
路飞学城-python集训营学习-第二章
1.字符编码
unicode编码:国际标准字符集,规定所以的字符和符号最少由16位来表示(两个字节)
UTF-8:是对unicode编码的压缩和优化,将所以的字符和符号进行分类,ascii码中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字符保存...
windows 系统中文版默认编码是GBK
Mac OS\Linux 系统默认编码是UTF-8
2.数据类型--列表
列表是一个数据集合,集合内可以放任何数据类型,可对集合进行增删改查
L1=[] L2=['a','b','c','d']
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表
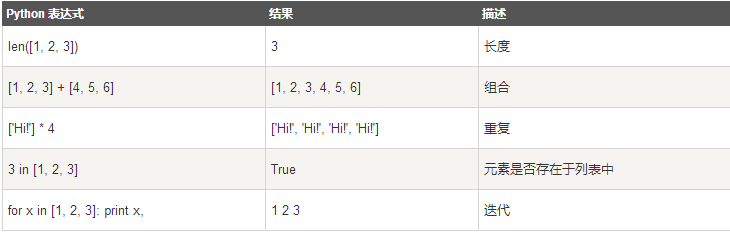
查询
>>>l3=['a','b','c','d'] >>>l3[2] #通过索引取值 'c' >>>l3[-1] #通过索引从列表右边开始取值 'd' >>>l3.index('a') #返回指定元素的索引值,找到第一个匹配值 0 >>>l3.count('a') #统计指定元素的个数 1
切片
>>> l3=['a','b','c','d'] >>> l3=['a','b','c','d','e','1','2'] >>> l3[0:3] #返回从索引0到3的元素,不包括3,顾头不顾尾 ['a', 'b', 'c'] >>> l3[0:-1] #返回从索引0到最后一个值,不包括最后一个值 ['a', 'b', 'c', 'd', 'e', '1'] >>> l3[3:6] #返回从索引3到6的元素 ['d', 'e', '1'] >>> l3[3:] #返回从索引3到最后的值 ['d', 'e', '1', '2'] >>> l3[1:6:2] #返回索引1到6的值,每隔一个元素取一个值 ['b', 'd', '1']
增加修改
>>> l3.append('A') #列表最后面追加A >>> l3 ['a', 'b', 'c', 'd', 'e', '1', '2', 'A'] >>> l3.insert(3,'B') #在列表的索引为3的位置插入一个值 B >>> l3 ['a', 'b', 'c', 'B', 'd', 'e', '1', '2', 'A'] >>> l3[3] = 'boy' #把索引3的元素修改为boy >>> l3 ['a', 'b', 'c', 'boy', 'd', 'e', '1', '2', 'A'] >>> l3[4:6] = 'ALEX' #把所以4-6的元素修改为ALEX,不够的元素自动增加 >>> l3 ['a', 'b', 'c', 'boy', 'A', 'L', 'E', 'X', '1', '2', 'A'] >>>
删除
>>> l3.pop() #删除最后一个元素 'A' >>> l3.remove('A') #删除从左找到的第一个指定元素 >>> l3 ['a', 'b', 'c', 'boy', 'L', 'E', 'X', '1', '2'] >>> del l3[4] #用python全局的删除方法删除指定元素 >>> l3 ['a', 'b', 'c', 'boy', 'E', 'X', '1', '2']
循环
for i in l3: print(i)
排序
>>> l3.sort() #排序 >>> l3 ['1', '2', 'E', 'X', 'a', 'b', 'boy', 'c'] >>> l3.reverse() #反转 >>> l3 ['c', 'boy', 'b', 'a', 'X', 'E', '2', '1']
其他
>>> l3 ['c', 'boy', 'b', 'a', 'X', 'E', '2', '1'] >>> l3.extend([1,2,3,4]) #把一个列表扩展到l3列表 >>> l3 ['c', 'boy', 'b', 'a', 'X', 'E', '2', '1', 1, 2, 3, 4] >>> l3[2]=['alex','jack','rain'] #嵌套 >>> l3 ['c', 'boy', ['alex', 'jack', 'rain'], 'a', 'X', 'E', '2', '1', 1, 2, 3, 4] >>> l3[2][2] #嵌套列表取值 'rain' >>> l3.clear() #清空 >>> l3 []
3.数据类型--字符串
字符串是一个有序的字符集合,用于存储和表示基本的文本信息,一对单、双或三引号中间包含的内容称之为字符串
s='hello word!'
特性:
- 有序
- 不可变
4.数据类型--元组
元组其实跟列表差不多,也是存一组数,一旦创建便不能再修改,又叫只读列表
names=(‘alex’,'jack','eric')
特性
- 不可变
- 元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变
功能:
- index
- count
- 切片
使用场景:
- 显示的告知别人,此处数据不可修改
- 数据库连接配置信息等
5.hash
hash,一般翻译做‘散列’,或者‘哈希’,就是把任意长度的输入,通过散列算法,变成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不通的输入可能会散裂成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
特征:hash值的计算过程是依据这个值的一些特征计算的,这就要求被hash的值必须固定,因此被hash的值必须是不可变的。
>>> hash('abc') 4692608206072234457
用途
- 文件签名
- md5加密
- 密码验证
6.数据类型--字典
字典是一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
特性:
- key-value结构
- key必须可hash,且必须为不可变数据类型、必须唯一
- 可存放任意多个值,可修改,可以不唯一
- 无序
- 查找速度快
info = {'stu01': 'alex', 'stu02': 'jack','stu03': 'rain'}
>>> info = {'stu01': 'alex', 'stu02': 'jack','stu03': 'rain'}
>>> info.items()
dict_items([('stu01', 'alex'), ('stu02', 'jack'), ('stu03', 'rain')])
>>> info
{'stu01': 'alex', 'stu02': 'jack', 'stu03': 'rain'}
>>> for key in info: # 循环
... print(key,info[key])
...
