

软件设计师03-数据库系统
数据库模式
三级模式两级映射
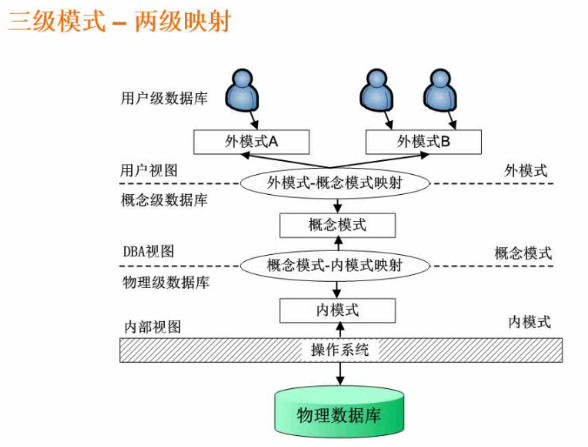
外模式:视图(给用户用)
概念模式:表
内模式:数据的存储
外模式概念模式映射:对表数据进行相应操作得到用户的视图
概念模式内模式映射:调整概念模式物理存储的方式(如Mysql的InnoDB和Myisam存储模式,就是这层映射)
数据库设计过程
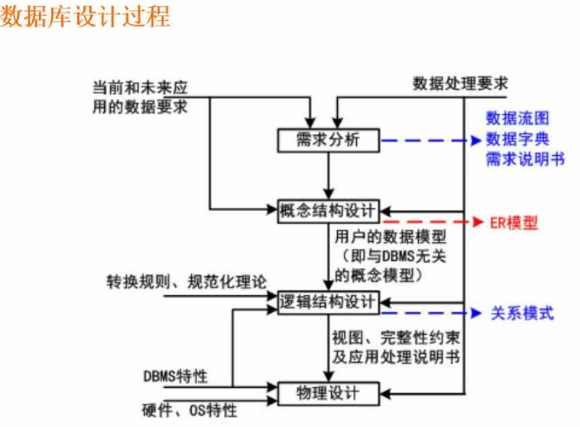
各个阶段及产物
| 阶段 | 产物 |
| 需求分析 | 数据流图、数据字典、需求说明书 |
| 概念结构设计 | ER模型(数据库实际是从这里开始,这里和数据库没关系可以为mysql、oracle) |
| 逻辑结构设计 | 关系模式(转换为表之间的关系) |
| 物理设计 | 融入DBMS的特性(Mysql和Oracle有细小的差别) |
ER模型
矩形表示实体、椭圆表示属性、菱形表示关系。
ER图集成方法

属性冲突:两个表,老师的性别一个用男女,一个用01逻辑值。
命名冲突:老师在一个表里叫教师,在另一个表里叫教职工。
