

R语言
R语言
R 语言是为数学研究工作者设计的一种数学编程语言,主要用于统计分析、绘图、数据挖掘。R 语言与 C 语言都是贝尔实验室的研究成果,但两者有不同的侧重领域,R 语言是一种解释型的面向数学理论研究工作者的语言,而 C 语言是为计算机软件工程师设计的。
R 语言特点
- R 语言环境软件属于 GNU 开源软件,兼容性好、使用免费
- 语法十分有利于复杂的数学运算
- 数据类型丰富,包括向量、矩阵、因子、数据集等常用数据结构
- 代码风格好,可读性强
R语言环境安装
官网: https://cran.r-project.org/
brew install r
R交互式运行
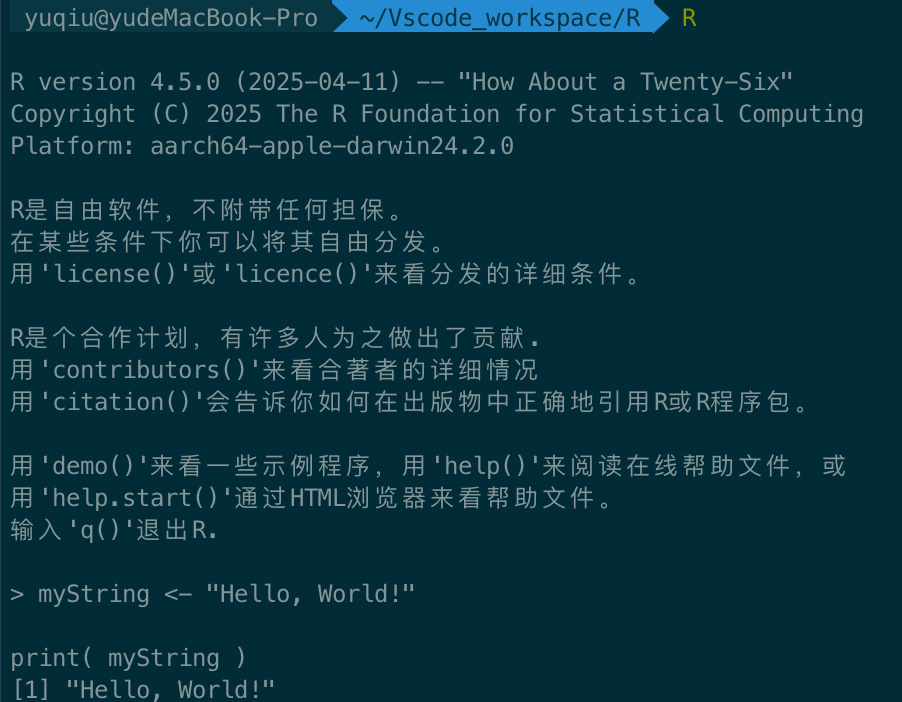
Rscritp运行文件
使用Rscritp hello.R
myString <- "Hello, World!"
print( myString )

变量
R 语言的有效的变量名称由字母,数字以及点号 . 或下划线 _ 组成。变量名称以字母或点开头。
建议使用下划线命名(snake_case)风格,兼容性好,可读性高,越来越主流。
- ✅ 推荐风格
| 命名风格 | 示例 | 说明 |
|---|---|---|
| 小写 + 下划线 | total_sum |
✅ R 社区最常见风格,清晰、易读,适合长期维护 |
| 小写 + 驼峰 | totalSum |
类似 JavaScript 命名风格,有一定接受度 |
| 点分命名(老派 R) | total.sum |
老式 R 风格,容易与隐藏变量混淆(如 .total),不推荐 |
| 全小写无分隔符 | totalsum |
不易阅读,变量越长越难以理解 |
| 全大写 | TOTAL_SUM |
常用于常量,但 R 并无真正“常量”语义,容易混淆 |
| 小写 + 数字尾缀 | item1, item2 |
可用于循环生成变量,但不建议用于正式逻辑 |
| 随意拼音命名 | mingzi, zongjia |
不利于协作开发,影响跨语言可读性 |
| 单字符缩写 | x, y, a |
仅适用于非常短的临时脚本或数学公式,正式项目中应避免 |
-
🚫 不推荐做法
• 使用类似 T, F, c, mean 等 R 内置函数/常量作为变量名,会引发预料外的问题。
• 命名过短无意义(如 a, b1, xx2),调试时令人头大。
• 使用拼音,除非是极短脚本或自己用(协作开发尽量英文)。 -
💡 命名建议
• 名字要表达 意图:user_count 比 uc 清晰得多。
• 计数类用 count、逻辑型用 is、列表用 _list。
• 标量一般不用复数,集合/数组用复数名表示。
变量赋值
最新版本的 R 语言的赋值可以使用左箭头 <-、等号 = 、右箭头 -> 赋值:
| 场景 | 建议使用赋值符号 |
|---|---|
| 一般变量赋值 | <- |
| 函数参数赋值 | = |
| 特殊表达 / 可读性 | ->(少用) |
常用语法
输入输出
R 语言与 node.js 和 Python 一样,是解释型的语言,所以我们往往可以像使用命令行一样使用 R 语言。
R
#打印输出
print(123)
#需要输出结果的拼接
cat(1, "加", 1, "等于", 2, '\n')
输出内容到文件
cat()函数
#覆盖写入
cat("GOOGLE", file="/Users/yuqiu/Vscode_workspace/R/r_test.txt")
#追加写入
cat("GOOGLE", file="/Users/yuqiu/Vscode_workspace/R/r_test.txt", append=TRUE)

sink()
#控制台输出的文字直接输出到文件中,控制台将不会显示输出,开启时"覆盖写入"
sink("/Users/yuqiu/Vscode_workspace/R/r_testlog.txt")
#保留控制台的输出,开启时"覆盖写入"操作
sink("/Users/yuqiu/Vscode_workspace/R/r_testlog.txt", split=TRUE)
#取消输出到文件,调用无参数的 sink
sink()
文字输入
#从文件读入文字,所读取的文本文件每一行 (包括最后一行) 的结束必须有换行符,否则会报错。
readLines("/Users/yuqiu/Vscode_workspace/R/r_testlog.txt")
除了文字的简单输入输出以外,R 还提供了很多输入数据和输出数据的方法,R 语言最方便的地方就是可以将数据结构直接保存到文件中去,而且支持保存为 CSV、Excel 表格等形式,并且支持直接地读取。这对于数学研究者来说无疑是非常方便的。
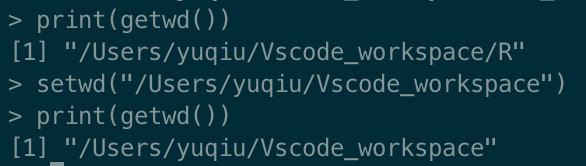
工作目录
文件操作,需要设置文件的路径,R 语言可以通过以下两个函数来获取和设置当前的工作目录:
getwd() : 获取当前工作目录
