ElasticSearch基本操作笔记
ElasticSearch图解 - 天宇轩-王 - 博客园 (cnblogs.com)
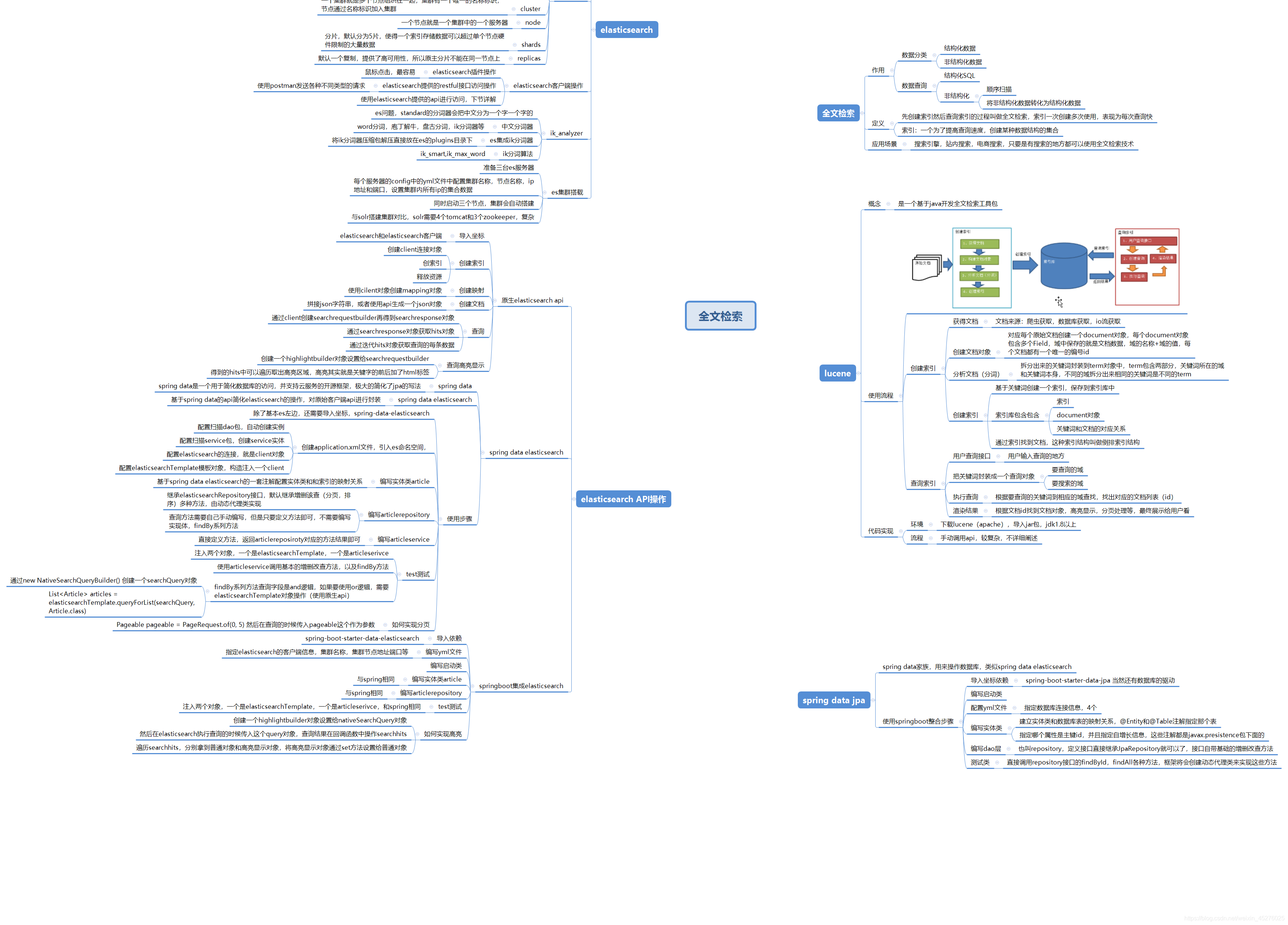
总览思维导图
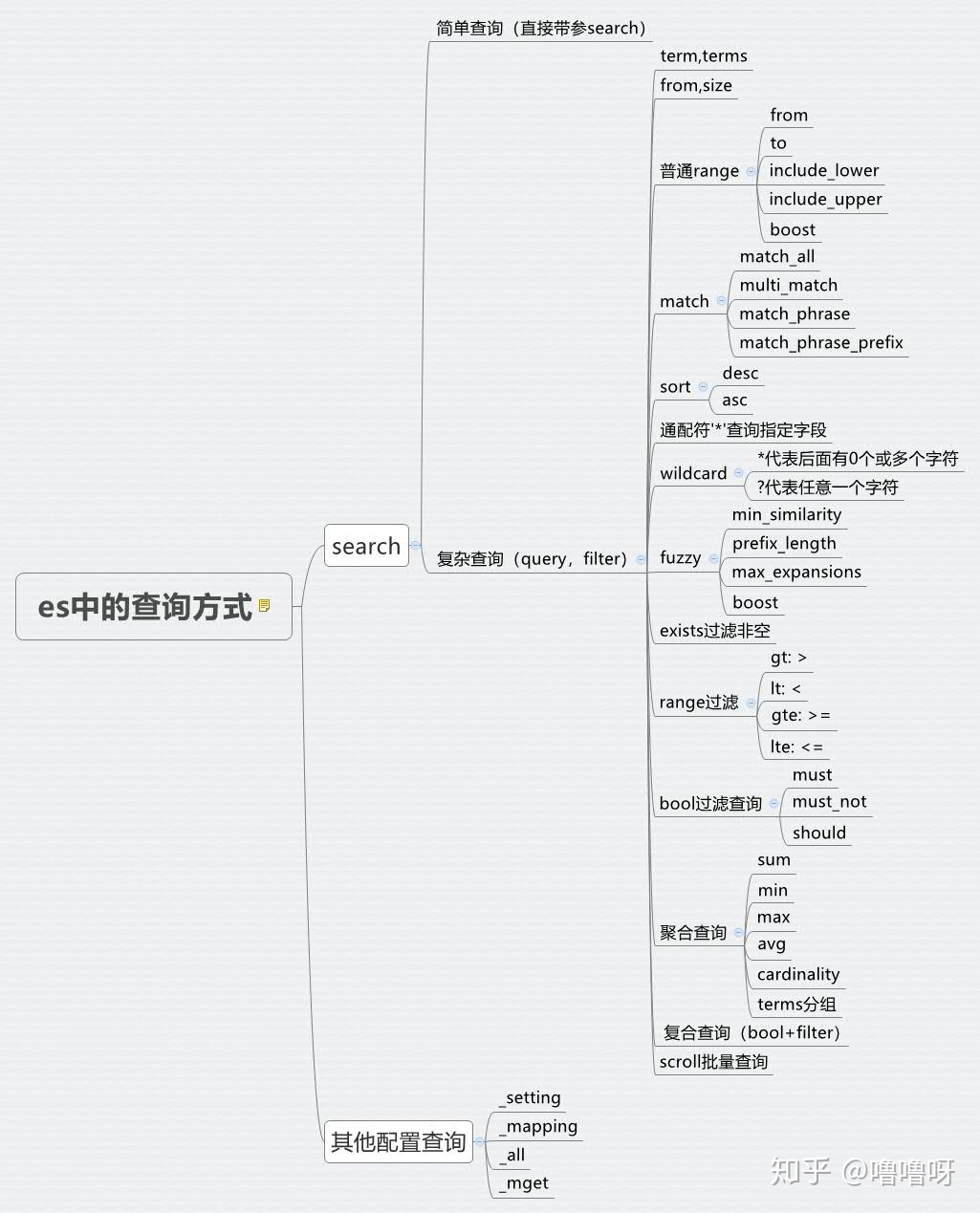
复杂查询相关思维导图
1、倒序索引和分词
1、倒排索引
2、分词器

- 分词(
Analysis)是将一系列的全文本转换成一系列单词的过程 - 除了在数据写入的时候转换词条,查询的时候也需要通过分词器(
Analyzer)进行语句分析
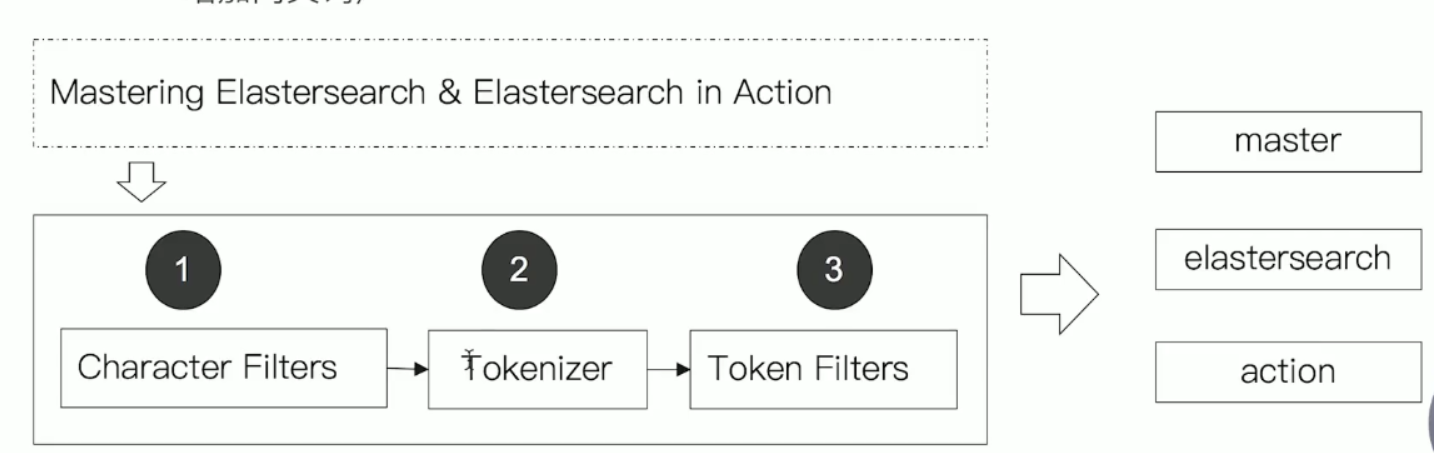
分词器由三部分组成:
Character Filter字符过滤:对原始文本进行处理,如去除HTML中的标签Tokenizer按照规则切分字符Token Filter,将切分的单词进行加工,小写化 等等。
1、_analyzer API
对数据进行分词分析
三种方式:
指定Analyzer测试
GET /_analyzer
{
"analyzer":"standard",
"text":"进行分词的内容"
}
对指定索引的字段进行分词
POST {}/_analyzer
{
"filed":"xxx"
}
自定义分词器测试
POST {}/_analyzer
{
"tokenizer":"xxx",
"filter":[""],
"text":""
}
2、内置分词器
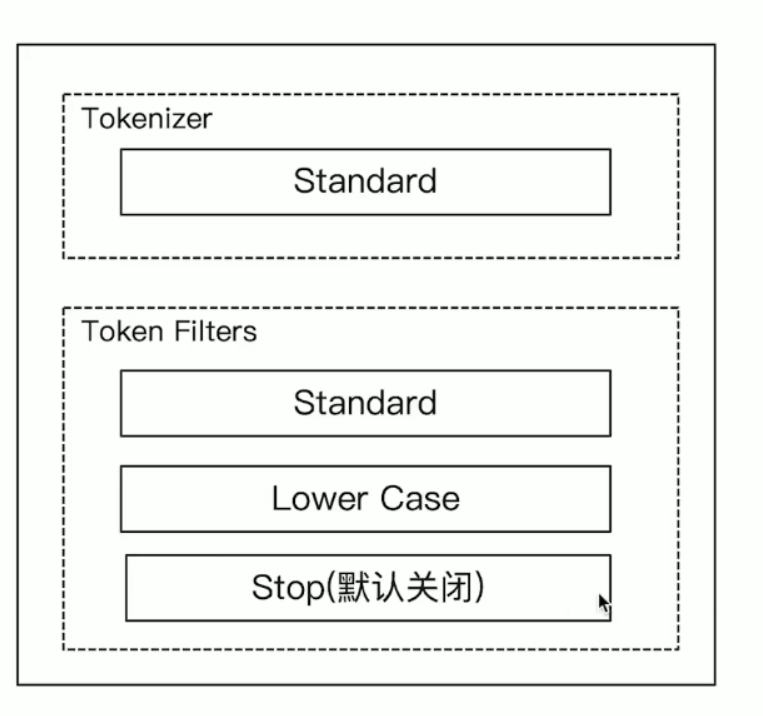
Standard Analyzer
- 默认分词器
- 按词切分
- 小写化
Simpe Analyzer
- 按照非字母切分,非字母都去除
- 小写处理
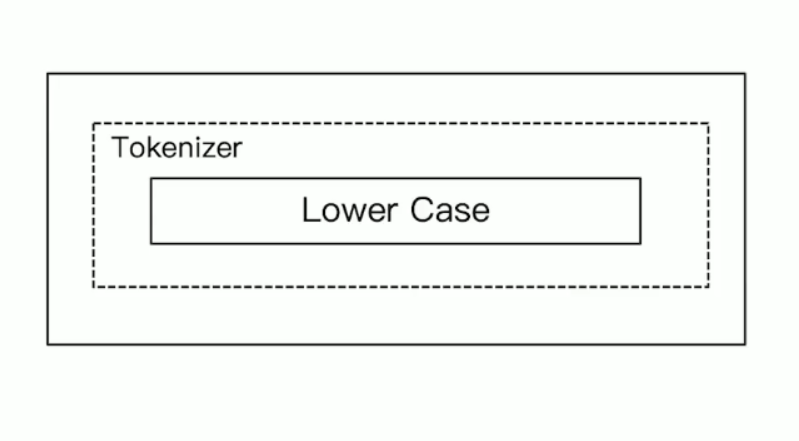
whitespace Analyzer
按照空格进行拆分
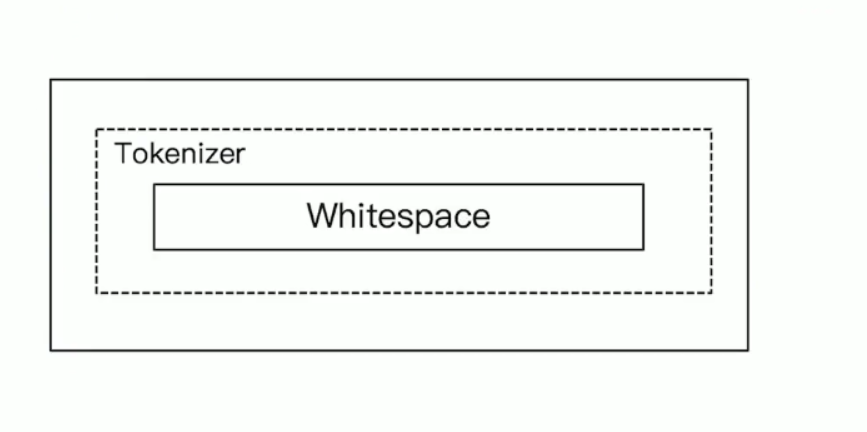
stop ananlyzer
- 会把the,a,is 去掉
- 小写化处理
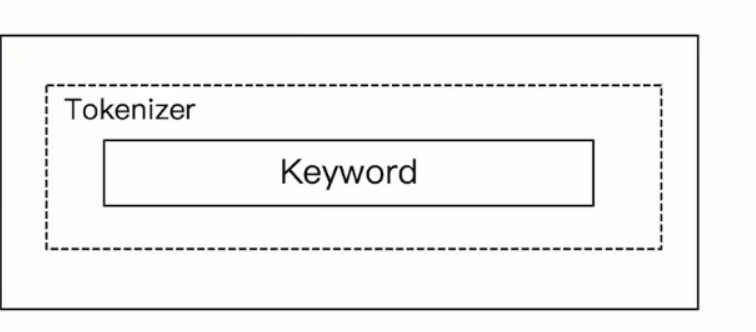
keyword anaylzer
不分词
pattern analyzer
- 正则表达式分词
- 默认为\w+,非字符分割
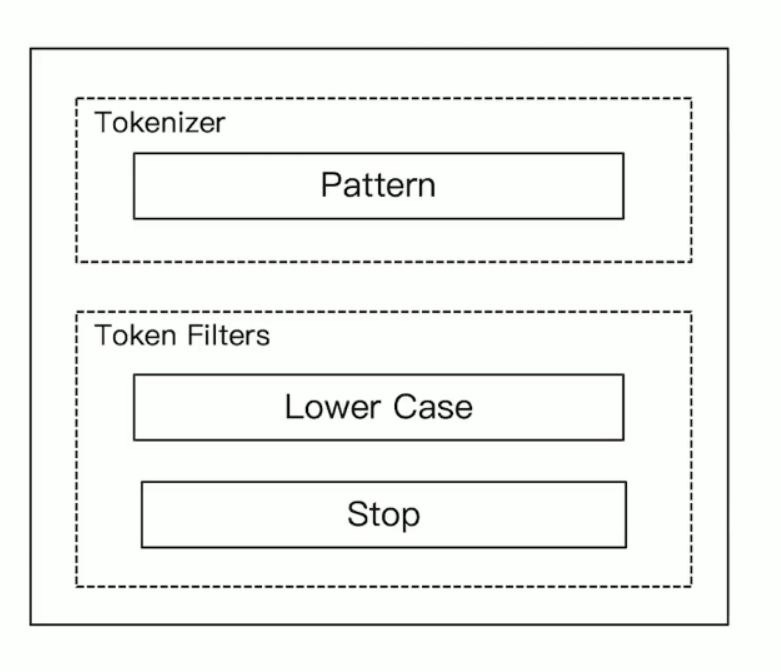
english analyzer
- 单词时态自动转换为标准
- stop一样的特征,过滤非英文字符
- 小写化
ICU analyzer
支持Unicode编码。
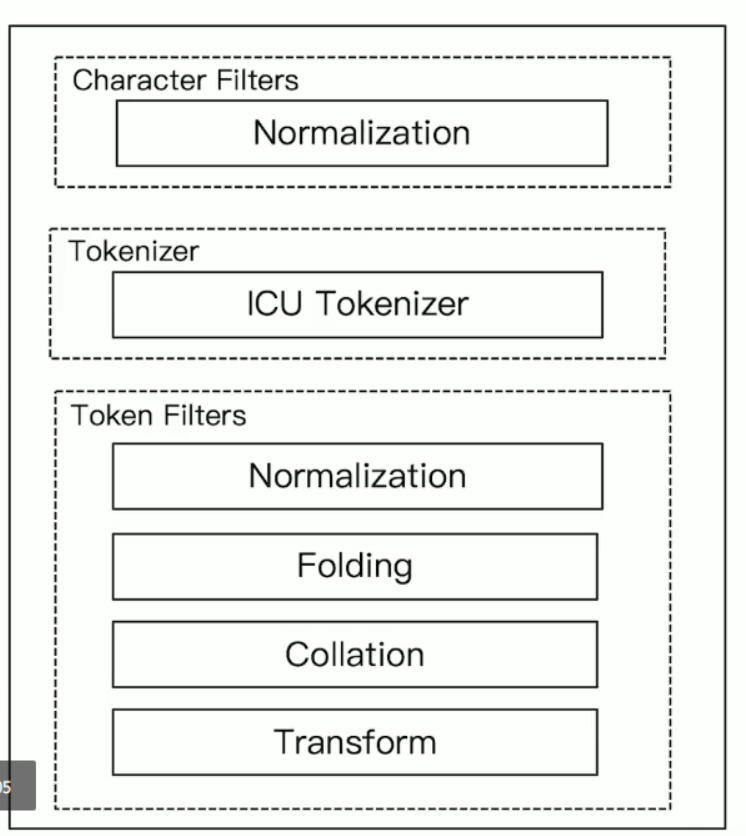
安装方式
Elasticsearch-plugin install analysis-icu ## 安装icu插件
Elasticsearch-plugin list ## 查看插件列表
2、索引创建
Elasticsearch可以隐式的创建索引,如在没索引的情况下直接创建一个文档,则ElasticSearch会根据一些默认的设置自动将文档的字段转换成索引,将文档中的字段转换成相应的类型,自动进行主从切分。 同时也支持显式的创建索引,通过命令的方式将索引创建完毕。
格式如下:
PUT /indexName
{
"settings": {
// 配置es的分片信息
},
“mappings”:{
// 配置索引字段处理信息
}
}
查询索引信息:
GET _cat/indices
1、Setting
Setting主要是对于索引的主分片和备份分片的一些配置。 分片就是对于Elasticsearch某个索引上传的数据会分发到不同的ES服务上进行存储。而副本则是每次上传的数据都会进行备份,相当于数据库的主从模式一样,不同的是ES自带副本功能。而Elasticsearch的主分片在第一次被设定好后就无法修改。
