C#基础知识系列二(值类型和引用类型、可空类型、堆和栈、装箱和拆箱)
前言
之前对几个没什么理解,只是简单的用过可空类型,也是知道怎么用,至于为什么,还真不太清楚,通过整理本文章学到了很多知识,也许对于以后的各种代码优化都有好处。
本文的重点就是:值类型直接存储其值,引用类型存储对值的引用,值类型存在堆栈上,引用类型存储在托管堆上,值类型转为引用类型叫做装箱,引用类型转为值类型叫拆箱。
这一句话概括起来很简单,可是真正的理解起来却没那么简单,对于我来说吧。
值类型和引用类型
C#值类型数据直接在他自身分配到的内存中存储数据,而C#引用类型只是包含指向存储数据位置的指针。
C#值类型,我们可以把他归纳成三类:
第一类: 基础数据类型(string类型除外):包括整型、浮点型、十进制型、布尔型。
整型包括:sbyte、byte、char、short、ushort、int、uint、long、ulong 这九种类型;
浮点型就包括 float 和 double 两种类型;
十进制型就是 decimal ;
布尔型就是 bool 型了。
第二类:结构类型:就是 struct 型
第三类:枚举类型:就是 enum 型
C#引用类型有五种:class、interface、delegate、object、string、Array。
上面说的是怎么区分哪些C#值类型和C#引用类型,而使用上也是有区别的。所有值类型的数据都无法为null的,声明后必须赋以初值;引用类型才允许为null。
不过这里我们可以看一下可空类型
可空类型
可空类型可以表示基础类型的所有值,另外还可以表示 null 值。可空类型可通过下面两种方式中的一种声明:
System.Nullable<T> variable
T? variable
T 是可空类型的基础类型。T 可以是包括 struct 在内的任何值类型;但不能是引用类型。
1.值类型后加问号表示此类型为可空类型,如int? i = null;
int? d = null; System.Nullable<double> e = null;
2.可空类型与一元或二元运算符一起使用时,只要有一个操作数为null,结果都为null;

3.比较可空类型时,只要一个操作数为null,比较结果就为false。

值类型和引用类型在赋值(或者说复制)的时候也是有区别的。值类型数据在赋值的时候是直接复制值到新的对象中,而引用类型则只是复制对象的引用。
最后,值类型存在堆栈上,引用类型存储在托管堆上。接下来我们来看看堆和栈吧。
栈(Stack)和堆(Heap)
Stack是指堆栈,Heap是指托管堆,在C#中的叫法应该是这样的。
1、堆栈stack:堆栈中存储值类型。
堆栈实际上是自上向下填充的,即由高内存地址指向低内存地址填充。
堆栈的工作方式是先分配的内存变量后释放(先进后出原则)。堆栈中的变量是从下向上释放,这样就保证了堆栈中先进后出的规则不与变量的生命周期起冲突!
堆栈的性能非常高,但是对于所有的变量来说还不太灵活,而且变量的生命周期必须嵌套。
通常我们希望使用一种方法分配内存来存储数据,并且方法退出后很长一段时间内数据仍然可以使用。此时就要用到堆(托管堆)!
2、C#堆栈的工作方式
Windwos使用虚拟寻址系统,把程序可用的内存地址映射到硬件内存中的实际地址,其作用是32位处理器上的每个进程都可以使用4GB的内存-无论计算机上有多少硬盘空间(在64位处理器上,这个数字更大些)。这4GB内存包含了程序的所有部份-可执行代码,加载的DLL,所有的变量。这4GB内存称为虚拟内存。
4GB的每个存储单元都是从0开始往上排的。要访问内存某个空间存储的值。就需要提供该存储单元的数字。在高级语言中,编译器会把我们可以理解的名称转换为处理器可以理解的内存地址。
在进程的虚拟内存中,有一个区域称为堆栈,用来存储值类型。另外在调用一个方法时,将使用堆栈复制传递给方法的所有参数。
我们来看一下下面的小例子:
public void Test() { int a; ///do something { int b; ///do something } }
声明了a之后,在内部代码块中声明了b,然后内部代码块终止,b就出了作用域,然后a才出作用域。在释放变量的时候,其顺序总是与给它们分配内存的顺序相反,后进先出,这就是堆栈的工作方式。
堆栈是向下填充的,即从高地址向低地址填充。当数据入栈后,堆栈指针就会随之调整,指向下一个自由空间。我们来举个例子说明。
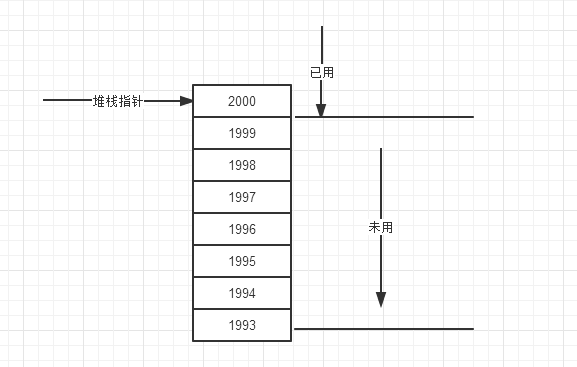
如图,假如堆栈指针2000,下一个自由空间是1999。下面的代码会告诉编译器需要一些存储单元来存储一个整数和一个双精度浮点数。