setwd() : 设置当前工作目录
# 当前工作目录
print(getwd())
# 设置当前工作目录
setwd("/Users/yuqiu/Vscode_workspace/R")
# 查看当前工作目录
print(getwd())
注释
R 语言只支持单行注释,注释符号为 #;如果有多行注释只需要在每一行添加 # 号
#if(FALSE) 多行注释变通写法
if(FALSE) {
"
这是一个多行注释的实例
注释内容放在单引号或双引号之间
"
}
myString <- "Hello, World!"
print ( myString)
运算符
赋值、基本运算、关系运算、逻辑运算、数学函数、概率分布函数。
📝 赋值方式
R 支持三种赋值方式:
| 场景 | 推荐符号 | 示例 | 说明 |
|---|---|---|---|
| 一般变量赋值 | <- |
x <- 10 |
最常见,也是 R 社区推荐的方式 |
| 函数参数赋值 | = |
sum(x = 10) |
仅用于函数参数传递 |
| 特殊场景/可读性 | -> |
10 -> x |
不推荐,少用 |
a <- 123
b = 456
print(a + b) # 输出: [1] 579
➕ 数学运算符
| 优先级 | 符号 | 含义 |
|---|---|---|
| 1 | () |
括号 |
| 2 | ^ |
幂运算 |
| 3 | %%, %/% |
取余、整除 |
| 4 | *, / |
乘法、除法 |
| 5 | +, - |
加法、减法 |
1 + 2 * 3 # [1] 7
(1 + 2) * 3 # [1] 9
3 %% 2^2 # [1] 3
10 / 3 %/% 2 # [1] 10
🔍 关系运算符
用于向量间逐元素比较,返回布尔向量。
| 运算符 | 说明 |
|---|---|
> |
大于 |
< |
小于 |
== |
等于 |
!= |
不等于 |
>= |
大于等于 |
<= |
小于等于 |
v <- c(2, 4, 6, 9)
t <- c(1, 4, 7, 9)
print(v > t) # [1] TRUE FALSE FALSE FALSE
⚙️ 逻辑运算符
| 运算符 | 说明 |
|---|---|
& |
元素级 与 |
| |
元素级 或 |
! |
非 |
&& |
仅判断首元素 与 |
|| |
仅判断首元素 或 |
v <- c(3, 1, TRUE, 2+3i)
t <- c(4, 1, FALSE, 2+3i)
print(v & t) # [1] TRUE TRUE FALSE TRUE
print(!v) # [1] FALSE FALSE FALSE FALSE
🧾 赋值运算符
| 运算符 | 方向 | 说明 |
|---|---|---|
<-, =, <<- |
向左赋值 | |
->, ->> |
向右赋值 |
v1 <- c(1, 2)
1:2 -> v2
print(v1) # [1] 1 2
print(v2) # [1] 1 2
🧩 其他运算符
| 运算符 | 说明 |
|---|---|
: |
创建整数序列 |
%in% |
判断元素是否属于集合 |
%*% |
矩阵乘法 |
1:5 # [1] 1 2 3 4 5
3 %in% 1:5 # [1] TRUE
M <- matrix(1:6, nrow=2)
M %*% t(M) # 矩阵乘法
🧮 数学函数
| 函数 | 说明 |
|---|---|
sqrt(n) |
平方根 |
exp(n) |
e 的 n 次幂 |
log(m, n) |
对数(以 n 为底) |
log10(m) |
常用对数 |
sqrt(4) # [1] 2
log(2, 4) # [1] 0.5
📐 取整函数
| 函数 | 说明 |
|---|---|
round(n) |
四舍五入 |
floor(n) |
向下取整 |
ceiling(n) |
向上取整 |
round(2.5) # [1] 2
floor(2.9) # [1] 2
ceiling(2.1) # [1] 3
⚠️ 注意:R 的 round 实现偏向“偶数舍入”(即“银行家舍入”)。
📐 三角函数(弧度制)
sin(pi/6) # [1] 0.5
cos(pi/4) # [1] 0.7071068
tan(pi/3) # [1] 1.732051
asin(0.5) # [1] 0.5235988
🎲 概率分布函数
以正态分布为例:
| 函数前缀 | 功能 |
|---|---|
d |
密度函数 |
p |
分布函数 |
q |
分位数函数 |
r |
随机样本生成 |
dnorm(0) # [1] 0.3989423
pnorm(0) # [1] 0.5
qnorm(0.95) # [1] 1.644854
rnorm(3, 5, 2) # 生成 3 个均值 5、标准差 2 的正态分布随机数
R 还支持 pois(泊松)、binom(二项式)等其他分布,推荐进阶查阅《概率论与数理统计》。