属性一览表
索引静态配置
- index.number_of_shards 索引分片的数量。在ES层面可以通过es.index.max_number_of_shards属性设置索引最大的分片数,默认为1024,index.number_of_shards的默认值为Math.min(es.index.max_number_of_shards,5),故通常默认值为5。
- index.shard.check_on_startup 分片在打开之前是否应该检查该分片是否损坏。当检测到损坏时,它将阻止分片被打开。可选值:false:不检测;checksum:只检查物理结构;true:检查物理和逻辑损坏,相对比较耗CPU;fix:类同与false,7.0版本后将废弃。默认值:false。
- index.codec 数据存储的压缩算法,默认值为LZ4,可选择值best_compression ,比LZ4可以获得更好的压缩比(即占据较小的磁盘空间,但存储性能比LZ4低)。
- index.routing_partition_size 路由分区数,如果设置了该参数,其路由算法为:\((hash(_routing) + hash(_id) % index.routing_parttion_size ) % number_of_shards\)。如果该值不设置,则路由算法为 \(hash(_routing) % number_of_shardings\),_routing默认值为_id。
索引动态配置
- index.number_of_replicas 索引复制分片的个数,默认值1,该值必须大于等于0,索引创建后该值可以变更。
- index.auto_expand_replicas 副本数是否自动扩展,可设置(e.g0-5)或(0-all)。
- index.refresh_interval 执行刷新操作的频率,该操作使对索引的最新更改对搜索可见。默认为1s。可以设置为-1以禁用刷新。
- index.max_result_window 控制分页搜索总记录数,from + size的大小不能超过该值,默认为10000。
- index.max_inner_result_window 从from+ size的最大值,用于控制top aggregations,默认为100。内部命中和顶部命中聚合占用堆内存,并且时间与 from + size成正比,这限制了内存。
- index.max_rescore_window 在rescore的搜索中,rescore请求的window_size的最大值。
- index.max_docvalue_fields_search 一次查询最多包含开启doc_values字段的个数,默认为100。
- index.max_script_fields 查询中允许的最大script_fields数量。默认为32。
- index.max_ngram_diff NGramTokenizer和NGramTokenFilter的min_gram和max_gram之间允许的最大差异。默认为1。
- index.max_shingle_diff 对于ShingleTokenFilter, max_shingle_size和min_shingle_size之间允许的最大差异。默认为3。
- index.blocks.read_only 索引数据、索引元数据是否只读,如果设置为true,则不能修改索引数据,也不能修改索引元数据。
- index.blocks.read_only_allow_delete 与index.blocks.read_only基本类似,唯一的区别是允许删除动作。
