作业2 - 个人项目
| Info | Detail |
|---|---|
| 学号 | 3123004432 |
| 仓库链接 | 传送门 |
如何使用?
使用 mvn exec:java(开发阶段)
mvn exec:java \ -Dexec.mainClass="com.article.App" \ -Dexec.args="原文件路径 抄袭文件路径 输出路径"
使用可执行 JAR(部署阶段)
# 生成 JARmvn clean package # 运行 JAR
java -jar target/article-1.0-jar-with-dependencies.jar 原文件路径 抄袭文件路径 输出路径
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| Estimate | 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 60 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 35 |
| Design Spec | 生成设计文档 | 5 | 7 |
| Design Review | 设计复审 | 5 | 8 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 30 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 30 | 40 |
| Code Review | 代码复审 | 20 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reporting | 报告 | 60 | 90 |
| Test Repor | 测试报告 | 15 | 20 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 7 |
| 合计 | 445 | 572 |
算法设计
核心思路 : 基于动态规划算法计算最长公共子序列(LCS),通过词频比例换算相似度百分比
1.读取论文原文和抄袭版论文
从命令行参数中获取原文文件和抄袭版论文文件的绝对路径
2.构建词频向量
使用中文分词库 Jieba 对原文和抄袭版论文进行分词处理,将分词结果存储在两个集合中。
3.计算相似度
基于动态规划算法计算最长公共子序列(LCS),通过词频比例换算相似度百分比