结构冲突:同一个对象在不同应用中具有不同的抽象,同一个实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同。
E-R模型关系模式
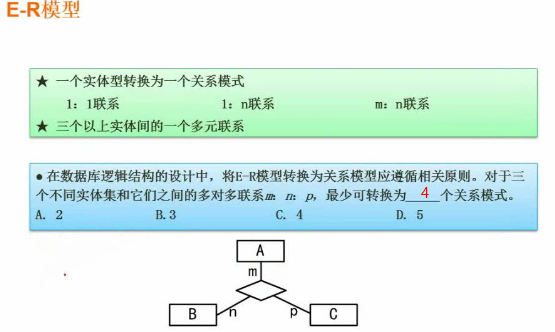
1:1联系:将对应关系记录在任意一边实体中。
1:n联系:将对应关系记录在n实体中。
m:n联系:将对应关系抽象成一个实体,记录在实体中。
实体是一个关系模式,联系也是一个关系模式,多个实体之间的一个联系算一个关系模式。
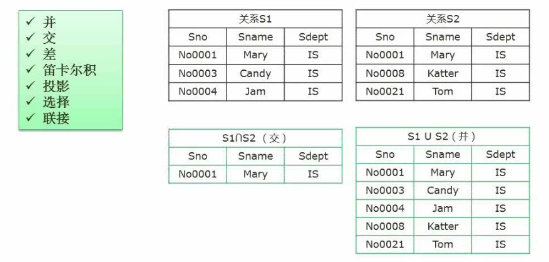
关系代数
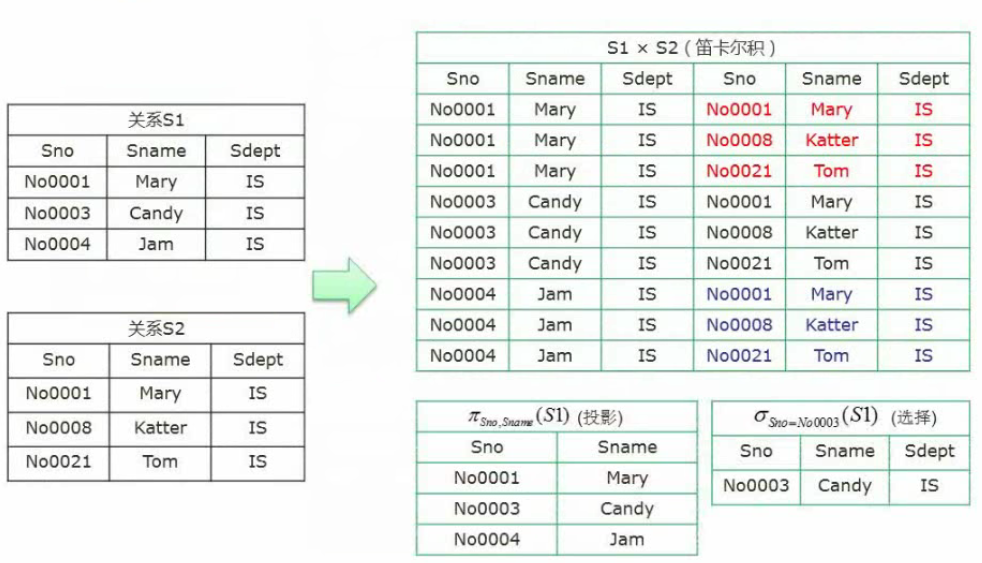
关系可以理解为表。
S1关系(Sno,Sname,Sdept),S2关系(Sno,Age)
并(∪):返回的为S1和S2全部。
交(∩):S1和S2重复的部分。
差(-):S1-S2代表S1中去掉S2的部分。
笛卡尔积(×):S1×S2用关系S1(表)中逐条记录和S2的全部做乘积。
投影(π):选择列的操作,πSno,Sname。
