
Multi-Head Self-Attention
2024.3.13 Multi-Head Self-Attention
Self-Attention
Self-Attention 其实是 Attention 的一个具体做法
给定一个 X,通过自注意力模型,得到一个 Z,这个 Z 就是对 X 的新的表征(词向量),Z 这个词向量相比较 X 拥有了句法特征和语义特征
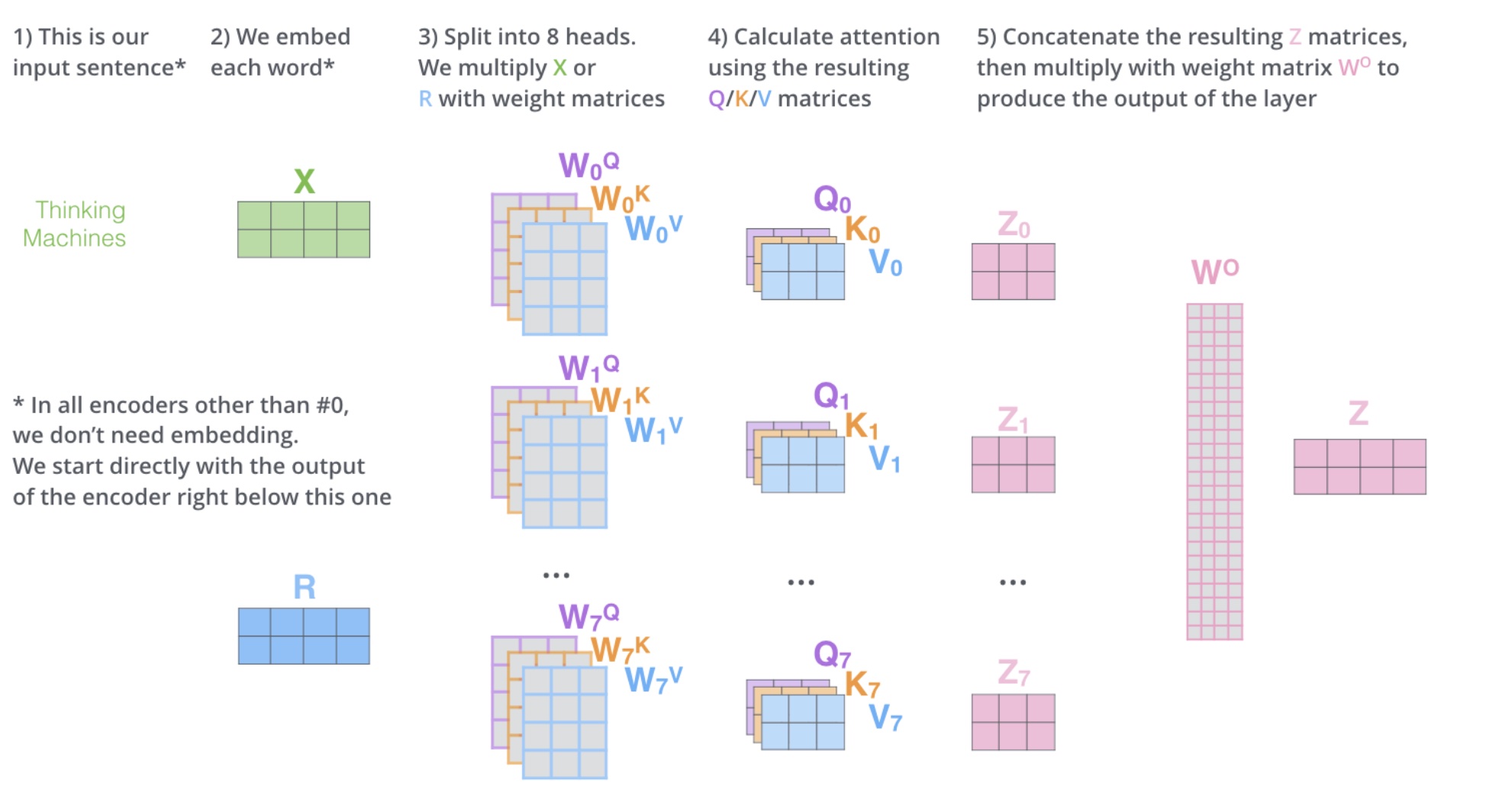
Multi-Head Self-Attention(多头自注意力)
Z 相比较 X 有了提升,通过 Multi-Head Self-Attention,得到的$Z'$相比较 Z 又有了进一步提升
多头自注意力,问题来了,多头是什么,多头的个数用 h 表示,一般h=8,我们通常使用的是 8 头自注意力
什么是多头

如何多头 1

对于 X,我们不是说,直接拿 X 去得到 Z,而是把 X 分成了 8 块(8 头),得到 Z0~Z7
如何多头 2
然后把 Z0-Z7 拼接起来,再做一次线性变换(改变维度与X相同)得到 Z

多头的作用
机器学习的本质:$y=\sigma(wx+b)$,做非线性变换(把一个看起来不合理的东西,通过某种手段(训练模型),让这个东西变得合理)
非线性变换的本质:改变空间上的位置坐标,任何一个点都可以在维度空间上找到,通过某个手段让一个不合理的点(位置不合理),变得合理
这就是词向量的本质
one-hot编码:0101010110
word2vec:(11.222.33)让词与词之间可以计算
Emlo:(15,3,2)一次多义
attention:(124,2,32)可以并行
multi-head attention:(123,12,654)把X切分成8块(8个子空间),这样一个原先在一个位置上的X,去了空间上8个位置,通过对8个点进行寻找,找到更合适的位置
切分成8块,其实就是选了8个不同的$W_q$做8次不同的线性变换
多头流程图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号