归一化和标准化-机器学习
归一化与标准化
归一化和标准化本质上都是一种线性变换。线性变换保持线性组合与线性关系式不变,这保证了特定模型不会失效。
归一化 Normalization
归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。
常见的映射范围有 [0, 1] 和 [-1, 1] ,最常见的归一化方法就是 Min-Max 归一化:
举个例子,判断一个人的身体状况是否健康,那么我们会采集人体的很多指标,比如说:身高、体重、红细胞数量、白细胞数量等。
一个人身高 180cm,体重 70kg,白细胞计数
衡量两个人的状况时,白细胞计数就会起到主导作用从而遮盖住其他的特征,归一化后就不会有这样的问题。
标准化 Normalization
英文翻译的问题:
归一化和标准化的英文是一致的,但是根据其用途(或公式)的不同去理解(或翻译)
最常见的标准化方法: Z-Score 标准化
标准化的输出范围不受限制,对异常值有更好的处理
其中 是样本数据的均值(mean),
是样本数据的标准差(std)。
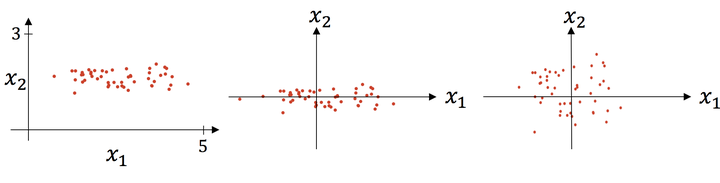
上图则是一个散点序列的标准化过程:原图->减去均值->除以标准差
归一化和标准化的区别:
归一化和标准化的本质都是缩放和平移,他们的区别直观的说就是归一化的缩放是 “拍扁” 统一到区间(0-1),而标准化的缩放是更加 “弹性” 和 “动态” 的,和整体样本的分布有很大的关系。
常见的归一化方法:
常见的标准化方法:
从输出范围角度来看, 归一化的输出结果必须在 0-1 间。而标准化的输出范围不受限制,通常情况下比归一化更广
标准化与归一化的应用场景:
-
一般情况下,如果对输出结果范围有要求,用归一化
-
如果数据较为稳定,不存在极端的最大最小值,用归一化
-
如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
-
在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的,原因就在于二者的区别:
- 标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去,对异常值和极端值处理的并不好
- 标准化更符合统计学假。对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是将这个正态分布调整为均值为0,方差为1的标准正态分布而已

 浙公网安备 33010602011771号
浙公网安备 33010602011771号