int c = 2; double d=3.5; ///do something
这两个都是值类型,自然是存储在堆栈中。声明c赋值2后,c进入作用域。int类型需要4个字节,c就存储在1996~1999上。此时,堆栈指针就减4,指向新的已用空间的末尾1996,下一个自由空间为1995。下一行声明d赋值3.5后,double需要占用8个字节,所以存储在1988~1995上,堆栈指针减去8。
当d出作用域时,计算机就知道这个变量已经不需要了。变量的生存期总是嵌套的,当d在作用域的时候,无论发生什么事情,都可以保证堆栈指针一直指向存储d的空间。删除这个d变量的时候堆栈指针递增8,现在指向d曾经使用过的空间,此处就是放置闭合花括号的地方。然后c也出作用域,堆栈指针再递增4。
此时如果放入新的变量,从1999开始的存储单元就会被覆盖了。
3、堆(托管堆)heap堆(托管堆)存储引用类型。
此堆非彼堆,.NET中的堆由垃圾收集器自动管理。
与堆栈不同,堆是从下往上分配,所以自由的空间都在已用空间的上面。
4、托管堆的工作方式
堆栈有很高的性能,但要求变量的生命周期必须嵌套(后进先出)。通常我们希望使用一个方法来分配内存,来存储一些数据,并在方法退出后很长的一段时间内数据仍是可用的。用new运算符来请求空间,就存在这种可能性-例如所有引用类型。这时候就要用到托管堆了。
托管堆是进程可用4GB的另一个区域,我们用一个例子了解托管堆的工作原理和为引用数据类型分配内存。假设我们有一个Cat类。
public class Cat { public string Name { get; set; } }
来看下面这个最简单的方法,当然着两行代码,在第一节中也有提到过http://www.cnblogs.com/aehyok/p/3499822.html。
1 public void Test() 2 { 3 Cat cat; 4 cat = new Cat(); 5 }
第三行代码声明了一个Cat的引用cat,在堆栈上给这个引用分配存储空间,但这只是一个引用,而不是实际的Cat对象。cat引用包含了存储Cat对象的地址-需要4个字节把0~4GB之间的地址存储为一个整数-因此cat引用占4个字节。
第四行代码首先分配托管堆上的内存,用来存储Cat实例,然后把变量cat的值设置为分配给Cat对象的内存地址。
Cat是一个引用类型,因此是放在内存的托管堆中。为了方便讨论,假设Cat对象占用32字节,包括它的实例字段和.NET用于识别和管理其类实例的一些信息。为了在托管堆中找到一个存储新Cat对象的存储位置,.NET运行库会在堆中搜索一块连续的未使用的32字节的空间,假定其起始地址是1000。而在堆栈中的内存地址的四个字节为:1996到1999。在实例化cat之前应该是这样的。
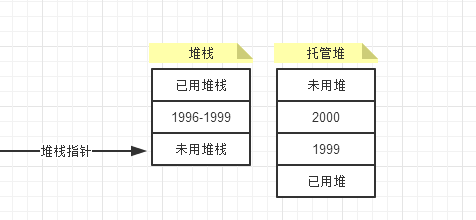
cat实例化,给Cat对象分配空间之后,内存变化为 cat在堆栈中使用1996到1999的内存地址,然后对Cat对象分配空间之后。
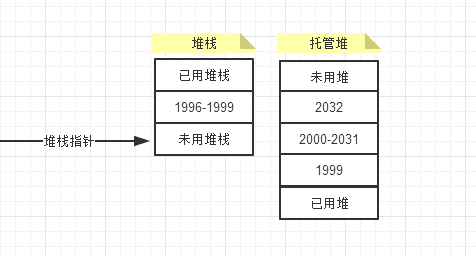
这里与堆栈不同,堆上的内存是向上分配的,所有自由空间都在已用空间的上面。
以上例子可以看出,建议引用变量的过程比建立值变量的过程复杂的多,且不能避免性能的降低-.NET运行库需要保持堆的信息状态,在堆添加新数据时,这些信息也需要更新(这个会在堆的垃圾收集机制中提到)。尽管有这么些性能损失,但还有一种机制,在给变量分配内存的时候,不会受到堆栈的限制:
把一个引用变量e的值赋给另一个相同类型的变量f,这两个引用变量就都引用同一个对象了。当变量f出作用域的时候,它会被堆栈删除,但它所引用的对象依然保留在堆上,因为还有一个变量e在引用这个对象。只有该对象的数据不再被任何变量引用时,它才会被删除。
5、托管堆的垃圾收集
对象不再被引用时,会删除堆中已经不再被引用的对象。如果仅仅是这样,久而久之,堆上的自由空间就会分散开来,给新对象分配内存就会很难处理,.NET运行库必须搜索整个堆才能找到一块足够大的内存块来存储整个新对象。
但托管堆的垃圾收集器运行时,只要它释放了能释放的对象,就会压缩其他对象,把他们都推向堆的顶部,形成一个连续的块。在移动对象的时候,需要更新所有对象引用的地址,会有性能损失。但使用托管堆,就只需要读取堆指针的值,而不用搜索整个链接地址列表,来查找一个地方放置新数据。
因此在.NET下实例化对象要快得多,因为对象都被压缩到堆的相同内存区域,访问对象时交换的页面较少。Microsoft相信,尽管垃圾收集器需要做一些工作,修改它移动的所有对象引用,导致性能降低,但这样性能会得到弥补。