数据类型
基本数据类型,R 的三种基础数据类型如下:
• 数字型(numeric)
• 逻辑型(logical)
• 字符型(character)
# 数字一般型
123
-0.125
# 数字型科学计数法
1.23e2
-1.25E-1
# 逻辑型:区分大小写,true、True 是非法的
TRUE
FALSE
#字符串可由单引号或双引号包围
'runoob' == "runoob" # [1] TRUE
#变量的定义:R 是弱类型语言,变量无需声明类型,赋值即定义
a = 1
b <- TRUE
c = "abc"
对象类型(复杂结构)
R 中更高层次的数据结构主要包括:
• 向量(vector)
• 列表(list)
• 矩阵(matrix)
• 数组(array)
• 因子(factor)
• 数据框(data.frame)
字符串操作
toupper("Autumn") # "AUTUMN"
tolower("Autumn") # "autumn"
#注意中文在不同编码下的字节数不同(GBK 是 2,UTF-8 是 3)。
nchar("中文", type="bytes") # 4
nchar("中文", type="char") # 2
#截取字符串
substr("123456", 1, 3) # "123"
substring("123456", 4) # "456"
as.numeric("12") # 12
as.character(12.34) # "12.34"
#字符串拆分
strsplit("2019;10;1", ";") # [[1]] "2019" "10" "1"
#字符串替换
gsub("/", "-", "2019/10/1") # "2019-10-1"
#支持 Perl 风格正则
gsub("[[:alpha:]]+", "$", "Two words") # "$ $"
paste() 函数用于使用指定对分隔符来对字符串进行连接,默认的分隔符为空格。
paste(..., sep = " ", collapse = NULL)
... : 字符串列表
sep : 分隔符,默认为空格
collapse : 两个或者更多字符串对象根据元素对应关系拼接到一起,在字符串进行连接后,再使用 collapse 指定对连接符进行连接
a <- "Google"
b <- 'Baidu'
c <- "Taobao"
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(letters[1:6],1:6, sep = "", collapse = "="))
paste(letters[1:6],1:6, collapse = ".")
[1] "Google Baidu Taobao"
[1] "Google-Baidu-Taobao"
[1] "a1=b2=c3=d4=e5=f6"
[1] "a 1.b 2.c 3.d 4.e 5.f 6"
format()函数用于格式化字符串,format()可作用于字符串或数字。
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
x : 输入对向量
digits : 显示的位数
nsmall : 小数点右边显示的最少位数
scientific : 设置科学计数法
width : 通过开头填充空白来显示最小的宽度
justify:设置位置,显示可以是左边、右边、中间等。
# 显示 9 位,最后一位四舍五入
result <- format(23.123456789, digits = 9)
print(result)
# 使用科学计数法显示
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# 小数点右边最小显示 5 位,没有的以 0 补充
result <- format(23.47, nsmall = 5)
print(result)
# 将数字转为字符串
result <- format(6)
print(result)
# 宽度为 6 位,不够的在开头添加空格
result <- format(13.7, width = 6)
print(result)
# 左对齐字符串
result <- format("Baidu", width = 9, justify = "l")
print(result)
# 居中显示
result <- format("Baidu", width = 10, justify = "c")
print(result)
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Baidu "
[1] " Baidu "
向量(vector)
#创建向量
a = c(3, 4)
b = c(5, 0)
a + b # [1] 8 4
#索引访问,注意:下标从 1 开始!