- index.blocks.read 设置为true以禁用对索引数据的读取操作。
- index.blocks.write 设置为true以禁用对索引数据的写操作。(针对索引数据,而不是索引元数据)
- index.blocks.metadata 设置为true,表示不允许对索引元数据进行读与写。
- index.max_refresh_listeners 索引的每个分片上当刷新索引时最大的可用监听器数量。这些侦听器用于实现refresh=wait_for。
- index.highlight.max_analyzed_offset 高亮显示请求分析的最大字符数。此设置仅适用于在没有偏移量或term vectors的文本字段时。默认情况下,该设置在6中未设置。x,默认值为-1。
- index.max_terms_count 可以在terms查询中使用的术语的最大数量。默认为65536。
- index.routing.allocation.enable Allocation机制,其主要解决的是如何将索引在ES集群中在哪些节点上分配分片(例如在Node1是创建的主分片,在其他节点上创建复制分片)。举个例子,如果集群中新增加了一个节点,集群的节点由原来的3个变成了4 可选值:
- all 所有类型的分片都可以重新分配,默认。
- primaries 只允许分配主分片。
- new_primaries 只允许分配新创建的主分片。
- none 所有的分片都不允许分配。
- index.routing.allocation.require.xxxx 将所有分配到配置了xxx属性的节点上去
- index.routing.rebalance.enable 索引的分片重新平衡机制。可选值如下:
- all 默认值,允许对所有分片进行再平衡。
- primaries 只允许对主分片进行再平衡。
- replicas 只允许对复制分片进行再平衡。
- none 不允许对任何分片进行再平衡
- index.gc_deletes 文档删除后(删除后版本号)还可以存活的周期,默认为60s。
- index.max_regex_length 用于正在表达式查询(regex query)正在表达式长度,默认为1000。
- index.default_pipeline 默认的管道聚合器。
分片设置
PUT indexName
{
"settings":{
"number_of_shards":5
}
}
副本设置
PUT indexName/
{
"settings":{
"number_of_replicas": 2
}
}
2、Mapping
Mapping类似于数据库中的schemal定义,作用如下:
- 定义索引中字段的名称
- 定义字段的数据类型
- 字段,倒排索引的相关配置。如Analyzer
Elasticsearch中的Mapping会将JSON文档转换成Lucenes所需要的格式
一个Mapping属于一个索引的Type
- 每个文档都属于一个Type
- 一个Type需要有一个Mapping来定义
- 7.0开始后不需要再Mapping中定义type
Mapping属性
"type" : "text", #是数据类型一般文本使用text(可分词进行模糊查询);keyword无法被分词(不需要执行分词器),用于精确查找
"analyzer" : "ik_max_word", #指定分词器,一般使用最大分词:ik_max_word
"normalizer" : "normalizer_name", #字段标准化规则;如把所有字符转为小写;具体如下举例
"boost" : 1.5, #字段权重;用于查询时评分,关键字段的权重就会高一些,默认都是1;另外查询时可临时指定权重
"coerce" : true, #清理脏数据:1,字符串会被强制转换为整数 2,浮点数被强制转换为整数;默认为true