选择(σ):选择行的操作。
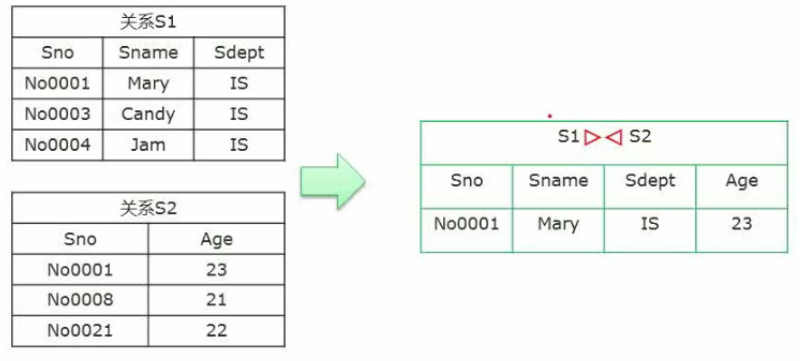
联接(▷◁):和笛卡尔积区别为用一个连接字段做等值连接,显示的连接的字段只保留一个。自然联接(S1和S2中相同的字段做联接)
规范化理论
函数依赖
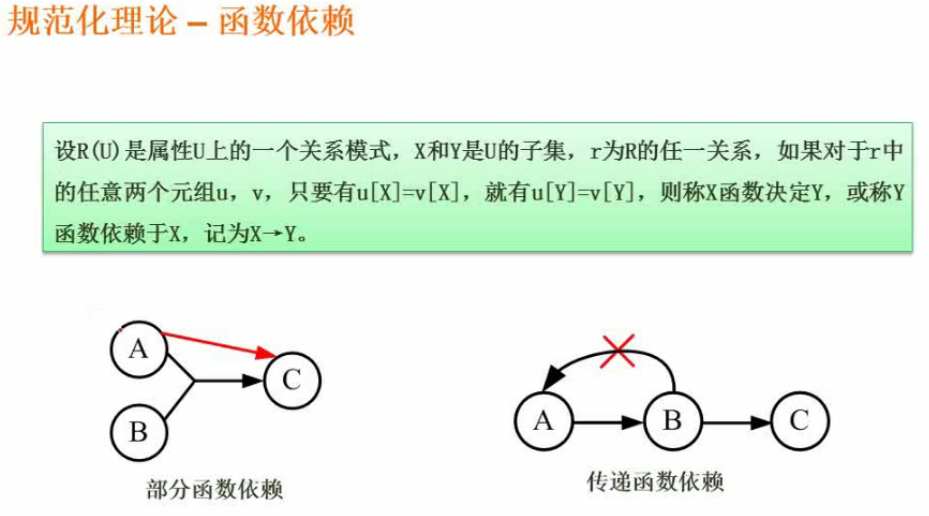
部分函数依赖:组合主键(A和B确定主键C,则C部分依赖A)。
传递函数依赖:B依赖于A,C依赖于B,则C依赖于A,A可以直接确定C。
价值与用途
规范化理论主要用于解决数据冗余、更新异常、插入异常、删除异常。

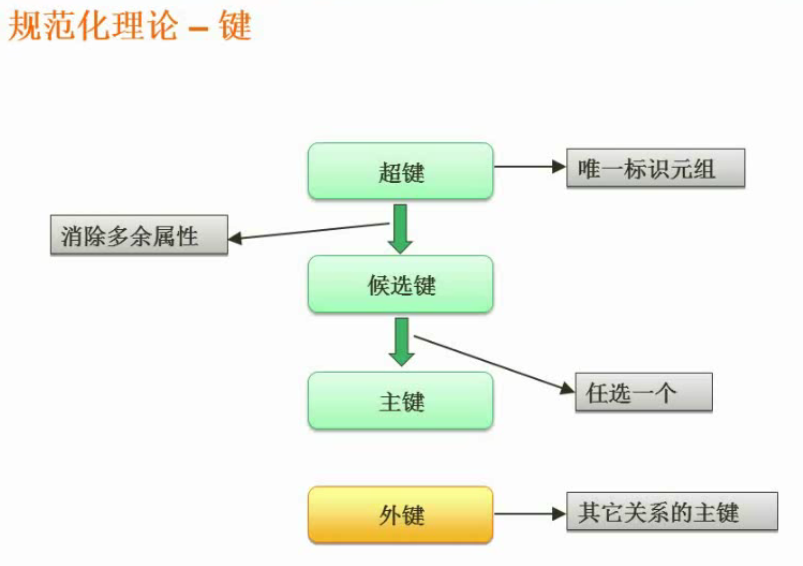
键
超键和侯选建相比,超键虽然能唯一标识元组,但是超键可以有冗余数据。
侯选建和主键的区别为,主键只有一个(学号和身份证号只能有一个作为主键)。
外键是和其他表主键关联的属性。
范式
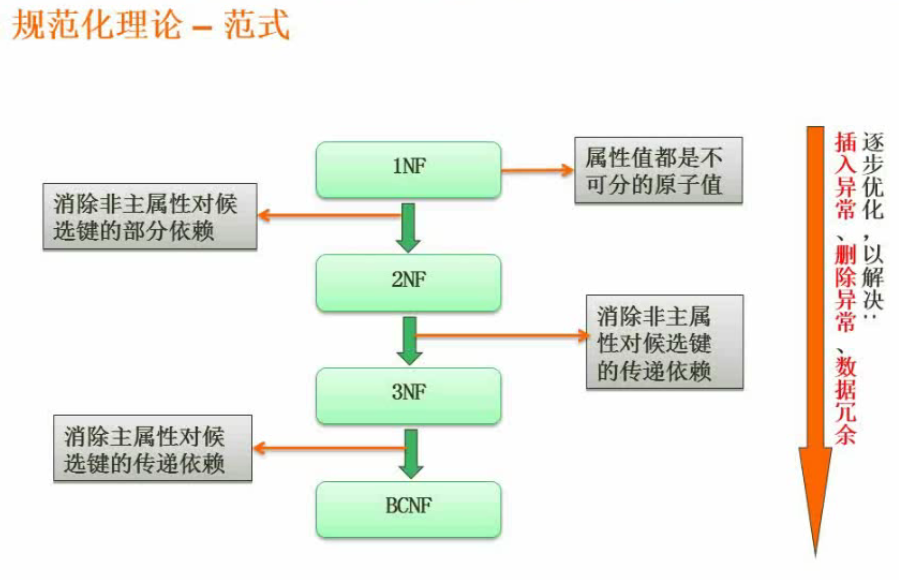
第一范式

第二范式
非主属性完全依赖于主键(不能存在部分依赖).