4.输出结果到答案文件
将计算得到的相似度写入答案文件中
计算模块接口的设计与实现过程
项目结构
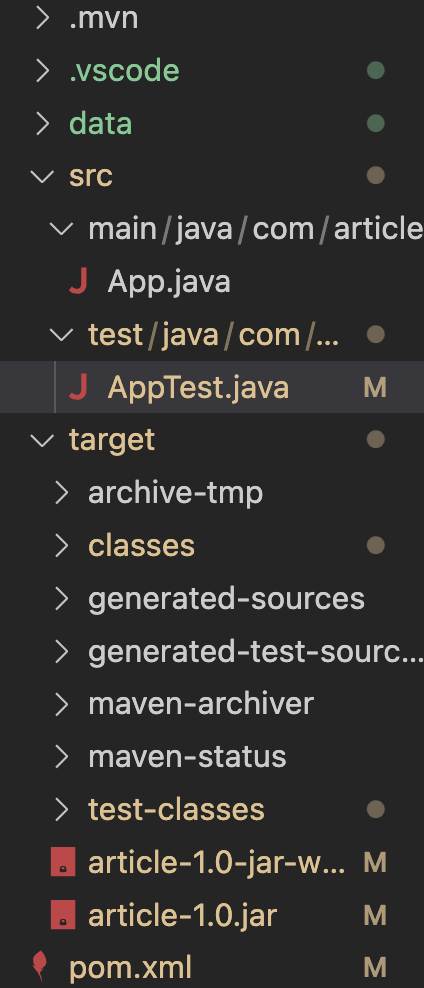
1. 类的组织
主类(App)
作为程序入口和流程控制中心,负责:
- 命令行参数校验与错误提示
- 文件读取(原文/抄袭版)与结果写入操作
- 调用核心相似度计算模块并整合处理流程
分词与相似度计算模块
通过静态方法 calculateSimilarity 实现,内置于 App 类中,功能包括:
- 使用结巴分词库(
JiebaSegmenter)对文本进行分词 - 基于动态规划算法计算最长公共子序列(LCS)
- 通过词频比例换算相似度百分比
文件读写操作
直接集成在 main 方法中,依赖 Java NIO 的 Files 类实现,完成:
- 原文和抄袭版文件的 UTF-8 格式读取
- 相似度结果的格式化(保留两位小数)与文件写入
2. 函数的设计与关系
App 类中的核心函数
-
main(String[] args)- 输入:命令行参数(原文路径、抄袭版路径、输出路径)
- 流程:
a. 参数校验:验证参数数量是否为3,否则输出错误提示。