装箱和拆箱
1、装箱是将值类型转换为引用类型 ;拆箱是将引用类型转换为值类型。
利用装箱和拆箱功能,可通过允许值类型的任何值与Object 类型的值相互转换,将值类型与引用类型链接起来。
例如,如下的代码:
static void Main(string[] args) { int val = 100; object obj = val; Console.WriteLine ("对象的值 = {0}", obj); Console.ReadLine(); }
这其实就是一个简单装箱的过程,是将值类型转换为引用类型的过程。
static void Main(string[] args) { int val = 100; object obj = val; int num = (int)obj; Console.WriteLine("num = {0}", num); Console.ReadLine(); }
接着前面装箱的例子,那么int num=(int)obj; 这个过程就是拆箱的过程。
注意:被装过箱的对象才能被拆箱
2、为何需要装箱?(为何要将值类型转为引用类型?)
一种最普通的场景是,调用一个含类型为Object的参数的方法,该Object可支持任意为型,以便通用。当你需要将一个值类型(如Int32)传入时,需要装箱。
另一种用法是,一个非泛型的容器,同样是为了保证通用,而将元素类型定义为Object。于是,要将值类型数据加入容器时,需要装箱。
3、装箱/拆箱的内部操作。
装箱:
对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。按三步进行。
第一步:新分配托管堆内存(大小为值类型实例大小加上一个方法表指针和一个同步块索引SyncBlockIndex)。
第二步:将值类型的实例字段拷贝到新分配的内存中。
第三步:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。
拆箱:
拆箱过程与装箱过程正好相反。看一段代码:
long a = 999999999; object b = a; int c = (int)b;
拆箱必须非常小心,确保该值变量有足够的空间存储拆箱后得到的值。C#int只有32位,如果把64位的long值拆箱为int时,会产生一个InvalidCastExecption异常。
显然,从原理上可以看出,装箱时,生成的是全新的引用对象,这会有时间损耗,也就是造成效率降低。装箱操作和拆箱操作是要额外耗费cpu和内存资源的,所以在c# 2.0之后引入了泛型来减少装箱操作和拆箱操作消耗。
4、非泛型的装箱和拆箱以及泛型
使用非泛型集合时引发的装箱和拆箱操作
var array = new ArrayList(); array.Add(1); array.Add(2); foreach (int value in array) { Console.WriteLine("value is {0}",value); }
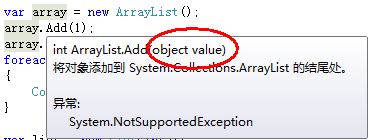

代码声明了一个ArrayList对象,向ArrayList中添加两个数字1,2;然后使用foreach将ArrayList中的元素打印到控制台。
在这个过程中会发生两次装箱操作和两次拆箱操作,在向ArrayList中添加int类型元素时会发生装箱,在使用foreach枚举ArrayList中的int类型元素时会发生拆箱操作,将object类型转换成int类型,在执行到Console.WriteLine时,还会执行两次的装箱操作;这一段代码执行了6次的装箱和拆箱操作;如果ArrayList的元素个数很多,执行装箱拆箱的操作会更多。
使用泛型集合
var list = new List<int>(); list.Add(1); list.Add(2); foreach (int value in list) { Console.WriteLine("value is {0}", value); }
代码和1中的代码的差别在于集合的类型使用了泛型的List,而非ArrayList.上述代码只会在Console.WriteLine()方法时执行2次装箱操作,不需要拆箱操作。
可以看出泛型可以避免装箱拆箱带来的不必要的性能消耗;当然泛型的好处不止于此,泛型还可以增加程序的可读性,使程序更容易被复用等等,至于泛型以后再做详细介绍。
总结
赶脚自己还是学了不少东西的,没事的时候多拿出来看看,说不定还会有意想不到的收获呢,继续加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号