a = c(10, 20, 30, 40, 50)
a[2] # [1] 20
a[1:4] # [1] 10 20 30 40
a[c(1, 3, 5)] # [1] 10 30 50
a[c(-1, -5)] # [1] 20 30 40
#向量运算,常见数学函数也适用于向量:sqrt、exp、log
c(1.1, 1.2, 1.3) - 0.5 # [1] 0.6 0.7 0.8
a = c(1, 2)
a ^ 2 # [1] 1 4
#向量排序和统计
a = c(1, 3, 5, 2, 4, 6)
sort(a) # 升序
rev(a) # 反转
order(a) # 返回排序后的下标
a[order(a)] # 排序后的向量
sum(1:5) # 15
mean(1:5) # 3
sd(1:5) # 1.581139
range(1:5) # [1] 1 5
#向量生成
1:10
seq(1, 9, 2) # [1] 1 3 5 7 9
seq(0, 1, length.out=3) # [1] 0.0 0.5 1.0
rep(0, 5) # [1] 0 0 0 0 0
#NA 与 NULL 的区别 NA:缺失值,占位; NULL:不存在,不占位置。
length(c(NA, NA, NULL)) # [1] 2
c(NA, NA, NULL, NA) # [1] NA NA NA
逻辑型向量与操作
a = c(11, 12, 13)
b = a > 12 # [1] FALSE FALSE TRUE
which(b) # [1] 3
vector = c(10, 40, 78, 64, 53, 62, 69, 70)
vector[which(vector >= 60 & vector < 70)] # [1] 64 62 69
#all() 与 any()
all(c(TRUE, TRUE)) # TRUE
any(c(FALSE, TRUE)) # TRUE
矩阵(matrix)
#创建矩阵
vector = c(1, 2, 3, 4, 5, 6)
matrix(vector, 2, 3) # 默认按列填充
matrix(vector, 2, 3, byrow=TRUE) # 按行填充
#访问元素
m1[1, 1] # 第一行第一列
m1[1, 3] # 第一行第三列
#设置行列名
colnames(m1) = c("x", "y", "z")
rownames(m1) = c("a", "b")
m1["a", ]
#矩阵运算
m1 = matrix(c(1, 2), 1, 2)
m2 = matrix(c(3, 4), 2, 1)
m1 %*% m2 # 矩阵乘法
A = matrix(c(1, 3, 2, 4), 2, 2)
solve(A) # 求逆矩阵
#apply 函数
A = matrix(c(1, 3, 2, 4), 2, 2)
apply(A, 1, sum) # 按行求和
apply(A, 2, sum) # 按列求和
R 语言中的判断语句(条件语句)
条件判断的核心是:根据布尔表达式的结果执行相应代码块。
R 支持以下几种判断语句:
• if 语句
• if...else 语句
• if...else if...else 多分支结构
• switch 语句(适用于多值匹配)
#if 语句
x <- 50L
if (is.integer(x)) {
print("X 是一个整数")
}
# 输出:
# [1] "X 是一个整数"
#if…else 语句
x <- c("google", "baidu", "taobao")
if ("baidu" %in% x) {
print("包含 baidu")
} else {
print("不包含 baidu")
}
# 输出:
# [1] "包含 baidu"
#if…else if…else 多分支结构
x <- c("google", "runoob", "taobao")
if ("weibo" %in% x) {
print("第一个 if 包含 weibo")
} else if ("runoob" %in% x) {
print("第二个 if 包含 runoob")
} else {
print("没有找到")
}
# 输出:
# [1] "第二个 if 包含 runoob"
#switch 语句
#使用整数匹配:整数表示返回第几个 case 值;超出范围返回 NULL。
x <- switch(
3,
"google",
"baidu",
"taobao",
"weibo"
)
print(x)
# 输出:
# [1] "taobao"
#使用字符串匹配,字符串则根据名字匹配对应的 case
you.like <- "baidu"
switch(you.like,
google = "www.google.com",
baidu = "www.baidu.com",
taobao = "www.taobao.com")
# 输出:
# [1] "www.baidu.com"
#匹配失败返回 NULL
x <- switch(4, "google", "baidu", "taobao")
print(x)
# 输出:
# NULL
循环
R 语言提供的循环类型有:
repeat 循环
while 循环
for 循环
R 语言提供的循环控制语句有:
break 语句
Next 语句
#repeat
repeat {
# 相关代码
if(condition) {
break
}
}
#while
while(condition)
{
statement(s);
}
#for
for (value in vector) {
statements
}
函数
函数是 R 中的核心构建块,用于封装代码逻辑、提高复用性。R 提供了大量内置函数,也允许用户定义自己的函数。
#函数的基本结构
function_name <- function(arg1, arg2, ...) {
# 函数体
return(输出结果)
}
#加法函数
add_numbers <- function(x, y) {
result <- x + y
return(result)
}
sum_result <- add_numbers(3, 4)
print(sum_result) # 输出:7
#不带参数的函数
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
new.function()
# 输出:1, 4, 9, 16, 25
#带参数
new.function <- function(a, b, c) {
result <- a * b + c
print(result)
}
new.function(5, 3, 11) # 输出:26
new.function(a = 11, b = 5, c = 3) # 输出:58
#设置默认参数值
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
new.function() # 输出:18
new.function(9, 5) # 输出:45
#懒惰计算(Lazy Evaluation)
# R 会延迟对参数的求值,直到真正用到它:
new.function <- function(a, b) {
print(a^2)
print(b) # 未传参会报错
}
new.function(6)
# 输出:
# 36
# Error in print(b): 缺少参数"b"
内置函数
