代码中的软件工程-menu项目分析
本篇博客是利用VSCode+GCC工具集为主要环境编译调试我们在孟宁老师的高软课程中学习到的课程项目-menu程序,通过分析源代码,分析其中体现的软件工程方法,规范和工程思想。通过此次课程项目的实践,使我对软件工程中的模块化,可重入设计和线程安全概念有了更深的认识。
一.编译和调试环境配置
我们首先在VSCode编辑器中添加插件c/c++;
方法:打开VSCode 点击最左侧的管理扩展插件图标(Ctrl+Shift+X),在插件市场里搜索 C++,找到 扩展插件“C/C++ for Visual Studio Code”,点击 Install 安装即可。

但是VSCode 的 C/C++插件并不包含 C/C++编译器和调试器,所以我们需要自己安装 C/C++编译器和调试器。我使用的windows10系统,在这里选择Mingw64作为我们的编译和调试器。
我们可以通过孟宁老师提供的链接下载Mingw-w64的安装文件mingw-w64-install.exe,下载后运行如下图
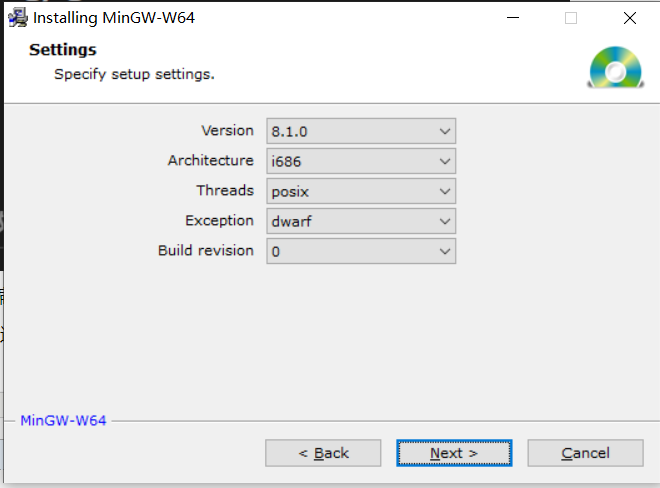
安装过程中有几个选项需要说明:
Version:制定版本号,没有特殊要求就用最新版;
Architecture:跟操作系统有关,64 位选择 x86_64,32 位选择 i686;
Threads:设置线程标准可选 posix 或 win32;
Exception:设置异常处理系统,x86_64 可选为 seh 和 sjlj,i686 为 dwarf 和 sjlj;
Build revision:构建版本号,选择最大即可。
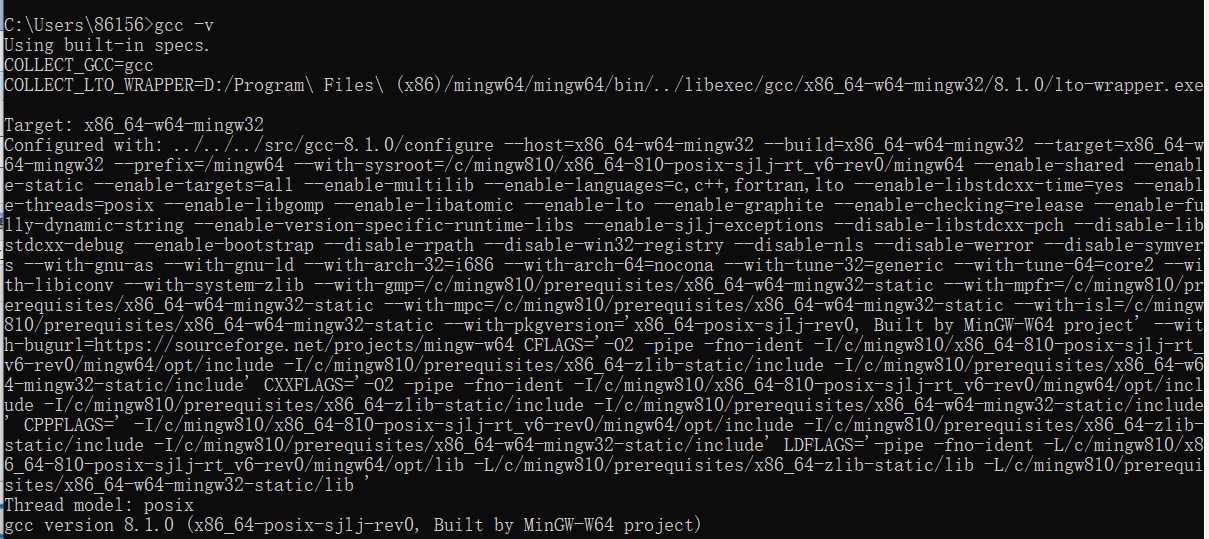
安装完成并配置完环境变量后通过cmd命令行下输入gcc -v 检查是否安装成功。
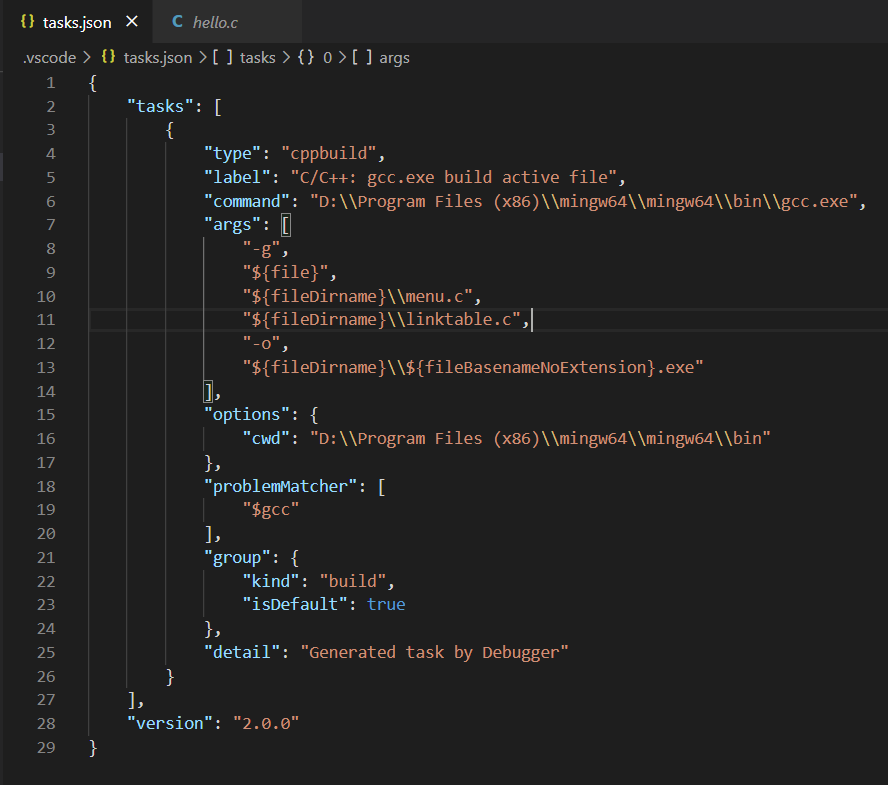
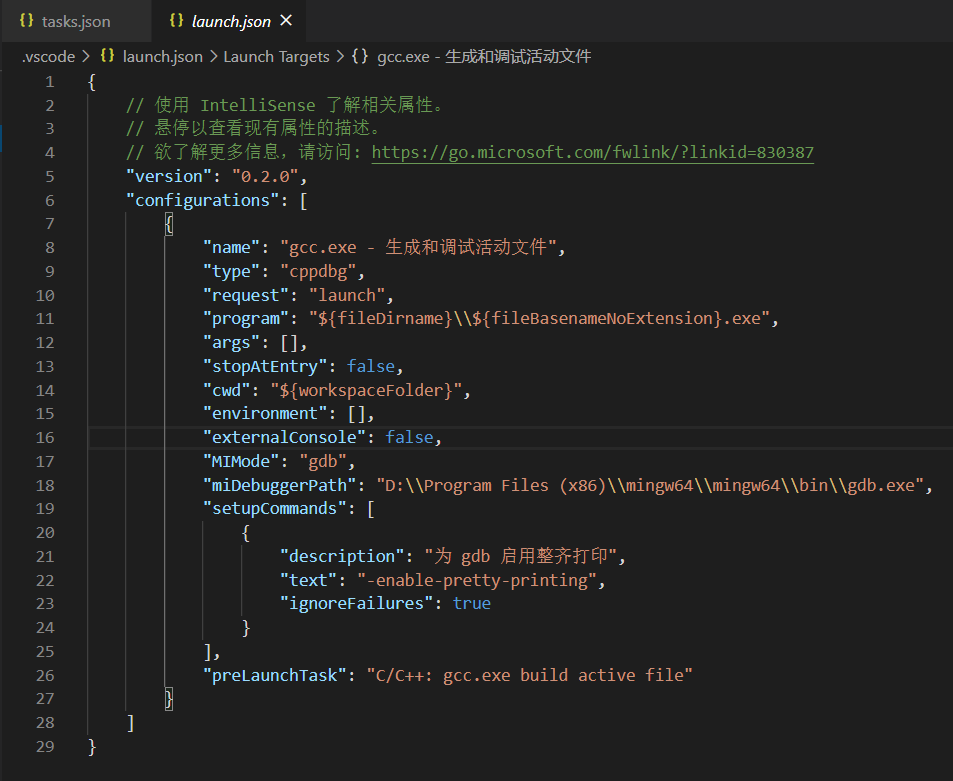
进入 VSCode,将项目menu文件夹放入工作区,并在VSCode 中选择 (终端)Terminal -> (配置任务)Configure Default Build Task,编辑弹出的 json 文件。其中
- launch.json:调试设置
- tasks.json:构建任务设置
我们以hello.c文件为例,点击F5进行调试,可以发现运行成功。
二.代码的理解与分析
1.模块化设计
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离 (SoC, Separation of Concerns)。关注点的分离在软件工程领域是最重要的原则,我们习惯上称为模块化,翻译成我们中文的表述其实就是“分而治之”的方法,当我们把复杂的问题分解成一个个简单的问题是,就可以减少出错的情形。
通常我们会把软件设计中的模块化程度作为软件设计有多好的一个重要指标,一般情况使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。内聚是指每一个单独模块内部的各元素的依赖程度,耦合则是指各个不同的模块之间的依赖程度,我们在设计模块时,要做到一个软件模块只做一件事,各个模块解耦合,只需设计接口用于模块之间的互相调用, 通常我们追求“高内聚低耦合”。
