pytnon jieba中文分词 例子
任务
1.中文文章分词
2.提取频率最高的词(过滤无意义的词)
效果展示2
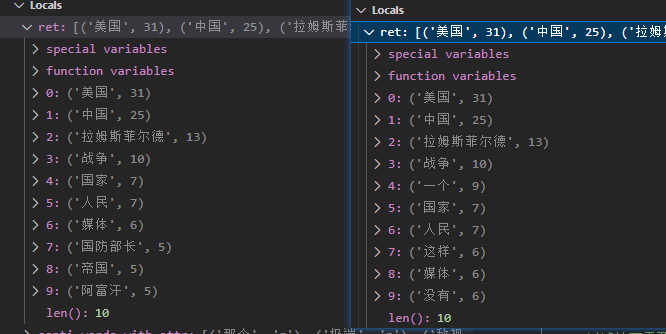
效果展示1
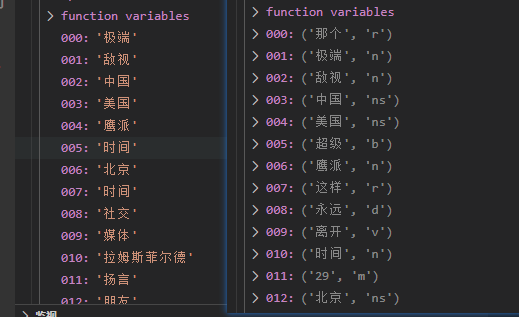
代码
点击查看代码
import jieba.posseg as psg
from collections import Counter
def text_topn():
text=open(r"C:\Users\xin\Videos\buffer\aa.txt",encoding='utf-8').read()
# 分词列表 附词性分析
santi_words_with_attr = [(x.word,x.flag) for x in psg.cut(text) if len(x.word) >= 2]
# 黑名单
stop_attr = ['a','ad','b','c','d','f','df','m','mq','p','r','rr','s','t','u','v','z']
# 过滤掉不需要的词性的词
words = [x[0] for x in santi_words_with_attr if x[1] not in stop_attr]
# 频率最高的词
ret=Counter(words).most_common(10)
return ret

 浙公网安备 33010602011771号
浙公网安备 33010602011771号