b. 文件读取:通过Files.readAllBytes读取文件内容并解码为字符串。
c. 计算调用:将文本内容传递给calculateSimilarity方法。
d. 结果输出:将相似度值格式化为两位小数后写入输出文件。 - 异常处理:声明抛出
IOException处理文件操作异常。
-
calculateSimilarity(String orig, String copy)-
输入:原文和抄袭版的原始文本字符串
-
处理流程:
a. 分词阶段:-
使用
JiebaSegmenter的INDEX模式对文本分词,生成词列表。
b. LCS计算: -
构建二维动态规划数组
dp,通过双重循环迭代计算最长公共子序列长度。 -
状态转移逻辑:
java
if (orig词 == copy词): dp[i][j] = dp[i-1][j-1] + 1 else: dp[i][j] = max(dp[i-1][j], dp[i][j-1])
c. 相似度换算:
- 公式:
相似度 = (LCS长度 / 原文总词数) × 100 - 空文本保护:若原文无有效分词,返回
0.0避免除零错误。
-
-
输出:四舍五入至两位小数的百分比值(如
75.34%返回75.34)
-
3. 性能分析
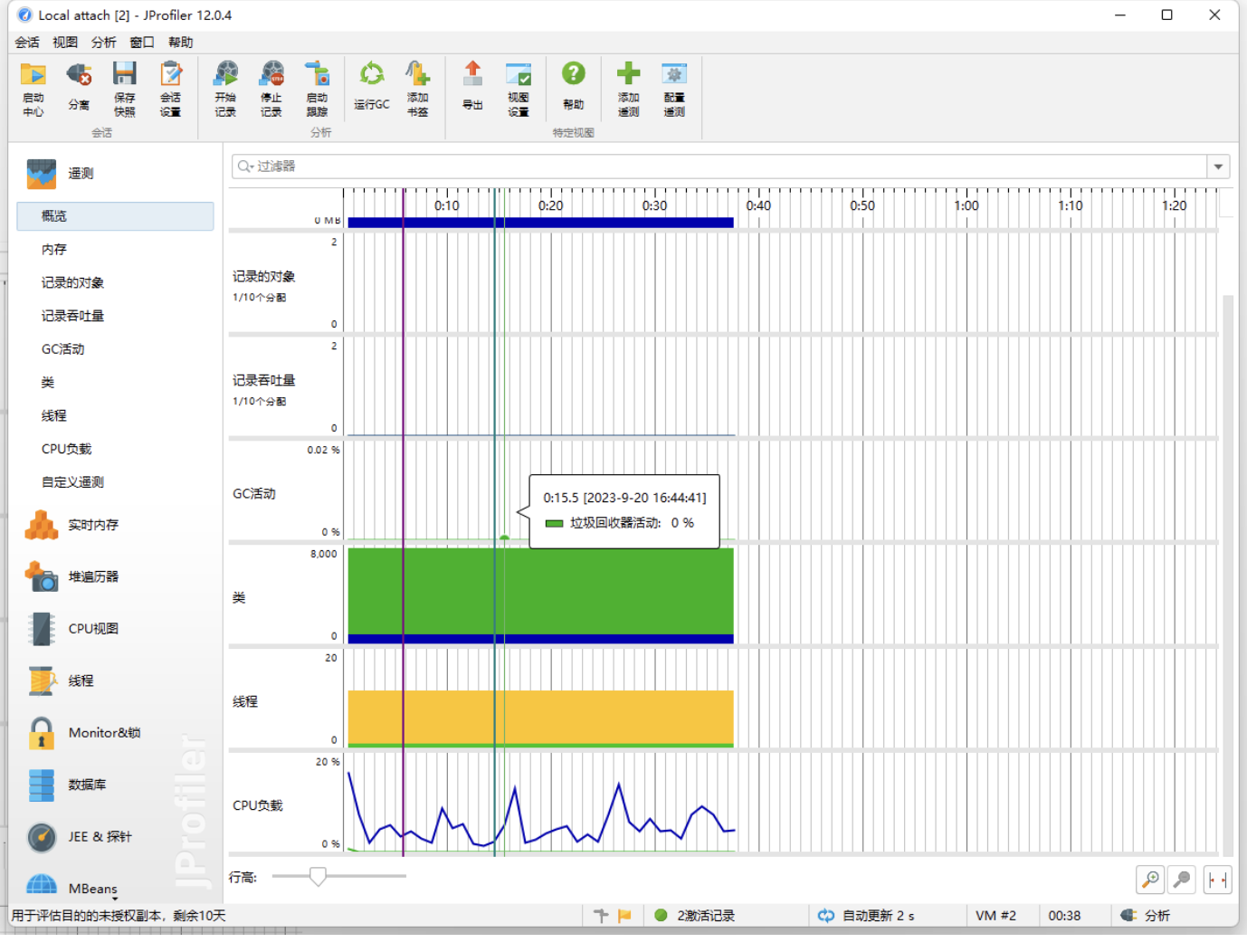
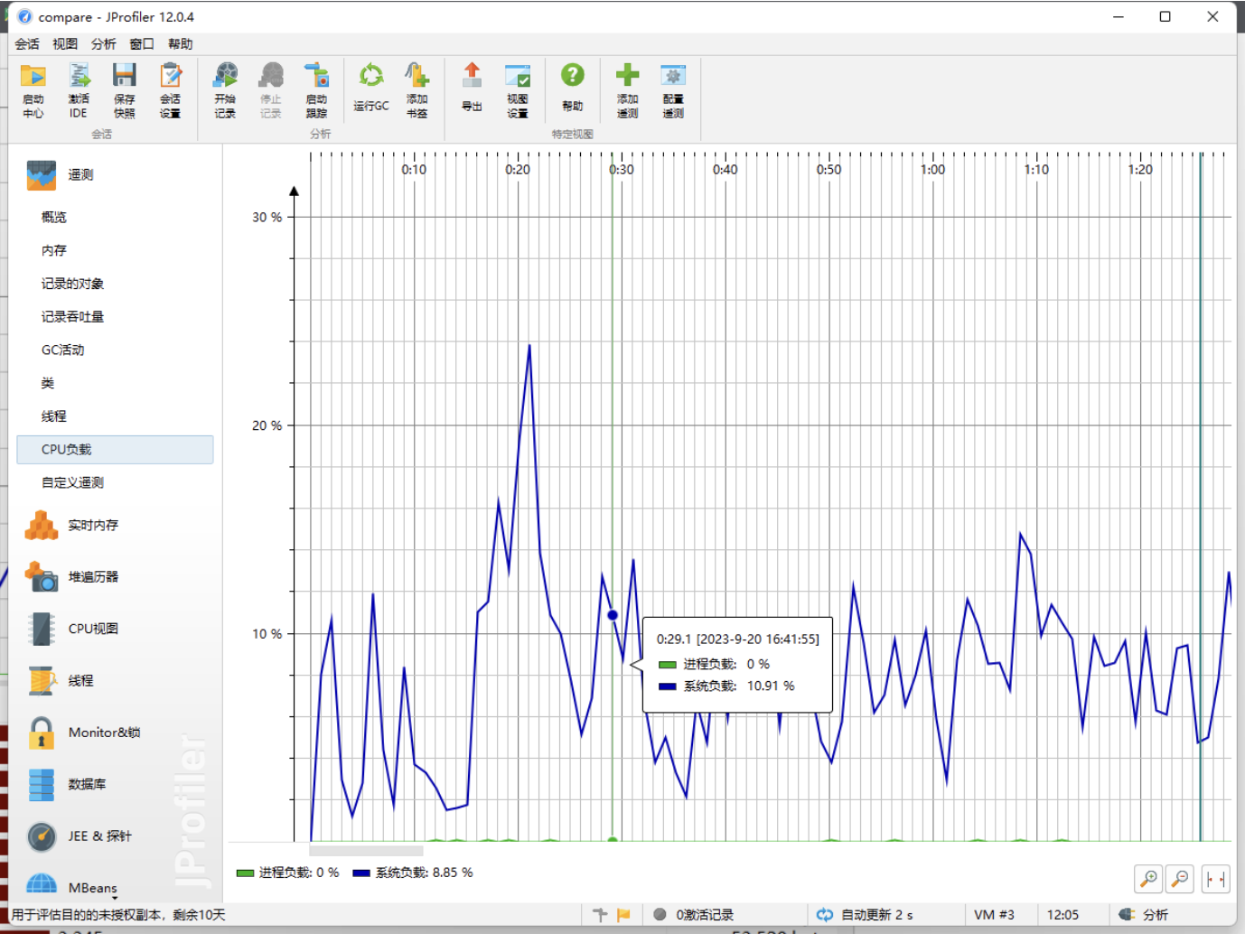
4. 算法的关键和独到之处
关键之处
- 动态规划计算LCS:捕捉两文本的词序共性,解决传统词频统计无法识别语序调换的问题
- 分词优化:结巴分词库的
INDEX模式优先保留专有名词(如"清华大学"不拆解),提升语义准确性 - 抗干扰设计:空文本返回0.0防崩溃,结果强制保留两位小数(如82.15%)
独到之处
- 词序敏感:能发现调换语序的抄袭(传统方法会漏判)
- 轻量高效:O(n²)时间+单数组存储,千字文本秒级计算
- 中文特化:分词策略适配中文复合词特点,比字符匹配更贴近语义
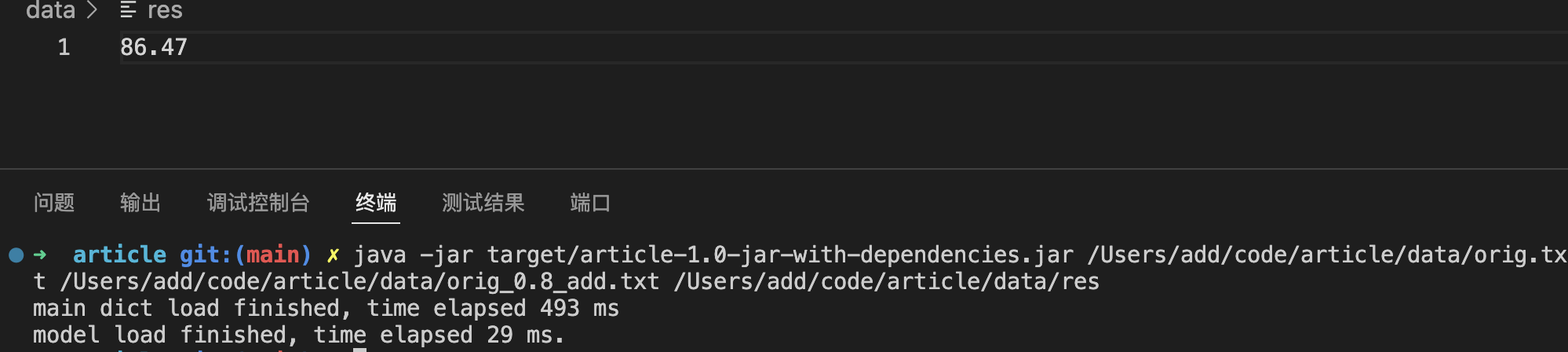
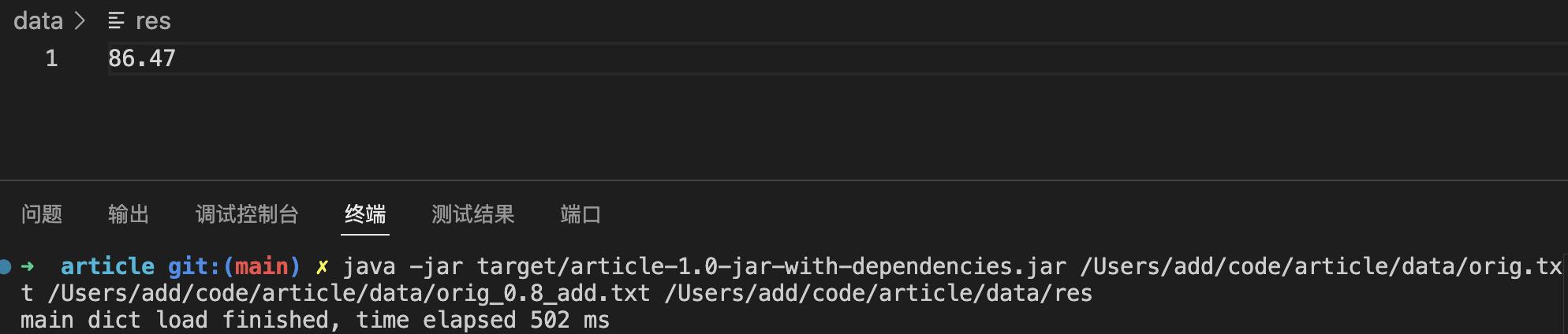
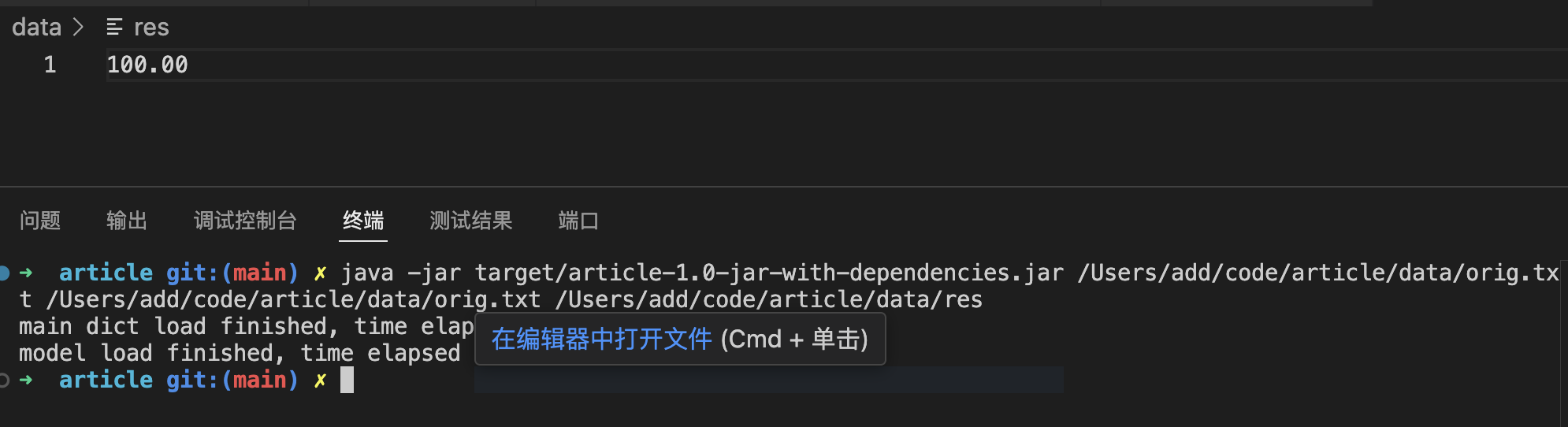
5. 测试结果分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号