
1. 返回列表中出现最多的数字, 如果出现的次数一样多,返回数值大的那个
def highest_rank(arr): a = max([arr.count(i) for i in arr]) b = set() for i in arr: if arr.count(i) == a: b.add(i) return max(b) print(highest_rank([12, 10, 8, 12, 7, 6, 4, 10, 12,11,11,11])) #12
def highest_rank(arr): return sorted(arr,key=lambda x: (arr.count(x),x))[-1] # sorted(iterable, cmp=None, key=None, reverse=False) # iterable 可迭代对象 #cmp:比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。 #key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 #reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认) # 此题中 key = lambda x: (arr.count(x),x) 即排序不仅升序排,还按照出现的次数排
2. 找出两句话中不同的部分, 要求字母为小写 小于等于1个的不考虑,排序 1. 长度,2. 开头数字,3.字母表
即
mix(" In many languages", " there's a pair of functions") #"1:aaa/1:nnn/1:gg/2:ee/2:ff/2:ii/2:oo/2:rr/2:ss/2:tt")
自己写的
def lowa(s): l = [] for i in s: if ord(i) > 96 and ord(i) != 32: l.append(i) return sorted(l,key=lambda x: (l.count(x),x),reverse=True) def mix(s1, s2): l1 = lowa(s1) l2 = lowa(s2) l = [] while l1 != []: a = l1[0] if l1.count(a) >1 or l2.count(a)>1: if l1.count(a)> l2.count(a): l.append('1:'+ (a* l1.count(a))) elif l1.count(a) == l2.count(a): l.append('=:'+(a* l1.count(a))) else: l.append('2:'+(a * l2.count(a))) l1 = [x for x in l1 if x != a] l2 = [y for y in l2 if y != a] else: l1 = [x for x in l1 if x != a] l2 = [y for y in l2 if y != a] while l2 != []: if l2.count(l2[0])>1: l.append('2:' + (l2[0] * l2.count(l2[0]))) l2 = [y for y in l2 if y != l2[0]] else: l2 = [y for y in l2 if y != l2[0]] w = sorted(l,key= lambda x:(-len(x),ord(x[0]),ord(x[-1])),) d = '/'.join(w) return d
别人写的
from collections import Counter def mix(s1, s2): c1 = Counter(filter(str.islower, s1)) # 注意filter 和Counter :Counter 生成字典 {'e',5} 指 e 有5个 c2 = Counter(filter(str.islower, s2)) res = [] s= set(c1.keys() | c2.keys()) for c in s: n1, n2 = c1.get(c, 0), c2.get(c, 0) # 如果有c 返回c1当中相应的key 值,如果没有返回0 if n1 > 1 or n2 > 1: res.append(('1', c, n1) if n1 > n2 else ('2', c, n2) if n2 > n1 else ('=', c, n1)) res = ['{}:{}'.format(i, c * n) for i, c, n in res] # !!!!生成格式 return '/'.join(sorted(res, key=lambda s: (-len(s), s)))
3. 不断的循环倒着乘上 1,10,9,12,3,4 直到结果不变
比如1234567 :7×1 + 6×10 + 5×9 + 4×12 + 3×3 + 2×4 + 1×1 = 178
178:8x1 + 7x10 + 1x9 = 87
87:7x1 + 8x10 = 87
my
def thirt(n): y2 = n y1 = y3 =0 z = [1,10,9,12,3,4] a = [int(i) for i in str(n)] w = 0 while y2 != y3: y2 = y3 w = 0 for i in a[::-1]: y1 += i * z[w] if w < 5: w += 1 else: w = 0 a = [int(i) for i in str(y1)] y3 = y1 y1 = 0 else: return y2
def thirt(n): total = sum([int(c) * array[i % 6] for i, c in enumerate(reversed(str(n)))]) # 将数字变成字符再反转 用enumerate 给每数字进行编号 ,编号除以6取余来作为array的切片 if n == total: return total return thirt(total) # !!!!可以用函数进行循环
def thirt(n): seq = [1, 10, 9, 12, 3, 4] s = str(n) t = sum(seq[i%6] * int(s[-i-1]) for i in range(len(s))) return t if t == n else thirt(t)
4. 返回域名的主要部分
比如http://google.com =》 google
看答案的
def domain_name(url): return url.split('//')[-1].split('www.')[-1].split('.')[0]
5. 打字应该按多少次
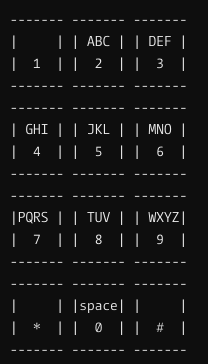 比如LOL 按 9 次
比如LOL 按 9 次
我写的:
def presses(phrase): a = [i for i in 'abcdefghijklmnopqrstuvwxyz 1234567890*#'] b = [1,2,3,1,2,3,1,2,3,1,2,3,1,2,3,1,2,3,4,1,2,3,1,2,3,4,1,1,4,4,4,4,4,5,4,5,2,1,1] c = 0 for i in phrase: c += b[a.index(i.lower())] return c
def presses(phrase): return sum(1 + button.find(c) for c in phrase.lower() for button in BUTTONS if c in button)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号