
transformer-1
Covariant Shift
字面意思理解就是训练分布和测试分布发生偏移,模型y=f(x),训练x发生偏移,y值无法预测准确,f可能失效
- dataset covariant 如何识别
- trainset 和 testset 混合, 新增label(1 if train esle 0)
- 在测试集查看auc—roc,如果比较大,说明训练和测试集较容易区分,分别差异大
- 需要剔除drifting features
- target covariant 目标变量不均衡
- 上采样和下采样
- 上采样容易产生重复样本,过拟合;下采样容易丢失样本,信息损失
- 随机上采样;下采样(SMOTE,Borderline-SMOTE)
- 正负样本损失添加权重(torch.nn.CrossEntropyLoss(weight=None, size_average=True, ignore_index=-100, reduce=True),weight可指定类别权重)
- 上采样和下采样
深度学习ICS(Internal Covariate Shift)
深度学习第Li和Li+1层之间的分布变化,导致训练困难,不容易收敛
ICS导致的问题:
- 容易陷入激活层(sigmod,tanh)的饱和区,降低模型收敛速度
- 学习速率需要减少来适应分布变化
解决ICS方法
- 采用非饱和激活函数ReLU(max(0,x)), Leaky ReLU(max(0.1x,x))
- 更小的学习速率
- 更精细的参数初始化
- 数据白化(标准化)
- BN
BN(batch normalization)
按照batch维度,对每个特征进行归一化\(N(0,1)\)
\[\begin{align}
\mu_j &= \frac{1}{m} \sum_{i=1}^{m}Z_j^i \\
\sigma_j^2 &= \frac{1}{m}\sum_{i=1}^{m}(Z_j^i-\mu_j)^2 \\
Z_j &= \gamma_j \frac{Z_j-\mu_j}{\sqrt{\sigma_j^2+\epsilon}} +\beta_j
\end{align}
\]
一般都使用滑动平均
\[\begin{align}
\overline{\mu} &= p*\overline{\mu} + (1-p)*\mu_t \\
\overline{\sigma^2} &= p* \overline{\sigma^2} +(1-p)\sigma_t
\end{align}
\]
训练保存\(\mu\)和\(\sigma\),预测时直接使用
Layer Normalization
LN一般用在文本处理比较多,文本类在batch维度做归一化实际意义不大,但在句子维度做归因化可以很好规避句子长度不一问题。
NLP: batch_size * seq_len * dim, 在dim维度进行归一化
CV: batch_size * channel * (h*w) h,w 维度归一化,也就是对整个图归一化
Transformer LN 改进之 Pre-LN
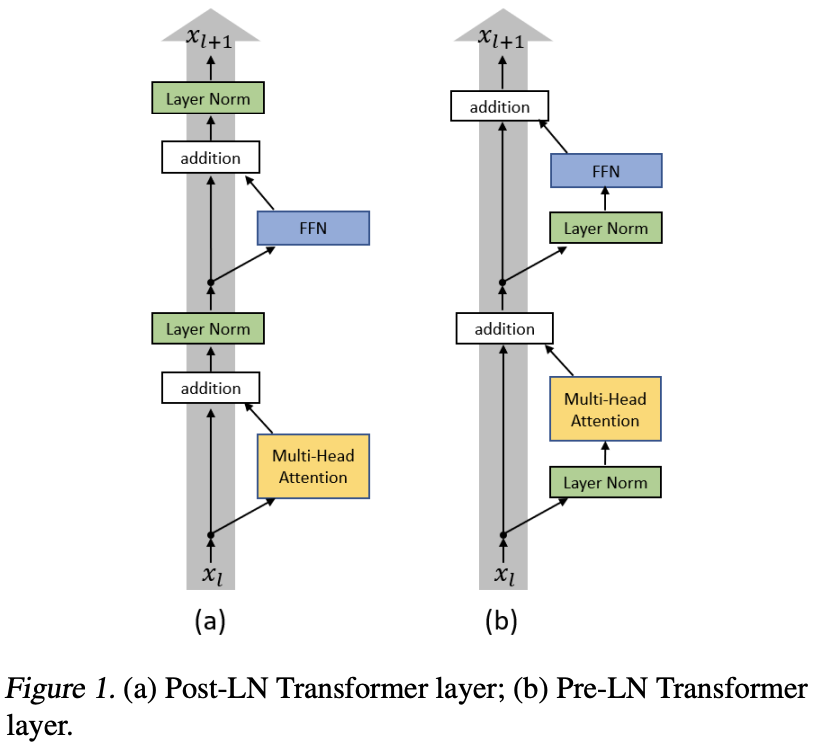
Pre-LN LN放置在residule block 之前
Post-LN LN放置在residule block 之后
更容易训练同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm
Pre LN vs. Post LN
- Post-LN 前期gradient norm比较大,较大的learning rate会引起模型震荡,所以需要前期对lr进行warm-up
- Pre-LN 前期gradient norm较小,不需要对lr warm-up
- lr进行warm-up 会引入超参,不好调整

 浙公网安备 33010602011771号
浙公网安备 33010602011771号