现在我们结合孟宁老师课上的menu代码案例进行分析,通过观察src文件夹内的十个lab文件夹,可以发现我们的menu小程序一步步实现了代码的构建过程,下面我将简要分析一下几次迭代过程中解决了什么问题以及体现的软件工程思想。
lab2:初始情况,文件是用if...else编写的一个框架代码,大致描述menu程序的实现逻辑。但是当我们的cmd命令过多时,代码的if...else语句行太长,代码不易于阅读且后期难以维护。
#include <stdio.h> #include <stdlib.h> int main() { char cmd[128]; while(1) { scanf("%s", cmd); if(strcmp(cmd, "help") == 0) { printf("This is help cmd!\n"); } else if(strcmp(cmd, "quit") == 0) { exit(0); } else { printf("Wrong cmd!\n"); } } }
lab3.1和lab3.2:lab3.1为了解决lab2存在的问题,引入了链表这种数据结构把各种命令、命令的详细描述以及命令的对应函数放在一起,将数据结构和它的操作从菜单业务中分离出来,并将可能重复用到的代码段封装到函数内部(分别封装了 Help() 函数和Quit() 函数),而lab3.2相对3.1的改进就是将3.1中主函数main()里遍历结构体链表寻找cmd的操作封装到了函数 FindCmd() 内,通过这个新函数 FindCmd() 来为用户提供使用帮助,很大程度上提高了代码的可用性。
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode;
下面是main()和help()的代码块:
int main() { /* cmd line begins */ while(1) { char cmd[CMD_MAX_LEN]; printf("Input a cmd number > "); scanf("%s", cmd); tDataNode *p = FindCmd(head, cmd); if( p == NULL) { printf("This is a wrong cmd!\n "); continue; } printf("%s - %s\n", p->cmd, p->desc); if(p->handler != NULL) { p->handler(); } } } int Help() { ShowAllCmd(head); return 0; }
lab3.3:我们关心的模块化思想则是在lab3.3中得到了极大的展现,在lab3.3中,代码部分的内容没有发生改变,但是将结构体代码独立到一个文件 linklist.h 内,使用了模块化的思想降低了码农的阅读与修改代码的难度,同时也使代码的逻辑层次更加明显。我们通过在linklist.h 文件内对函数的接口进行声明,然后将其中实现的具体细节存储在linklist.c文件,极大程度上提高了阅读效率。