#sum():求和
x <- c(1, 2, 3, 4, 5)
sum(x) # 输出:15
#mean():求平均值
mean(25:82) # 输出:53.5
#seq():生成序列
seq(32, 44) # 输出:32 33 34 ... 44
#paste():字符串拼接
paste("Hello", "World") # 输出:"Hello World"
#length():元素个数
length(c(1, 2, 3)) # 输出:3
#str():结构查看
x <- c(1, 2, 3, 4, 5)
str(x)
# 输出:num [1:5] 1 2 3 4 5
#矩阵支持
matrix <- matrix(1:9, nrow = 3)
sum(matrix) # 输出:45
mean(matrix) # 输出:5
length(matrix) # 输出:9
str(matrix)
# 输出:int [1:3, 1:3] 1 2 3 4 5 6 7 8 9
列表
列表是 R 语言的对象集合,可以用来保存不同类型的数据,可以是数字、字符串、向量、另一个列表、矩阵、数据框等,还可以包含矩阵和函数。
列表是一种灵活的数据结构,可以存储和操作多种类型的数据对象。
#list() 函数创建列表,包含了字符串、向量和数字
list_data <- list("baidu", "google", c(11,22,33), 123, 51.23, 119.1)
print(list_data)
#使用 c() 函数来创建列表,也可以使用该函数将多个对象合并为一个列表
my_list <- c(object1, object2, object3)
# 列表包含向量、矩阵、列表
list_data <- list(c("Google","Baidu","Taobao"), matrix(c(1,2,3,4,5,6), nrow = 2),
list("baidu",12.3))
# 给列表元素设置名字
names(list_data) <- c("Sites", "Numbers", "Lists")
# 显示列表
print(list_data)
# 显示第一个列表
print(list_data[1])
# 访问列表的第三个元素
print(list_data[3])
# 访问第一个向量元素
print(list_data$Numbers)
#操作列表元素
# 添加元素
list_data[4] <- "新元素"
print(list_data[4])
# 删除元素
list_data[4] <- NULL
# 删除后输出为 NULL
print(list_data[4])
# 更新元素
list_data[3] <- "我替换来第三个元素"
print(list_data[3])
# 循环
# 创建一个包含数字和字符的列表
my_list <- list(1, 2, 3, "a", "b", "c")
# 使用 for 循环遍历列表中的每个元素
for (element in my_list) {
print(element)
}
# 合并
# 创建两个列表
list1 <- list(1,2,3)
list2 <- list("Google","Runoob","Taobao")
# 合并列表
merged.list <- c(list1,list2)
# 显示合并后的列表
print(merged.list)
#列表转换为向量
# 创建列表
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# 转换为向量
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# 两个向量相加
result <- v1+v2
print(result)
总结
R 语言列表操作和函数:
创建列表:
使用 c() 函数:例如,list1 <- c(1, 2, 3) 创建一个包含 1、2 和 3 的列表。
使用 list() 函数:例如,list2 <- list(1, "a", TRUE) 创建一个包含不同类型元素的列表。
访问列表元素:
使用索引:通过索引访问列表中的元素。例如,list1[1] 返回列表中的第一个元素。
使用元素名称:如果列表中的元素有名称,可以使用名称来访问它们。例如,list3 <- list(a = 1, b = 2) 可以通过 list3$a 和 list3$b 来访问元素。
列表操作:
长度:使用 length() 函数获取列表的长度。例如,length(list1) 返回列表 list1 的长度。
合并:使用 c() 函数或 append() 函数将两个或多个列表合并为一个列表。例如,list4 <- c(list1, list2) 合并列表 list1 和 list2。
增加元素:使用 c() 函数将元素添加到现有列表中。例如,list1 <- c(list1, 4) 将 4 添加到列表 list1 的末尾。
删除元素:使用索引和负索引操作符 - 删除列表中的元素。例如,list1 <- list1[-2] 删除列表 list1 中的第二个元素。
列表循环:
for 循环:使用 for 循环遍历列表中的元素。例如,for (element in list1) { ... } 遍历列表 list1 中的每个元素。
lapply() 函数:将一个函数应用于列表中的每个元素,并返回结果列表。例如,new_list <- lapply(list1, function(x) x * 2) 将列表 list1 中的每个元素乘以 2。
矩阵
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
矩阵里的元素可以是数字、符号或数学式。
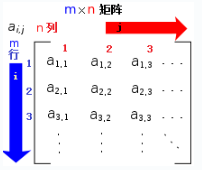
一个 M x N 的矩阵是一个由 M(row) 行 和 N 列(column)元素排列成的矩形阵列。
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,dimnames = NULL)
参数说明:
data 向量,矩阵的数据
nrow 行数
ncol 列数
byrow 逻辑值,为 FALSE 按列排列,为 TRUE 按行排列
dimname 设置行和列的名称
# 创建矩阵
# byrow 为 TRUE 元素按行排列
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Ebyrow 为 FALSE 元素按列排列
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# 定义行和列的名称
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)
#转置矩阵
#R 语言矩阵提供了 t() 函数,可以实现矩阵的行列互换。例如有个 m 行 n 列的矩阵,使用 t() 函数就能转换为 n 行 m 列的矩阵
# 创建一个 2 行 3 列的矩阵
M = matrix( c(2,6,5,1,10,4), nrow = 2,ncol = 3,byrow = TRUE)
print(M)
# 转换为 3 行 2 列的矩阵
print(t(M))
[,1] [,2] [,3]
[1,] 2 6 5
[2,] 1 10 4
[1] "-----转换-----"
[,1] [,2]
[1,] 2 1
[2,] 6 10
[3,] 5 4