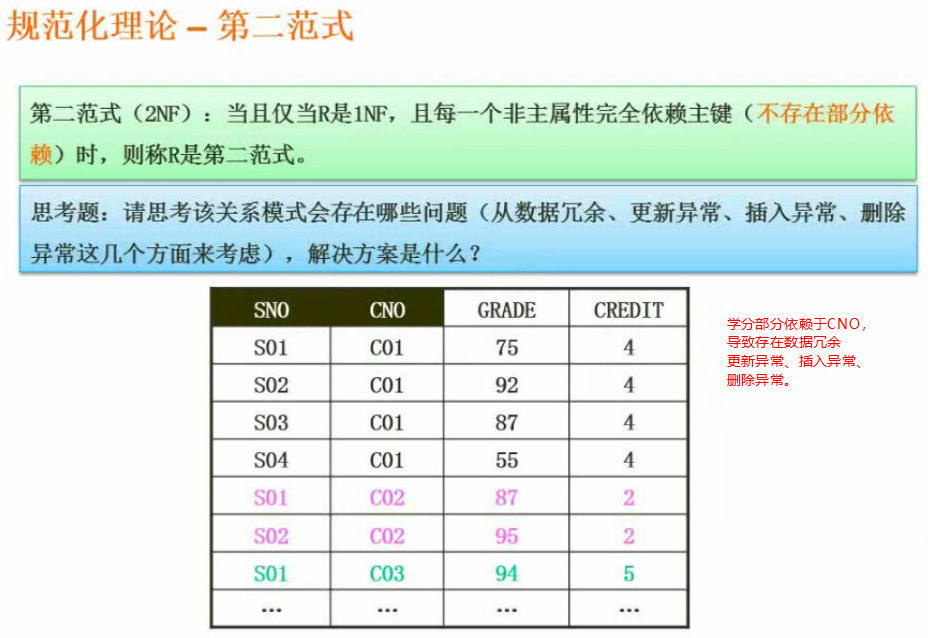
数据冗余:学分就是冗余信息
更新异常:跟新一部分学分另一部分没更新就是更新异常
插入异常:没有学生时,新建学科和学分插入不了就是插入异常
删除异常:删除学分时一并把学生删掉就是删除异常
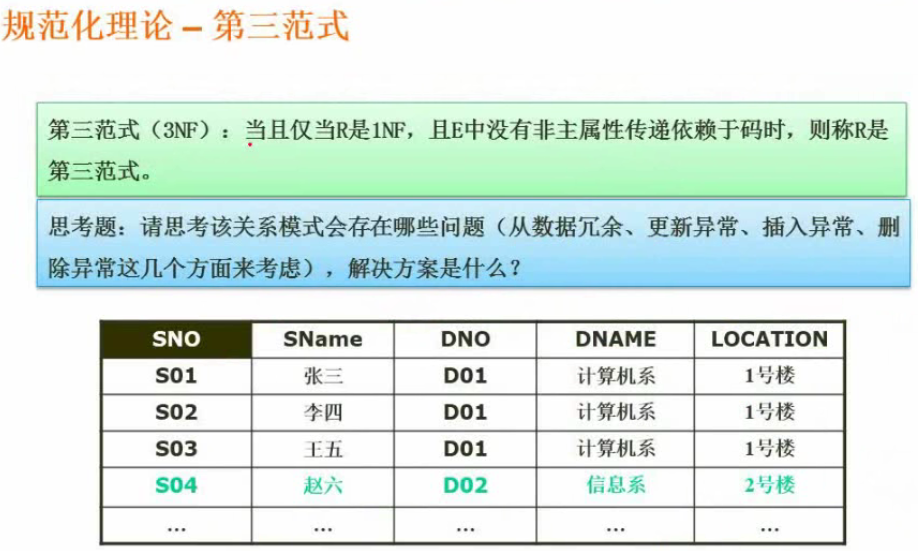
第三范式
非主属性不能传递依赖于主键.