"copy_to" : "field_name", #自定_all字段;指定某几个字段拼接成自定义;具体如下举例
"doc_values" : true, #加快排序、聚合操作,但需要额外存储空间;默认true,对于确定不需要排序和聚合的字段可false
"dynamic" : true, #新字段动态添加 true:无限制 false:数据可写入但该字段不保留 'strict':无法写入抛异常
"enabled" : true, #是否会被索引,但都会存储;可以针对一整个_doc
"fielddata" : false, #针对text字段加快排序和聚合(doc_values对text无效);此项官网建议不开启,非常消耗内存
"eager_global_ordinals": true, #是否开启全局预加载,加快查询;此参数只支持text和keyword,keyword默认可用,而text需要设置fielddata属性
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" ,#格式化 此参数代表可接受的时间格式 3种都接受
"ignore_above" : 100, #指定字段索引和存储的长度最大值,超过最大值的会被忽略
"ignore_malformed" : false ,#插入文档时是否忽略类型 默认是false 类型不一致无法插入
"index_options" : "docs" ,
# 4个可选参数
# docs(索引文档号),
# freqs(文档号 + 词频),
# positions(文档号 + 词频 + 位置,通常用来距离查询),
# offsets(文档号 + 词频 + 位置 + 偏移量,通常被使用在高亮字段)
# 分词字段默认是position,其他的默认是docs
"index" : true, #该字段是否会被索引和可查询 默认true
"fields": {"raw": {"type": "keyword"}} ,#可以对一个字段提供多种索引模式,使用text类型做全文检索,也可使用keyword类型做聚合和排序
"norms" : true, #用于标准化文档,以便查询时计算文档的相关性。建议不开启
"null_value" : "NULL", #可以让值为null的字段显式的可索引、可搜索
"position_increment_gap" : 0 ,#词组查询时可以跨词查询 既可变为分词查询 默认100
"properties" : {}, #嵌套属性,例如该字段是音乐,音乐还有歌词,类型,歌手等属性
"search_analyzer" : "ik_max_word" ,#查询分词器;一般情况和analyzer对应
"similarity" : "BM25",#用于指定文档评分模型,参数有三个:
# BM25 :ES和Lucene默认的评分模型
# classic :TF/IDF评分
# boolean:布尔模型评分
"store" : true, #默认情况false,其实并不是真没有存储,_source字段里会保存一份原始文档。
# 在某些情况下,store参数有意义,比如一个文档里面有title、date和超大的content字段,如果只想获取title和date
"term_vector" : "no" #默认不存储向量信息,
# 支持参数yes(term存储),
# with_positions(term + 位置),
# with_offsets(term + 偏移量),
# with_positions_offsets(term + 位置 + 偏移量)
# 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
什么是Dynamic Mapping?