下面是linklist.h文件内接口代码:
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head);
具体的实现细节代码如linklist.c内所示:
tDataNode* FindCmd(tDataNode * head, char * cmd) { if(head == NULL || cmd == NULL) { return NULL; } tDataNode *p = head; while(p != NULL) { if(!strcmp(p->cmd, cmd)) { return p; } p = p->next; } return NULL; } int ShowAllCmd(tDataNode * head) { printf("Menu List:\n"); tDataNode *p = head; while(p != NULL) { printf("%s - %s\n", p->cmd, p->desc); p = p->next; } return 0; }
2.可重用接口
重用分为消费者重用和生产者重用,消费者重用是指软件开发者在项目中重用已有的一些软件模块代码,以加快项目工作进度。生产者重用需要重点考虑设计通用的模块,通用的接口等因素。而接口是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。
接口规格一般包括五个基本元素:1)接口的目的;2)接口使用前所需要满足的条件,一般称为前置条件或假定条件;3)使用接口的双方遵守的协议规范;4)接口使用之后的效果,一般称为后置条件;5)接口所隐含的质量属性。
在第一小节中,我们通过分析代码知道,lab3 几个版本对 lab2 做了关于模块化设计的优化,但是其定义的数据结构和操作数据结构的函数与具体实现存在耦合。为了进一步优化重构代码,我们设计了关于链表操作的接口,以达到可重用链表操作的目的。于是在接下来的lab4和lab5版本,我们创建了新的结构体Linktable,Linktable比之前的linklist增加了很多内容,可以更方便的增删节点,而且更进一步的实现了模块化,内聚程度更进一步,与menu模块之间的耦合度也得到降低。我们从中找了一个最典型的查找节点函数:
/* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode,void * args); */ tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args);
调用者在使用这个接口时,需要提供一个链表,一个 callback 函数以及一个额外参数,这么做的好处是大大提高了接口的可重用性,数据结构层只是负责遍历链表,同时使用上层提供的函数来检查是否查找到目标节点,这样应用层只需要根据业务构建具体的链表数据和定制的 callback 函数然后交给数据结构层操作就行了。
在menu.c文件中,我们可以从如下代码了解到实际的接口调用情况:
