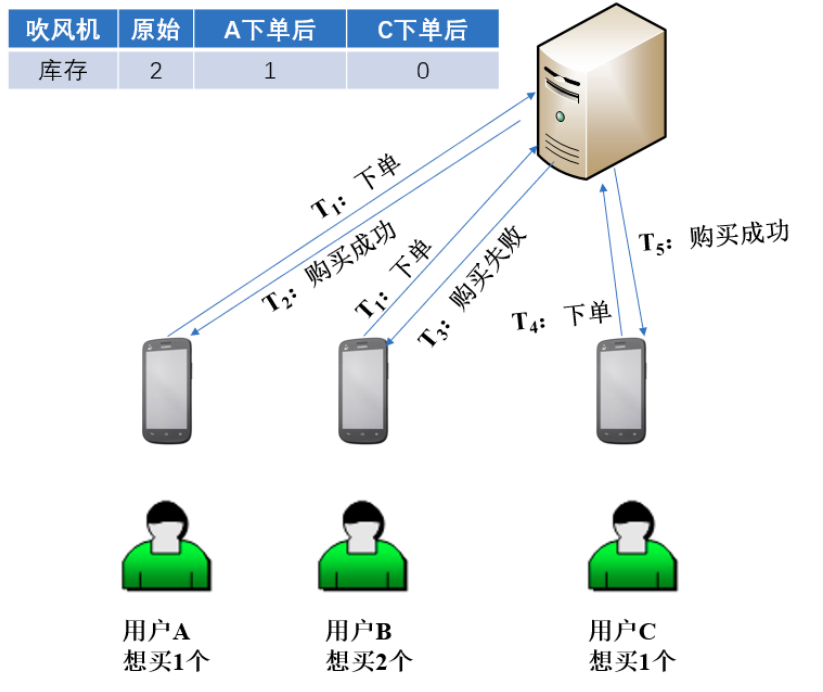
A和B同时下订单,A的下单请求最新到达数据库,所以用户A获得了锁,将库存减1.这个时候用户B也获得了锁,但是库存存量已经不够,所以返回了失败。
两个缺点
- 死锁问题,数据库中的锁表没有失效时间,未获得锁的进程只能一直等待,一旦获得锁的进程挂掉会导致线程被夯住。
- 单点故障问题,一旦数据库不可用,锁可能就失效
2、缓存实现
将锁数据放入到内存中,减少磁盘的IO操作,可以提高服务的吞吐量。通常缓存实现用Redis来实现,Redis通过lua脚本来实现加锁和解锁的原子化。
优点:
- 性能更好,内存IO比硬盘IO速度更快
- Redis支持集群,主从,哨兵部署,避免单点问题
Redis实现原理
加锁
当key不存在时才能成功,将key和value设置到redis中,并设置对应的过期时间。当返回失败时说明此时Redis中已经有同样的Key存在,说明其他线程并没放弃锁,需要等待锁的释放。
setnx(key,value,expireTime)
解锁
解锁主要需要两步,第一步是获取Key对应Redis中的Value,然后拿Value判断是否是此线程加入的锁,如果是则需要删除此Key,如果不是则不准删除,防止非持有锁的线程删除了加锁条件。
由于此操作分为两步,第一步是get,第二部是del。需要保证操作的原子性则需要采用lua脚本来实现:
if redis.call('get', KEYS[1]) == ARGV[1]
then
return redis.call('del', KEYS[1])
else
return 0 end
3、Zookeeper实现
ZooKeeper基于树形数据存储结构实现分布式锁,来解决多个进程同时访问同一临界资源 时,数据的一致性问题。ZooKeeper的树形数据存储结构主要由 4 种节点构成:
- 持久节点,节点的默认类型,一直保存在ZK中
- 持久顺序节点,节点会一直保存在ZK中且节点的会按照创建时间进行编号
- 临时节点,客户端和ZK断开后该进程创建的临时节点就会销毁。
- 临时顺序节点,生命周期和上面一样,但是节点会根据创建时间进行编号
具体实现
- 获取锁时去持久化点shared_lock目录下,为每个获取临界资源的进程创建一个临时顺序节点
- 每个进程都获得shared_lock目录下的所有临时节点列表,判断自身创建的临时节点是否是列表中最小的节点
- 如果是,获取到锁
- 如果不是,则说明有其他线程在前面排队。于是在他创建的临时节点前面的一个节点加上Watcher监听器
- 程序得到临界资源,运行完成。释放锁,删除自身创建的临时节点。触发监听器,触发后面等待进程的回调。
5、总结

ZooKeeper 分布式锁的可靠性最高,有封装好的框架,很容易实现分布式锁的 功能,并且几乎解决了数据库锁和缓存式锁的不足,因此是实现分布式锁的首选方法。
5、分布式缓存
待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号