- 再写入文档时候,如果索引不存在会自动创建索引
Dynamic Mapping会根据文档的信息自动推算出字段的类型- 一些特殊的类型不好去推算,如地理位置信息
查看Mapping信息
查看指定索引的Mapping定义。
GET indexName/_mapping
示例
GET chengji/_mapping
响应
{
"chengji" : {
"mappings" : {
"properties" : {
"Score" : {
"type" : "integer"
},
"course" : {
"type" : "keyword"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"name_keyword" : {
"type" : "keyword"
},
"sex" : {
"type" : "keyword"
}
}
}
}
}
关于Dynamic属性
- 新增字段
Dynamic设置为true时,一旦有新增字段的文档进入,则Mapping也会被更新Dynamic设置为false时,文档也能正常保存,但是新增字段无法被索引,Mapping未更新Dynamic设置为strict时,文档写入失败
- 对于已经有的字段,一旦有数据写入,就不再支持修改字段定义,如果希望改变字段类型必须重建索引
如何控制Dynamic属性?
命令示范:
PUT movie
{
"mappings":{
"_doc":{
"dynamic":true
}
}
}
查看mapping属性
GET indexName/_doc/_mapping?pretty
显式Mapping设置
命令示范:
PUT movie
{
"mappings":{
// define mapping
}
}
控制当前字段是否被索引
不创建倒排索引,节省内存空间

倒排索引级别

在index_options中有四个级别:
docs- 记录doc idfreqs- 记录doc id和term frequenciespostions- 记录doc id、term frequencies、term posionoffset- 记录doc id、term frequencies、term posion、offsets
默认Text类型倒排索引级别为positions,其他默认为docs,等级越高带来的内存开销越大
值可以为Null

通过null_value设置null值对应的字符串,这样在搜索的时候直接通过该值搜索就行了。只有keyword类型支持Null_value。
字段复制
在7.0级别中庸copy_to来替代已经被废除的_all属性。

copy_to将字段的数值拷贝到目标字段中,目标字段并不会出现在_source内容中
设置分词器
PUT blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer":"",
}
}
}
}
- analyzer是数据存放的时候解析的分词器
- search_analyzer用作查询的分词器
在索引时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的
在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的
多字段类型
采用multi-fields的方式可以将一个字段用多种分词器进行分词存储。
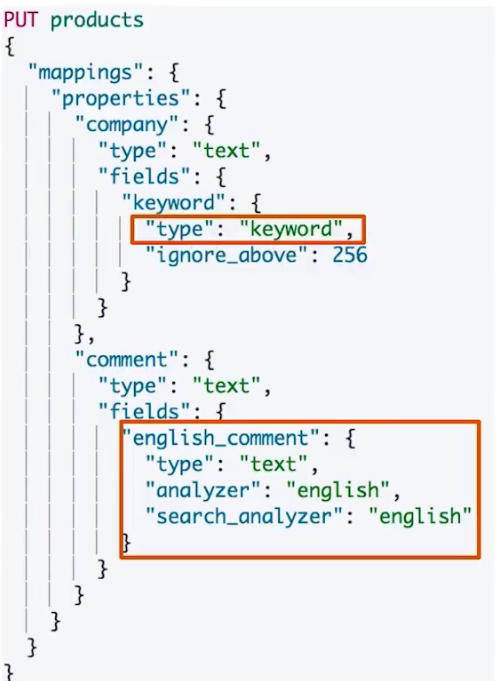

在一些字段中,Elasticsearch可以为其增加一个子字段。如上述例子。
- 对于
company字段需要进行精确查找可以对其定义一个子字段keyword,子字段类型为keyword - 对于评论字段需要通过英文分词器进行分词的,可以定义一个子字段
关于精确值和全文本的比较
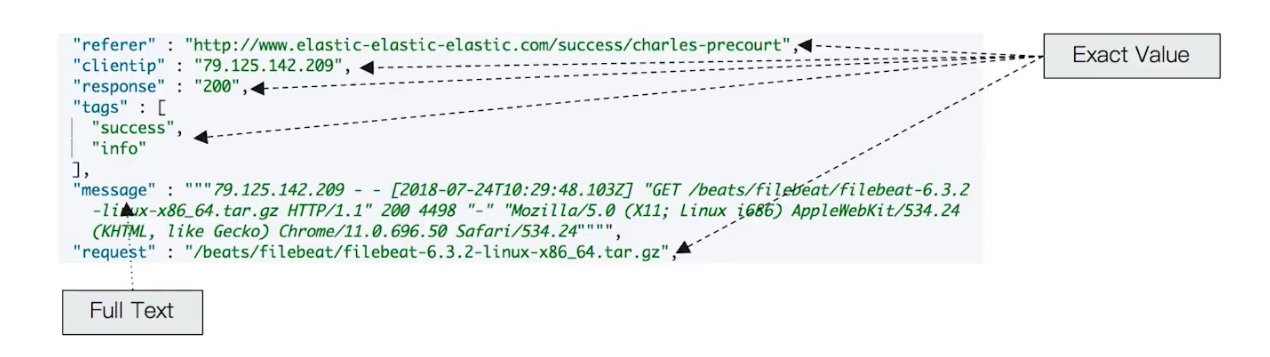
- 精确值,数字,日期,具体一个字符串,可以通过
keyword类型实现。精确值不需要做分词处理。 - 全文本,非结构化的文本数据 如
text类型
Index Template
目的是帮助你设置
Mappings和Settings,并按照一定规则自动匹配到新创建的索引上
- 模板仅在一个索引被创建时才会产生作用,修改模板不会影响已经创建的索引
- 可以设置多个索引模板,通过设置
order属性,让所有的索引模板能够按照顺序组成一个模板链,当使用时通过这个链条组装成一个模板结果。后面的会覆盖前面的设置。
示范:
PUT _template/templateName
{
index_patterns:["*"],
"order":0,
"settings":{
"number_of_shards":1,
"number_of_replicas":1
},
"mappings":{
“date_detection":true,
"numeric_detection":true
}
}
Dynamic Template
根据
ElasticSearch识别的数据类型,结合字段名称,来动态设定字段类型
示范
PUT indexName
{
”mappings:{
"dynamic_templates":[
"full_name":{
"path_match":"name.*",
"path_unmatch":"*.middle",
"mapping":{
"type":"text"
}
}
]
}
}
字段的类型
简单类型
Text/KeywordDateInteger/FloatingBooleanIPV4/IPV6
复杂类型
数组类型
[“one”,”two”]
对象数组
[{“name”:”mary”,”age”:20},{“name”:”john”,”age”:10}]
地理位置
geo_point ,用于经纬度坐标
_geo_shape,_多边形的复杂形状。类似于Redis中的GeoHash
Completion
提供自动补全建议
3、文档CURD
1、新增文档
- Type内容约定都是用_doc
- Create时,若id已经存在会失败
2、使用PUT方式的新增
PUT {indexName}/_create/{docId}
{
// 文档内容
}
使用POST方式的新增
POST {indexName}/_doc/(不用指定id,自动生成)
{
// 文档内容
}
示例
请求
POST testindex/_doc/
{
"name":"孙爱飞",
"age":24,
"gender":true
}
响应
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
3、获取文档
GET {IndexName}/_doc/{docId}
示例
GET testindex/_doc/siaYR3oBcZhrPC7UZXpM
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "孙爱飞",
"age" : 24,
"gender" : true
}
}
- _index,索引名称
- _type,类型默认为_doc
- _id,主键,唯一标识
- _version,版本号,1表示改动了1次
- _source, 原始的数据
4、新增/更新文档
Index和create的区别在于:如果id对应的文档不存在则会创建新的文档,否则将现有的文档删除,新的文档被索引且version+1
请求格式
PUT {indexName}/_doc/{docId}
{
// 文档内容
}
示例
请求
PUT testindex/_doc/siaYR3oBcZhrPC7UZXpM
{
"tags":
[
"帅气","聪明","勤奋"
]
}