int SearchConditon(tLinkTableNode * pLinkTableNode,void * arg) { char * cmd = (char*)arg; tDataNode * pNode = (tDataNode *)pLinkTableNode; if(strcmp(pNode->cmd, cmd) == 0) { return SUCCESS; } return FAILURE; }
3.线程安全
在了解线程安全之前,我们首先要知道什么是可重入函数。可重入函数是指可以由多个任务并发使用,而不必担心数据错误。与之相对的不可重入函数则不能由超过一个任务所共享,除非能确保函数的互斥。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。
如果代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行某一段代码,如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的,反之则不是线程安全的。一般来说, 不可重入的函数一定不是线性安全的,但可重入的函数不一定是线性安全的,比如不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题。
确保线程安全最基本的操作是加锁,当对一个共享变量进行操作时,对其加锁,确保其他线程不会同时修改该变量,当操作完毕后进行解锁。
此次的menu项目中正是使用加锁的方式实现的线程安全,具体代码节选如下:
/* * LinkTable Type */ //在链表定义中添加用于互斥操作的线程锁 struct LinkTable { tLinkTableNode *pHead; tLinkTableNode *pTail; int SumOfNode; pthread_mutex_t mutex;//线程锁 }; //linktable.c中关于添加节点时使用线程锁保证线程安全的例子 pthread_mutex_lock(&(pLinkTable->mutex));//加锁 if(pLinkTable->pHead == NULL) { pLinkTable->pHead = pNode; } if(pLinkTable->pTail == NULL) { pLinkTable->pTail = pNode; } else { pLinkTable->pTail->pNext = pNode; pLinkTable->pTail = pNode; } pLinkTable->SumOfNode += 1 ; pthread_mutex_unlock(&(pLinkTable->mutex));//解锁 return SUCCESS;
pthread_mutex_unlock这个函数其实就是对资源进行加锁,当资源没有释放时,别的进程和线程就不能使用该段临界区,这样我们的项目就可以安全的运行在多线程环境中了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号