stu01 alex
stu02 jack
stu03 rain
>>>
7.数据类型-集合
集合中的元素有三个特征:
- 确定性(元素必须可hash)
- 互异性(去重)
- 无序性(集合中的元素没有先后之分),如结合{3,4,5}和{4,5,3}算作通一个集合
>>> s={1,2,3,4,5} #创建集合
>>> s.add(2) #添加元素,重复的添加不进去
>>> s.add(44) #添加元素44
>>> s
{1, 2, 3, 4, 5, 44}
>>> s.pop() #随机删除一个元素
1
>>>
集合关系
- 交集
- 差集
- 并集
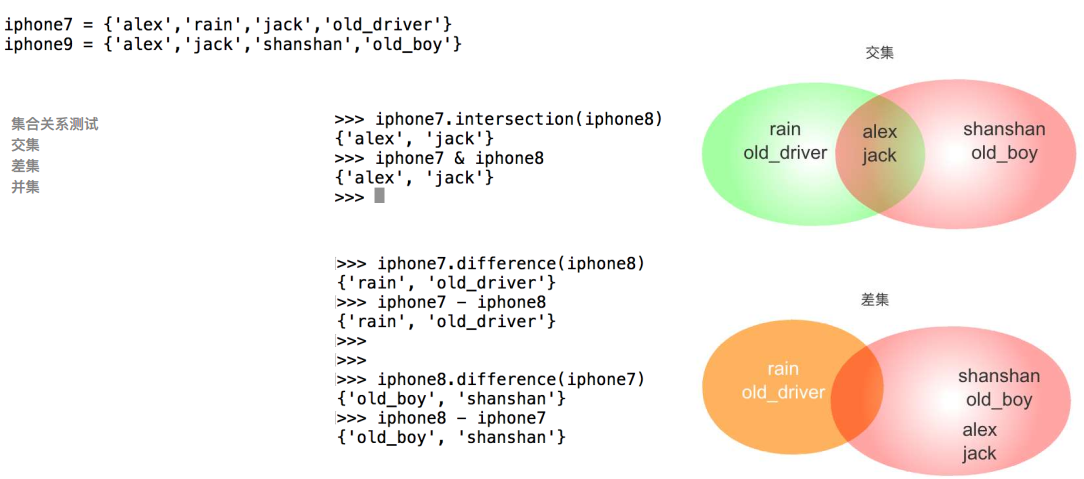
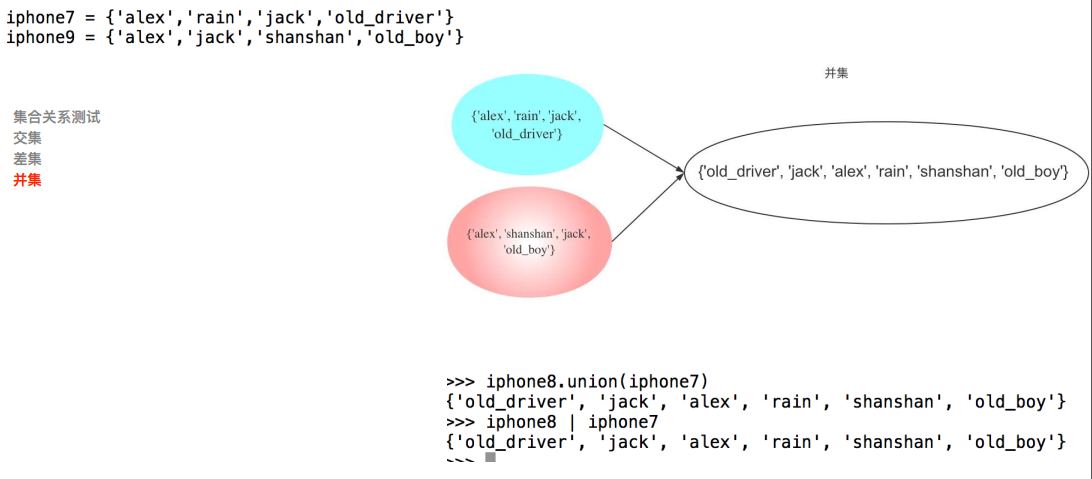

包含关系:
in,not in :判断某元素是否在集合内
==,!==:判断两个集合是否相等
set.isdisjoint(s):判断两个集合是不是不相交
set.issuperset(s) :判断集合是不是包含其他集合,等同于a>=b
set.issubset(s):判断集合是不是被其他集合包含,等同于a<=b
8.进制
十进制转换8、16进制语法
oct() 8进制
hex() 16进制
为什么用16进制
- 计算机硬件是0101二进制,16进制刚好是2的倍数,更容易表达一个命令或者数据,十六进制更简短,一位16进制可以顶四位2进制数
- 8bit用2个16进制直接就表达出来,不管阅读还是存储都比其他进制方便
- 计算机中CPU运算也是遵照ASCII字符集,以16、32、64这样的方式在发展,因此数据交换的时候16进制也显得更好
- 为了统一规范,CPU、内存、硬盘采用的都是16进制计算
16进制用在哪里
- 网络编程,数据交换的时候需要对自己饿进行解析都是一个byte一个byte的处理,一个byte可以用0xFF两个16进制来表达
- 数据存储,存储到硬件中是0101的方式,存储到系统中的是byte方式
- 一些常用值的定义,比如:html中从color表达

 浙公网安备 33010602011771号
浙公网安备 33010602011771号