响应
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
可以看出result的类型变成了updated说明此文档被更新了,现在通过GET去查看一下文档变成什么样子。
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"tags" : [
"帅气",
"聪明",
"勤奋"
]
}
}
5、更新文档
不会删除原文档,实现真正的数据更新
请求格式
POST {indexName}/_update/{docId}
{
"doc":{
// 报文
}
}
示范
请求
POST testindex/_update/siaYR3oBcZhrPC7UZXpM
{
"doc": {
"family": [
"dad",
"mom"
]
}
}
响应
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
查看原始数据现在已经变成了:
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"tags" : [
"帅气",
"聪明",
"勤奋"
],
"family" : [
"dad",
"mom"
]
}
}
6、Bulk操作
用来批量进行API操作,和
Redis中的管道差不多。单个失败的操作不会影响其他成功的操作
请求格式
POST _bulk
{"index":{"_index":"","_id":""}}
{"filed1":"xxx"}
{"delete":{"_index":"","_id":""}}
{"create":{"_index":"","_id":""}}
{"filed1":"xxx"}
{"update":{"_index":"","_id":""}}
{"doc":{}}
7、批量查询
请求格式
GET _mget
{
"docs":
[
"_index":"",
"_id":1
]
}
示例
请求
GET _mget
{
"docs": [
{
"_index": "testindex",
"_id": "tCbQR3oBcZhrPC7U9Hq9"
},
{
"_index": "testindex",
"_id": "siaYR3oBcZhrPC7UZXpM"
}
]
}
响应
{
"docs" : [
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "tCbQR3oBcZhrPC7U9Hq9",
"_version" : 1,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "哈吉斯",
"age" : 22,
"gender" : false
}
},
{
"_index" : "testindex",
"_type" : "_doc",
"_id" : "siaYR3oBcZhrPC7UZXpM",
"_version" : 4,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"tags" : [
"帅气",
"聪明",
"勤奋"
],
"family" : [
"dad",
"mm"
]
}
}
]
}
4、复杂搜索
| 语法 | 范围 |
|---|---|
| /_search | 集群上的所有索引 |
| /index1/_search | 搜索索引index1 |
| /index1,index2-2/_search | 搜索索引index1和index2 |
| /index*/_search | 搜索以index开头的索引 |
1、Url Search
格式:
GET /indexName/_search?xxx=yyy
q指定查询语句,示范:?q=k:v- 术语查询(
Term query)和短语查询(Phrase query):- Beautiful Mind ,等效于Beautiful OR Mind。规范来说要加上括号
- “Beautiful Mind”,等效于Beautiful And Mind ,顺序一致
- 布尔操作:
AND,OR,NOT,&&,||,!- 必须大写
- title:(matrix NOT reoladed)
- 分组:
+:必须 ,-:必须不 - 范围查询:
[]:闭区间{}:开区间- year:
- 算数符号
- year:>2019
- year:(>2019 AND <= 2021)
- 模糊查询:
?代表一个字符,*代表多个字符- title:mi?d
- title:my*
- 正则表达式:title:[pattern]
- 近似查询:~近似度
- title:beautifu~1
- 术语查询(
df指定查询的字段,不指定时查询全部字段sort排序/from和size分页profile执行计划
示范:
GET /movie/_search?q=2012&df=movie_name&sort=year:desc&from=0&size=10&timeout=2s
{
"profile":true
}
返回报文格式:
{
"took": 3,// 话花费时间
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {// 命中内容
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5753642,// 相关性
"hits": [
{
"_index": "testindex",
"_type": "_doc",
"_id": "siaYR3oBcZhrPC7UZXpM",
"_score": 0.5753642,
"_source": {
"tags": [
"帅气",
"聪明",
"勤奋"
],
"family": [
"dad",
"mm"
]
}
}
]
}
}
2、Query String
格式:
POST indexName/_search
{
"query":{
"filed":[], -- 指定查询的字段
"query":""
}
}
1、查询功能
排序
采用
sort字段来进行排序,如:"sort":[{"字段":"排序"}]
{
"sort":[{"date":"desc"}],
"query":
{
"match":""
}
}
分页
分页使用
form和size进行控制
{
"from":0,
"size":10,
"query":
{
"match_all":""
}
}
还可以通过滚动查询的方式
在搜索大量数据时,可以用
scroll技术滚动搜索。如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完为止。
开启滚动查询:
GET /lib6/user/_search?scroll=1m
{
"query":{
"match_all":{}
},
"size":1000,
"sort":["_doc"]
}
指定查询用户信息,每次查询1000个。使用_doc属性排序也就是说只要有文档就可以查询,仅仅从有文档的节点中进行查询。而指定的scroll属性值为1m表示此次创建的游标查询过期时间为1分钟,滚动查询每次都会刷新此过期时间。
返回结果包含一个_scroll_id,后面的滚动查询都需要带上此_scroll_id.获取下一批数据
GET /_search/scroll
{
"scroll":"1m",
"scroll_id":"sssss"
}
尽管指定size为1000,但是有可能取值超过这个数值,当查询时,字段size作用于单个分片。所以实际上最大查询数为size*number_of_primary_shards.