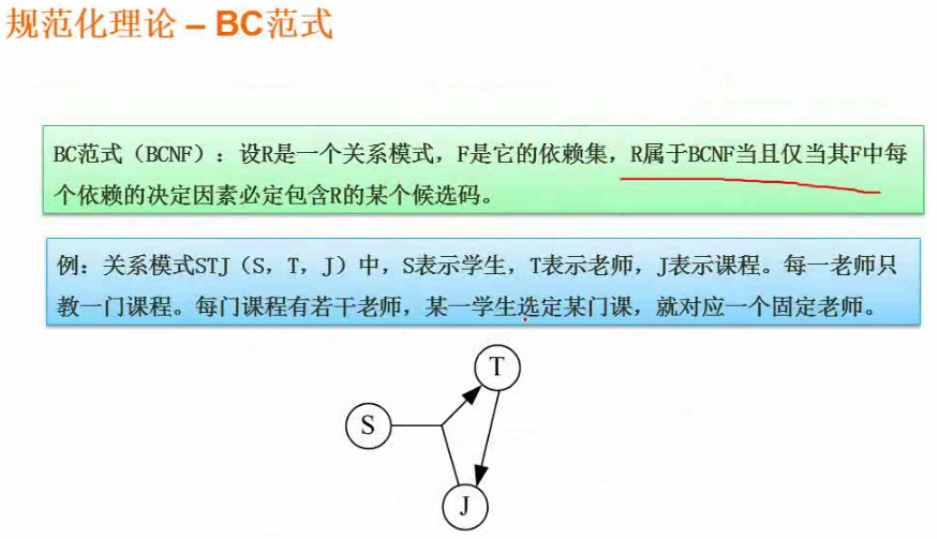
BCF范式
并发控制
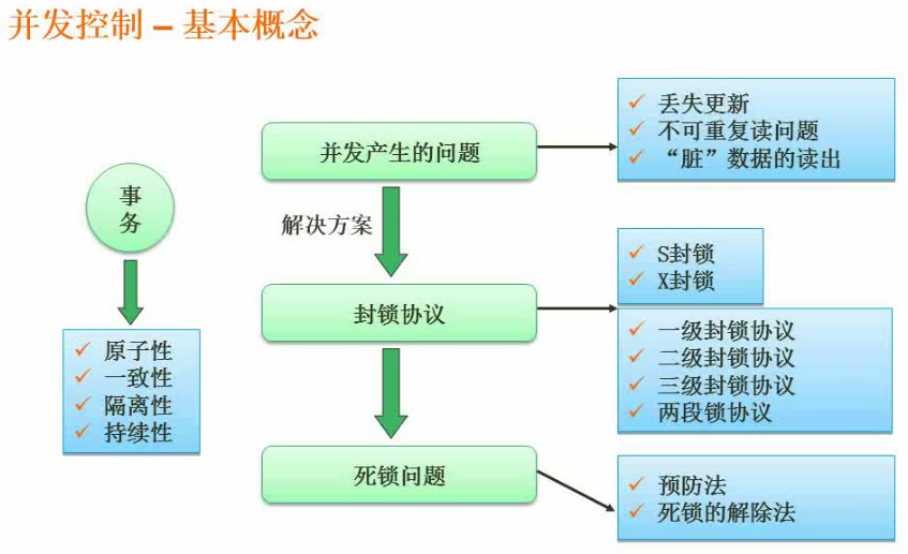
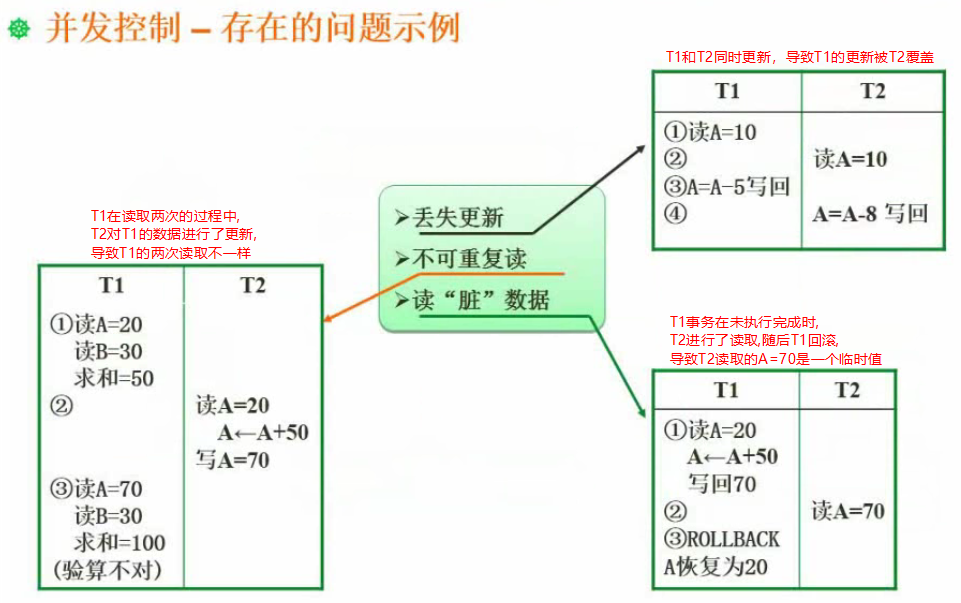
事务并发出现的问题
封锁协议等级

一级是基础,二级和三级封锁协议都是基于一级封锁协议。
一级封锁协议:修改加X锁;可防止丢失更新。(对应事务等级:Read Uncommitted)
二级封锁协议:修改加X锁基础上,读取加S锁(读完释放,不考虑事务下面是否会再读一次验证);可解决脏读。(对应事务等级:Read Committed)
三级封锁协议:修改加X锁基础上,读取加S锁(事务执行完释放,在事务的第二次读取验证之前,其他X锁的修改事务都不能进行);可解决脏读、不可重复度。(对应事务等级:Repeatable Read)
完整性约束
实体完整性约束:规定表的每一行在表中是惟一的实体。
域完整性:是指表中的列必须满足某种特定的数据类型约束,其中约束又包括取值范围、精度等规定。