#访问矩阵元素
# 定义行和列的名称
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# 创建矩阵
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)
# 获取第一行第三列的元素
print(P[1,3])
# 获取第四行第二列的元素
print(P[4,2])
# 获取第二行
print(P[2,])
# 获取第三列
print(P[,3])
#矩阵计算
# 创建 2 行 3 列的矩阵
matrix1 <- matrix(c(7, 9, -1, 4, 2, 3), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(6, 1, 0, 9, 3, 2), nrow = 2)
print(matrix2)
# 两个矩阵相加
result <- matrix1 + matrix2
cat("相加结果:","\n")
print(result)
# 两个矩阵相减
result <- matrix1 - matrix2
cat("相减结果:","\n")
print(result)
# 两个矩阵相乘
result <- matrix1 * matrix2
cat("相乘结果:","\n")
print(result)
# 两个矩阵相除
result <- matrix1 / matrix2
cat("相除结果:","\n")
print(result)
数组
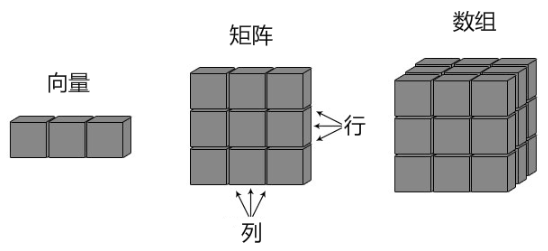
数组也是 R 语言的对象,R 语言可以创建一维或多维数组。
R 语言数组是一个同一类型的集合,前面我们学的矩阵 matrix 其实就是一个二维数组。
向量、矩阵、数组关系可以看下图:
array(data = NA, dim = length(data), dimnames = NULL)
参数说明:
data - 指定数组的数据源,可以是一个向量、矩阵或列表。
dim - 指定数组的维度,可以是一个整数向量或一个表示维度的元组,默认是一维数组。例如,dim = c(2, 3, 4) 表示创建一个 2x3x4 的三维数组。
dimnames - 可选参数,用于指定数组每个维度的名称,可以是一个包含维度名称的列表。
#array函数使用向量创建一维数组
my_vector <- c(1, 2, 3, 4)
my_array <- array(my_vector, dim = c(4))
print(my_array)
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# 创建三维数组
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
#使用 dimnames 参数来设置各个维度的名称
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# 创建数组,并设置各个维度的名称
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,matrix.names))
print(result)
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
#访问数组元素
my_array <- array(1:12, dim = c(2, 3, 2)) # 创建一个3维数组
element <- my_array[1, 2, 1] # 访问第一个维度为1,第二个维度为2,第三个维度为1的元素
print(element)
elements <- my_array[c(1, 2), c(2, 3), c(1, 2)] # 访问多个元素,其中每个维度的索引分别为1和2
print(element)
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# 创建数组
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names, column.names, matrix.names))
# 显示数组第二个矩阵中第三行的元素
print(result[3,,2])
# 显示数组第一个矩阵中第一行第三列的元素
print(result[1,3,1])
# 输出第二个矩阵
print(result[,,2])
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# 创建数组
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# 创建两个不同长度的向量
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector3,vector4),dim = c(3,3,2))
# 从数组中创建矩阵
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# 矩阵相加
result <- matrix1+matrix2
print(result)
# apply() 元素对数组元素进行跨维度计算
参数说明:
X:要应用函数的数组或矩阵。
MARGIN:指定应用函数的维度,可以是1表示行,2表示列,或者c(1, 2)表示同时应用于行和列。
FUN:要应用的函数,可以是内置函数(如mean、sum等)或自定义函数。
...:可选参数,用于传递给函数的其他参数。
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# 创建数组
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# 计算数组中所有矩阵第一行的数字之和
result <- apply(new.array, c(1), sum)
print(result)
因子
因子用于存储不同类别的数据类型,例如人的性别。
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x), nmax = NA)
参数说明:
x:向量。
levels:指定各水平值, 不指定时由x的不同值来求得。
labels:水平的标签, 不指定时用各水平值的对应字符串。
exclude:排除的字符。
ordered:逻辑值,用于指定水平是否有序。
nmax:水平的上限数量。
x <- c("男", "女", "男", "男", "女")
sex <- factor(x)
print(sex)
print(is.factor(sex))
#
x <- c("男", "女", "男", "男", "女",levels=c('男','女'))
sex <- factor(x)
print(sex)
print(is.factor(sex))
# 因子水平标签
sex=factor(c('f','m','f','f','m'),levels=c('f','m'),labels=c('female','male'),ordered=TRUE)
print(sex)
#生成因子水平gl(n, k, length = n*k, labels = seq_len(n), ordered = FALSE)
v <- gl(3, 4, labels = c("Google", "Baidu","Taobao"))