存在查询
可以与filter一起,过滤非空查询。
如果把外面那一层constant_score去掉,会报异常。这也从侧面说明了,可以把filter理解为不计算查询相关度的query。
GET /lib6/user/_search
{
"query":{
"constant_score":{
"filter":{
"exists":{"field":"address"}
}
}
}
}
返回所有address字段存在的用户。
控制返回的字段
相当于SQL中的Select coulmnName,对于一些_source数据量大的文本这样会优化搜索速度。
{
"_source": {
"includes": "addr*",
"excludes": [
"name",
"bir*"
]
},
"query": {
"match": ""
}
}
脚本字段
相当于SQL中的内置函数,对于数据行进行count,sum,avg,concat等运算
{
"script_fileds": {
"新字段名": {
"script": {
"lang": "painless",
"source": "doc['字段名'].value + '需要拼接的值' "
}
}
},
"query": {
"match": ""
}
}
分组查询
{
"query":{
"filed":[],
"query":"(词组1 AND 词组2) OR (词组3 AND 词组4)"
}
}
范围查询
范围查询使用range关键字
参数:from,to,include_lower,include_upper,boost
include_lower:是否包含范围的左边界,默认是true
include_upper:是否包含范围的右边界,默认是true
{
"query": {
"range": {
"birthday": {
"from": "1990-10-10",
"to": "2000-05-01",
"include_lower": true,
"include_upper": false
}
}
}
此外还有以下参数用来限制范围
get,大于等于gt,大于lte,小于等于lt,小于
模糊查询
wildcard查询
允许使用通配符
*和?来进行查询
*代表0个或多个字符
?代表任意一个字符
{
"query": {
"wildcard": {
"name": "wang*"
}
}
}
fuzzy 查询
fuzzy 查询是 term 查询的模糊等价
- 查询内容不分词
- 判断逻辑是文本某个分词的结果是否包含查询值
参数:
value:查询的关键字boost:查询的权值,默认值是1.0min_similarity:设置匹配的最小相似度,默认值为0.5,对于字符串,取值为0-1(包括0和1);对于数值,取值可能大于1;对于日期型取值为1d,1m等,1d就代表1天prefix_length:指明区分词项的共同前缀长度,默认是0max_expansions:查询中的词项可以扩展的数目,默认可以无限大
{
"query": {
"fuzzy": {
"interests": "chagge"
}
}
}
几种模糊查询的比对
模糊查询有match,wildcard和fuzzy三种方式。其中:
match的方式就是通过全文索引的方式去查找和指定关键字相关度高的信息,其实也是一种模糊查询。
wildcard相当于SQL中的like关键字,通过通配符的方式去查找。
fuzzy具有一定的纠错能力,通过配置能让搜索有容错性
2、Simple Query String
- 类似于
Query String,但是忽略错误语法,只支持部分查询语法 - 不支持
AND OR NOT,可以使用- +替代AND
- |替代OR
- -替代NOT
- Term之间的默认关系为
OR,可以指定operator
格式:
POST indexName/_search
{
"simple_query_string":{
"filed":[], -- 指定查询的字段
"query":""-- 查询语句
”default_operator":"AND"
}
}
3、Bool查询
一个
Bool查询是一个或多个查询子句的组合
must,必须匹配,贡献算分should,选择性匹配,贡献算分must_not,必须不匹配,不算分filter,必须匹配,算分在Bol查询中,匹配的句子越多相关性评分也就越高。
示范:
{
"query":{
"bool":{
"must":{
"term":{"price":"30"}
},
"filter":{
"term":{"avaliable":"true"}
},
"must_not":{
"range":{
"price":{"lte":10}
}
},
"should":[
{"term":{}},
{"term":{}}
]
}
}
}
可嵌套查询
{
"query": {
"bool": {
"must": {
"term": {
"price": "30"
}
},
"should": [
{
"bool": {
"must_not": {
"term": {
"avaliable": "false"
}
}
}
}
]
}
}
}
同一层级的竞争字段有相同的权重,可以通过bool的嵌套实现对算分产生影响。
调整算分
通过
boost字段可以控制查询的相关度
boost> 1,提高相关度- 0<
boost<1,相对降低boost<1,负分 通常在
Bool多字段查询中使用。如下面这段查询,如果should中的两个查询都查到了数值,那么搜到Elasticsearch这项的分要高于Lucene
示范如下:
{
"query": {
"bool": {
"must": {
"match": {
"content": {
"query": "full text search",
"operator": "and"
}
}
},
"should": [
{
"match": {
"content": {
"query": "Elasticsearch",
"boost": 3
}
}
},
{
"match": {
"content": {
"query": "Lucene",
"boost": 2
}
}
}
]
}
}
}
boosting
可以对查询的内容进行控分,举个例子:查询的内容中如果有
ElasticSearch则加分,如果查询到的内容里面有Lucene则会进行响应的扣分。 这样全文本查询下,如果文本中只有一个
ElasticSearch那么他的评分最高。
如下:
{
"query": {
"boosting": {
"positive": {
"term": {
"state.keyword": {
"value": "DC"
}
}
},
"negative": {
"term": {
"age": {
"value": 23
}
}
},
"negative_boost": 0.2 // 负面评分多少
}
}
}
4、单字符串多字段查询
现在有这样一项需求,需要在文章的标题和内容里面都搜索apple pad这个词,我们可以怎么做呢?