参照完整性约束:是指两个表的主关键字和外关键字的数据应一致,保证了表之间的数据的一致性,防止了数据丢失或无意义的数据在数据库中扩散。
自定义完整性约束:针对某个特定关系数据库的约束条件,它反映某一具体应用必须满足的语义要求。
触发器:这个属于用户自己写的一个脚本,当触发某个事件时执行。
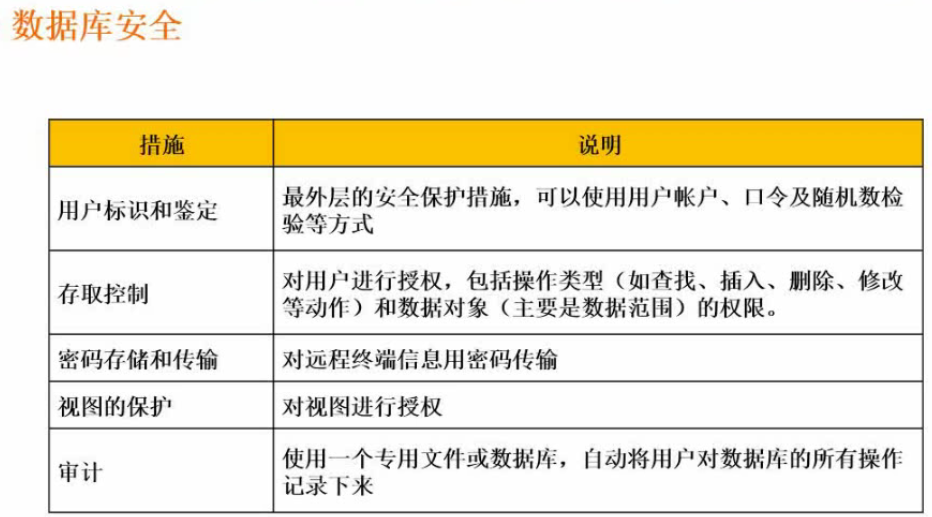
数据库安全
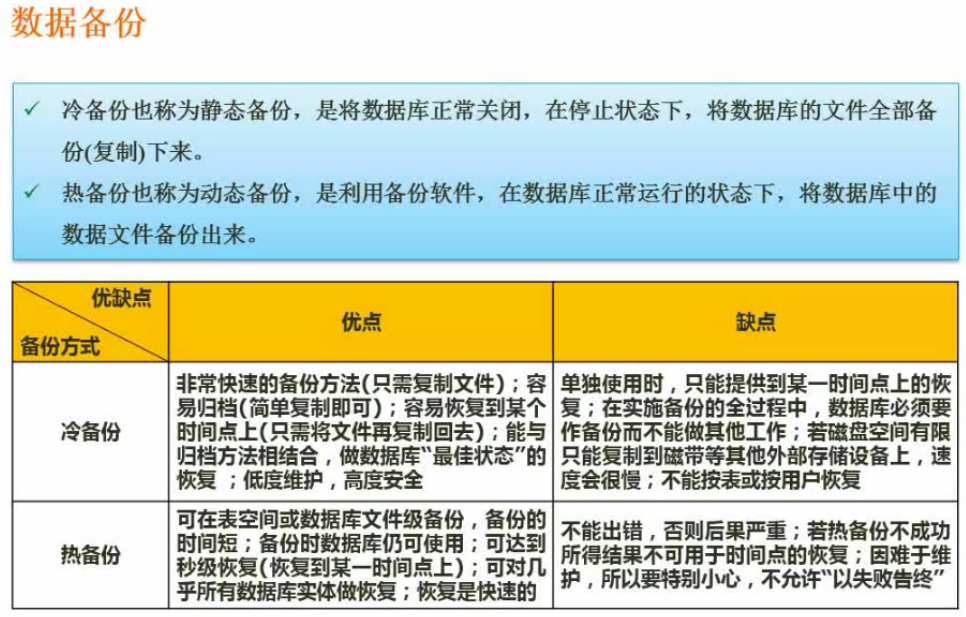
数据备份
备份分类
备份分为冷备份和热备份

故障与恢复
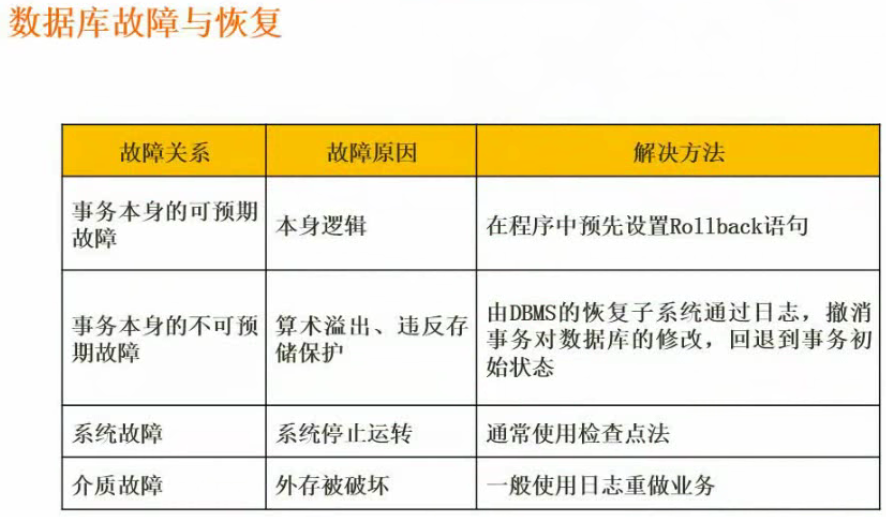
数据仓库与数据挖掘
数据仓库
把以往的数据抽出来存储到数据。
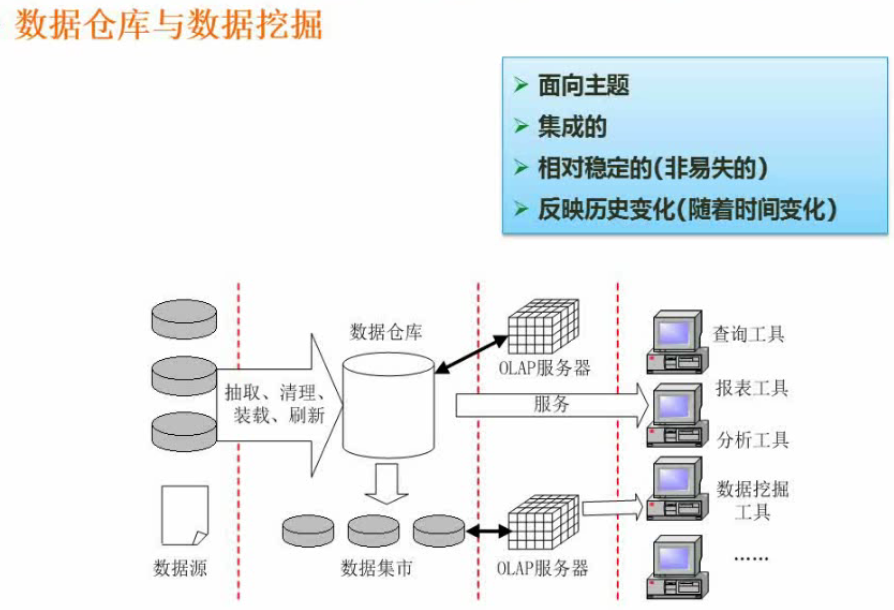
数据源:例如库存系统提取库存,销售系统提取销售数据
抽取:从各个系统抽取数据
清理:统一数据格式
装载:装入数据仓库
刷新:定期添加
数据仓库:数据直接装载到数据仓库
数据集市:数据仓库分部形成的多个数据集。