print(v)
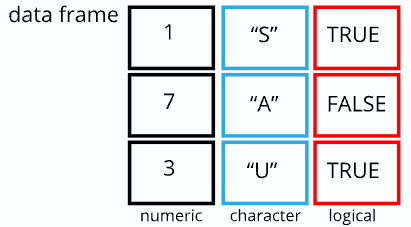
R数据框
数据框(Data frame)可以理解成常说的"表格"。数据框是 R 语言的数据结构,是特殊的二维列表。
数据框每一列都有一个唯一的列名,长度都是相等的,同一列的数据类型需要一致,不同列的数据类型可以不一样。
data.frame(…, row.names = NULL, check.rows = FALSE,
check.names = TRUE, fix.empty.names = TRUE,
stringsAsFactors = default.stringsAsFactors())
…: 列向量,可以是任何类型(字符型、数值型、逻辑型),一般以 tag = value 的形式表示,也可以是 value。
row.names: 行名,默认为 NULL,可以设置为单个数字、字符串或字符串和数字的向量。
check.rows: 检测行的名称和长度是否一致。
check.names: 检测数据框的变量名是否合法。
fix.empty.names: 设置未命名的参数是否自动设置名字。
stringsAsFactors: 布尔值,字符是否转换为因子,factory-fresh 的默认值是 TRUE,可以通过设置选项(stringsAsFactors=FALSE)来修改。
table = data.frame(
姓名 = c("张三", "李四"),
工号 = c("001","002"),
月薪 = c(1000, 2000)
)
print(table) # 查看 table 数据
# 获取数据结构
str(table)
# 显示概要
print(summary(table))
# 提取指定的列
result <- data.frame(table$姓名,table$月薪)
print(result)
# 提取前面两行
print("---输出前面两行----")
result <- table[1:2,]
print(result)
# 读取第 2 、3 行的第 1 、2 列数据:
result <- table[c(2,3),c(1,2)]
print(result)
# 添加部门列
table$部门 <- c("运营","技术","编辑")
print(table)
cbind() 函数将多个向量合成一个数据框(合并列),rbind(合并行)
# 创建向量
sites <- c("Google","Runoob","Taobao")
likes <- c(222,111,123)
url <- c("www.google.com","www.runoob.com","www.taobao.com")
# 将向量组合成数据框
addresses <- cbind(sites,likes,url)
# 查看数据框
print(addresses)
#对两个数据框进行合并可以使用 rbind() 函数
table = data.frame(
姓名 = c("张三", "李四","王五"),
工号 = c("001","002","003"),
月薪 = c(1000, 2000,3000)
)
newtable = data.frame(
姓名 = c("小明", "小白"),
工号 = c("101","102"),
月薪 = c(5000, 7000)
)
# 合并两个数据框
result <- rbind(table,newtable)
print(result)
数据重塑
merge() 函数和 SQL 的 JOIN 功能很相似
merge(x, y, …)
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE,
incomparables = NULL, …)
常用参数说明:
x, y: 数据框
by, by.x, by.y:指定两个数据框中匹配列名称,默认情况下使用两个数据框中相同列名称。
all:逻辑值; all = L 是 all.x = L 和 all.y = L 的简写,L 可以是 TRUE 或 FALSE。
all.x:逻辑值,默认为 FALSE。如果为 TRUE, 显示 x 中匹配的行,即便 y 中没有对应匹配的行,y 中没有匹配的行用 NA 来表示。
all.y:逻辑值,默认为 FALSE。如果为 TRUE, 显示 y 中匹配的行,即便 x 中没有对应匹配的行,x 中没有匹配的行用 NA 来表示。
sort:逻辑值,是否对列进行排序。
# data frame 1
df1 = data.frame(SiteId = c(1:6), Site = c("Google","Runoob","Taobao","Facebook","Zhihu","Weibo"))
# data frame 2
df2 = data.frame(SiteId = c(2, 4, 6, 7, 8), Country = c("CN","USA","CN","USA","IN"))
# INNER JOIN
df1 = merge(x=df1,y=df2,by="SiteId")
print("----- INNER JOIN -----")
print(df1)
# FULL JOIN
df2 = merge(x=df1,y=df2,by="SiteId",all=TRUE)
print("----- FULL JOIN -----")
print(df2)
# LEFT JOIN
df3 = merge(x=df1,y=df2,by="SiteId",all.x=TRUE)
print("----- LEFT JOIN -----")
print(df3)
# RIGHT JOIN
df4 = merge(x=df1,y=df2,by="SiteId",all.y=TRUE)
print("----- RIGHT JOIN -----")
print(df4)
R 语言使用 melt() 和 cast() 函数来对数据进行整合和拆分。
melt() :宽格式数据转化成长格式。
cast() :长格式数据转化成宽格式。
R 包
包是 R 函数、实例数据、预编译代码的集合,包括 R 程序,注释文档、实例、测试数据等。
#查看 R 包的安装目录
.libPaths()
#查看已安装的包
library()
#查看已载入的包
search()
#安装新包
install.packages("要安装的包名")
# 使用镜像仓库安装 XML 包
install.packages("XML", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#配置仓库url, 编辑.Rprofile文件
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
#使用包
library("XML")
Excel文件
#安装
install.packages("xlsx", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# 验证包是否安装
any(grepl("xlsx",installed.packages()))
# 载入包
library("xlsx")
library("xlsx")
# 读取 sites.xlsx 第一个工作表数据
data <- read.xlsx("sites.xlsx", sheetIndex = 1)
print(data)
XML文件
#安装XML