首先可以用Bool的should查询实现:
{
"query":{
"should": [
{
"match": {
"title": {
"query": "apple"
}
}
},
{
"match": {
"content": {
"query": "apple"
}
}
}
]
}
}
}
单纯用should会导致一个问题:当某个文档的内容中有apple pad的时候算分不一定是很高的,这是因为should的算分机制:
- 查询
should中的每个查询 - 加和查询的评分
- 乘以匹配语句总数
- 除以所有语句总数
所以当某个文档中的标题和内容都有apple时反而比有apple pad为内容的文档分来的要高。
以下两种方式可以解决这个痛点:
multi_match
同时对查询的关键词,多个字段同时进行匹配,即多个字段是OR的关系
{
"query":{
"multi_match":{
"query":"2501",
"fileds":["f1","f2"]
}
}
}
同时还能指定不同filed的分值不一样,例如:在fields中,按brandName(品牌名)、sortName(分类名)、productName(商品名)productKeyword(商品关键字),搜索“牛仔 弹力”关键词,brandName源值、拼音值、关键字值都是100分,sortName源值、拼音值80分,productName源值60分,productKeyword值20分,分值由高到低优先级搜索
"query":{
"multi_match":{
"query":"弹力牛仔裤",
"fileds":[
"brandName^100",
"sortName^80",
"productName^60"
]
}
}
Disjunction Max Query
dis_max采用任一匹配的文档作为返回结果。采用字段上最匹配的评分返回
示例:
{
"query":{
"dis_max":{
"queries":[
{// query 1},
{// query 2}
]
}
}
}
由于dis_max的机制,他只返回最匹配评分的机制,如果某个查询中标题和内容都查询到了数据那么他的评分也不一定很高,因为只返回的是最优评分,这个时候就要引入quick pets
tie_breaker 参数提供了一种 dis_max 和 bool 之间的折中选择,它的评分方式如下:
- 获得最佳匹配语句的评分
_score。 - 将其他匹配语句的评分结果与
tie_breaker相乘。 - 对以上评分求和并规范化。
5、词项和全文本查询
基于term查询
结构化字段查询,匹配一个值,且输入的值不会被分词器分词
示范:
{
"query":{
"term":{
"foo": "hello world"
}
}
那么只有在字段中存储了"hello world"的数据才会被返回,如果在存储时,使用了分词,原有的文本”I say hello world"会被分词进行存储,不会存在"hello world"这整个词,那么不会返回任何值。如果需要通过term查询到完整是数据,则可以在mappings设置中为字段设置keyword,由于keyword是不进行分词保存的。所以通过keyword的term查询是能查询到内容的。
跳过算分步骤
由于term查询是不进行分词操作,那么其实算分步骤也是可以去除的。
通过Constant Score转换为Filter就可以做到:
{
"query":{
"constant_score":{
"filter":{
"term":{
"key":"value"
}
}
}
}
}
filter查询是不计算相关度的,所以再query查询中需要指定一个constant_score来得分,而再filter查询中则不用,如下:
GET /lib6/user/_search
{
"post_filter":{
"terms":{
"age":[25,40]
}
}
}
查询25<=age<=40的所有用户。
基于全文本查询
基于全文本查询的有:
- Match query
- Match parse query
- Query String
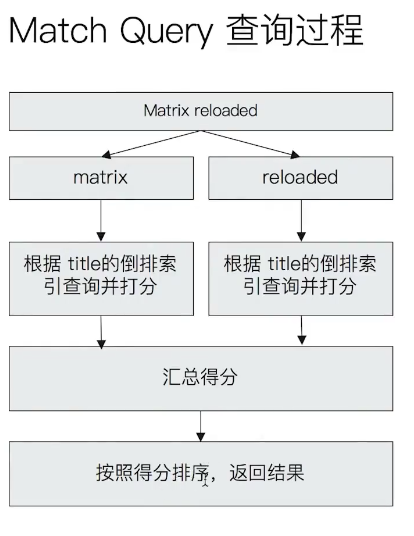
全文本查询的特点:
- 索引和搜索时都会进行分词
- 查询字符串先经过合适的分词器进行分词,生成一个待查询的数组
- 会对带查询数组遍历然后进行底层的查询,最 后将结果汇总然后打分
match_phase查询
在对查询字段定义了分词器的情况下,会使用分词器对输入进行分词,然后返回满足下述两个条件的
document:1.
match_phase中的所有term都出现在待查询字段之中2.待查询字段之中的所有
term都必须和match_phase具有相同的顺序
multi_match查询
使用multi_match可以指定多个字段查询。
GET lib6/user/_search
{
"query":{
"multi_match":{
"query":"swimming",
"fields":["name","favor"]
}
}
}
match查询
模糊匹配,先对输入进行分词,对分词后的结果进行查询,文档只要包含
match查询条件的一部分就会被返回(OR)
上面的查询条件类似于:Last OR Christmas,相当于上面说到的Term Query,如果想要将查询的条件改为Last AND Christmas,参考下面JSON串
{
"query":{
"match":{
"comment":"Last Christmas",
"operator":"AND"
}
}
}
既然说到了术语搜索(Term Query),那么就要提一下短语搜索(Phrase Query)如何实现:
{
"query":{
"match":{
"comment":"Last Christmas",
"slop":1
}
}
}
3、聚合查询
对于数据的整体的分析
Bucket Aggregation
一些列满足特地条件的文档集合,相当于数据库中的
group关键字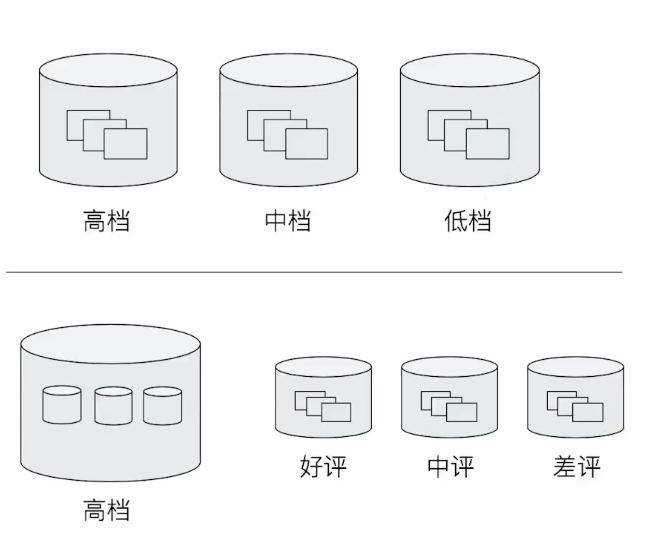
- 杭州属于浙江、演员属于男性和女性
- 嵌套关系:杭州属于浙江,浙江属于中国
Bucket类型有:
TermRange
term例子
根据course参数进行了分组,最后得出count的值
GET chengji/_search
{
"size": 0,
"aggs": {
"cjpb": {
"terms": {
"field": "course"
}
}
}
}
响应
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 21,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"cjpb" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "数学",
"doc_count" : 7
},
{
"key" : "英语",
"doc_count" : 7
},
{
"key" : "语文",
"doc_count" : 7
}
]
}
}
}
Metic Aggregation
Metic会基于数据集计算的结果,除了在字段上进行计算。同意也支持在脚本产生的结果上进行计算。输出一个值的计算:
- min
- max
- sum
- avg
- cardinality 去重计数
输出多个值
- stats
- percentiles
- percentiles_ranks
例子
GET chengji/_search
{
"size":0,
"aggs": {
"avgScore": {
"avg": {
"field": "Score"
}
},
"maxScore":{
"max": {
"field": "Score"
}
},
"minScore":{
"min": {
"field": "Score"
}
},
"card":{
"cardinality": {
"field": "Score"
}
}
}
}
响应
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 21,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"minScore" : {
"value" : 37.0
},
"avgScore" : {
"value" : 76.71428571428571
},
"maxScore" : {
"value" : 97.0
},
"card" : {
"value" : 20
}
}
}
嵌套查询
GET chengji/_search
{
"size": 0,
"aggs": {
"coursep": {
"terms": {
"field": "course"
},
"aggs": {
"sexp": {
"terms": {
"field": "sex"
}
}
}
}
}
}
响应
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 21,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"coursep" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "数学",
"doc_count" : 7,
"sexp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "男",
"doc_count" : 5
},
{
"key" : "女",
"doc_count" : 2
}
]
}
},
{
"key" : "英语",
"doc_count" : 7,
"sexp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "男",
"doc_count" : 5
},
{
"key" : "女",
"doc_count" : 2
}
]
}
},
{
"key" : "语文",
"doc_count" : 7,
"sexp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "男",
"doc_count" : 5
},
{
"key" : "女",
"doc_count" : 2
}
]
}
}
]
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号