OLAP:联机分析处理服务器
前端工具:查询工具、报表工具、分析工具、数据挖掘工具
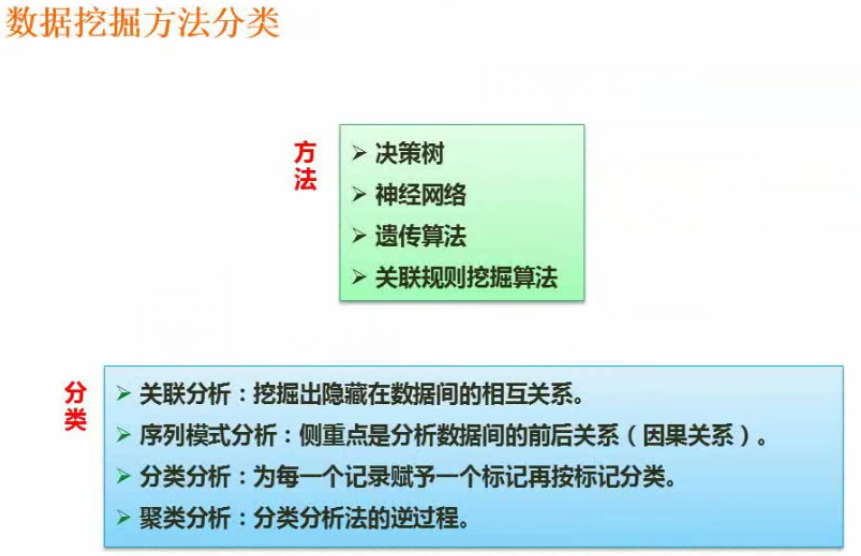
挖掘分类
反规范化
规范化技术提高了增删改的速度、减少了数据冗余,数据颗粒小,导致查询效率下降,反规范化就是为了解决查询效率提出的一些手段。

派生性冗余列:例如总额,用空间换时间
增加冗余列:为了减少关联查询,把常用的字段直接冗余在需要的表里。
重新组表:依据查询效率的原则重新组表。
分割表:垂直分割水平分割,就是分表分库,为了让查询速度快。
大数据
对海量数据进行处理的技术,数据具有数据量大、速度快、多样性、有价值的数据。
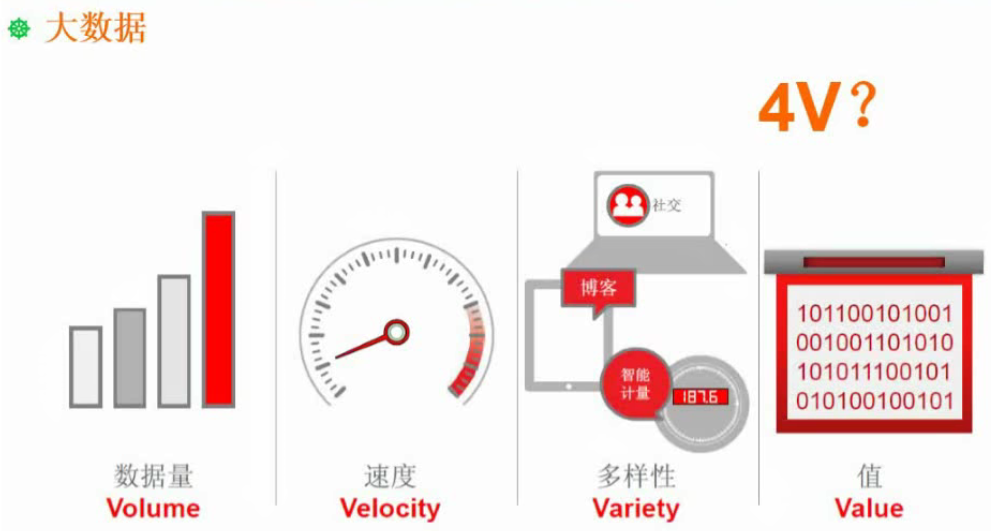

大数据4V特征
1、规模性(Volume)
数据量大,大数据中的数据计量单位是PB(1千个T)、EB(1百万个T)或ZB(10亿个T)。
2、多样性(Variety)
多样性主要体现在数据来源多、数据类型多和数据之间关联性强这三个方面。
①数据来源多,互联网和物联网的发展,带来了诸如社交网站、传感器等多种来源的数据。 而由于数据来源于不同的应用系统和不同的设备,决定了大数据形式的多样性。
②数据类型多,并且以非结构化数据为主。大数据中有70%-85%的数据是如图片、音频、视频、网络日志、链接信息等非结构化和半结构化的数据。
③数据之间关联性强,频繁交互,如游客在旅游途中上传的照片和日志,就与游客的位置、行程等信息有很强的关联性。
3、高速性(Velocity)
大数据对处理数据的响应速度有更严格的要求。实时分析而非批量分析,数据输入、处理与丢弃立刻见效,几乎无延迟。数据的增长速度和处理速度是大数据高速性的重要体现。
4、价值性(Value)
价值密度低,大数据中有价值的数据所占比例很小,而大数据真正的价值体现在从大量不相关的各种类型的数据中。挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,并运用于农业、金融、医疗等各个领域,以期创造更大的价值。
大数据分析典型:广告推送


 浙公网安备 33010602011771号
浙公网安备 33010602011771号