install.packages("XML", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#查看是否安装成功
any(grepl("XML",installed.packages()))
# 载入 XML 包
library("XML")
# 设置文件名
result <- xmlParse(file = "sites.xml")
# 输出结果
print(result)
# 提取根节点
rootnode <- xmlRoot(result)
# 统计数据量
rootsize <- xmlSize(rootnode)
# 输出结果
print(rootsize)
# 查看第 2 个节点数据
print(rootnode[2])
# 查看第 2 个节点的第 1 个数据
print(rootnode[[2]][[1]])
# 查看第 2 个节点的第 3 个数据
print(rootnode[[2]][[3]])
# 转为列表
xml_data <- xmlToList(result)
print(xml_data)
print("============================")
# 输出第一行第二列的数据
print(xml_data[[1]][[2]])
# xml 文件数据转为数据框
xmldataframe <- xmlToDataFrame("sites.xml")
print(xmldataframe)
JSON文件
#安装Json
install.packages("rjson", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#检查
any(grepl("rjson",installed.packages()))
# 载入 rjson 包
library("rjson")
# 获取 json 数据
result <- fromJSON(file = "sites.json")
# 输出结果
print(result)
print("===============")
# 输出第 1 列的结果
print(result[1])
print("===============")
# 输出第 2 行第 2 列的结果
print(result[[2]][[2]])
# 转为数据框
json_data_frame <- as.data.frame(result)
print(json_data_frame)
MySQL
#安装Mysql
install.packages("RMySQL", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#或者安装MariaDB
install.packages("RMariaDB", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#检查是否安装
any(grepl("RMySQL",installed.packages()))
library(RMySQL)
# 连接mysql
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'test',host = 'localhost')
# 查看数据表
dbListTables(mysqlconnection)
# 查询 sites 表,增删改查操作可以通过第二个参数的 SQL 语句来实现
result = dbSendQuery(mysqlconnection, "select * from sites")
# 获取前面两行数据
data.frame = fetch(result, n = 2)
print(data.frame)
绘图
曲线图
curve(expr, from = NULL, to = NULL, n = 101, add = FALSE,
type = "l", xname = "x", xlab = xname, ylab = NULL,
log = NULL, xlim = NULL, …)
# S3 函数的方法
plot(x, y = 0, to = 1, from = y, xlim = NULL, ylab = NULL, …)
柱状图
barplot(H,xlab,ylab,main, names.arg,col,beside)
参数说明:
H 向量或矩阵,包含图表用的数字值,每个数值表示矩形条的高度。
xlab x 轴标签。
ylab y 轴标签。
main 图表标题。
names.arg 每个矩形条的名称。
col 每个矩形条的颜色。
# 设置文件名,输出为 png
png(file = "bar-1.png")
cvd19 = c(83534,2640626,585493)
barplot(cvd19,
main="条形图",
col=c("#ED1C24","#22B14C","#FFC90E"),
names.arg=c("中国","美国","印度"),
family='GB1'
)
饼状图
pie(x, labels = names(x), edges = 200, radius = 0.8,
clockwise = FALSE, init.angle = if(clockwise) 90 else 0,
density = NULL, angle = 45, col = NULL, border = NULL,
lty = NULL, main = NULL, …)
x: 数值向量,表示每个扇形的面积。
labels: 字符型向量,表示各扇形面积标签。
edges: 这个参数用处不大,指的是多边形的边数(圆的轮廓类似很多边的多边形)。
radius: 饼图的半径。
main: 饼图的标题。
clockwise: 是一个逻辑值,用来指示饼图各个切片是否按顺时针做出分割。
angle: 设置底纹的斜率。
density: 底纹的密度。默认值为 NULL。
col: 是表示每个扇形的颜色,相当于调色板。
# 数据准备
info = c(1, 2, 4, 8)
# 命名
names = c("Google", "Baidu", "Taobao", "Weibo")
# 涂色(可选)
cols = c("#ED1C24","#22B14C","#FFC90E","#3f48CC")
# 绘图
pie(info, labels=names, col=cols)
3D饼图
#安装plotrix
install.packages("plotrix", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# 载入 plotrix
library(plotrix)
# 数据准备
info = c(1, 2, 4, 8)
# 命名
names = c("Google", "Baidu", "Taobao", "Weibo")
# 涂色(可选)
cols = c("#ED1C24","#22B14C","#FFC90E","#3f48CC")
# 设置文件名,输出为 png
png(file = "3d_pie_chart.png")
# 绘制 3D 图,family 要设置你系统支持的中文字体库
pie3D(info,labels = names,explode = 0.1, main = "3D 图",family = "STHeitiTC-Light")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号