
Self-Attention相比较RNN和LSTM的优缺点
2024.3.13 Self-Attention
Self-Attention相比较RNN和LSTM的优缺点
RNN基本单元结构

无法做长序列,当一段话达到50个字,效果就很差 了复杂度为n的平方
$X_0$往后面越传播,信息越少(如你爷爷的爷爷的爷爷的名字)
LSTM基本结构
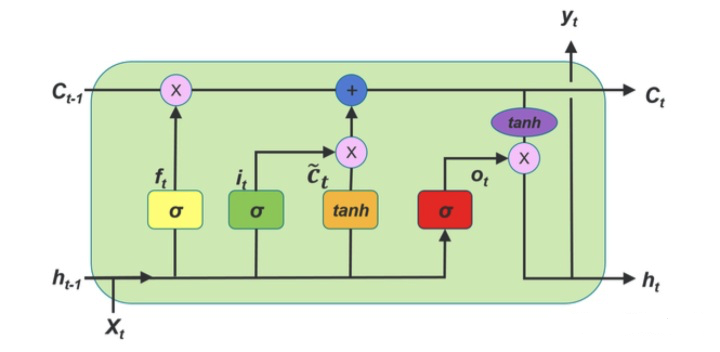
LSTM通过各种门,遗忘门,选择性的可以记忆之前的信息(200词)
Self-Attention和RNNs(RNN和LSTM)的区别
RNNs长序列依赖问题,无法做并行
而Self-Attention中计算每个单词之间的相似度,从而解决了长序列依赖问题。并且在计算每个单词之间的相似度问题时是独立进行的,因此可以做并行
Self-Attention得到的新的词向量具有句法特征和语义特征(词向量的表征更完善)
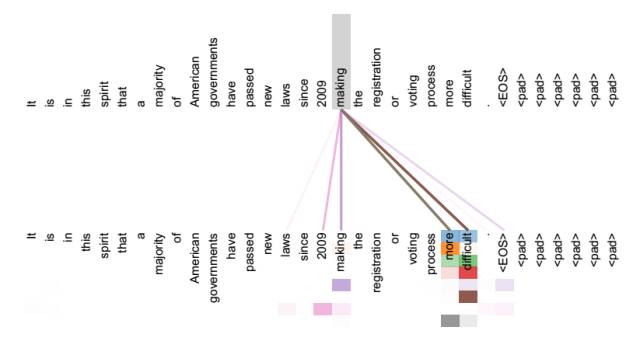
句法特征
语义特征
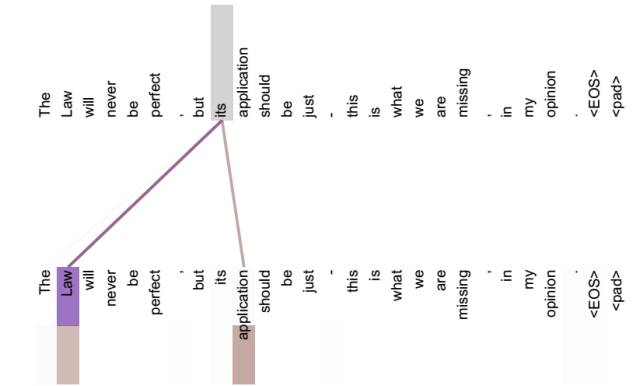
Self-Attention无论句子序列多长,都可以充分捕获近距离上往下问中的任何依赖关系,进而可以很好的提取句法特征还可以提取语义特征;而且对于一个句子而言,每个单词的计算是可以并行处理的。
理论上 Self-Attention (Transformer 50 个左右的单词效果最好)解决了 RNN 模型的长序列依赖问题,但是由于文本长度增加时,训练时间也将会呈指数增长,因此在处理长文本任务时可能不一定比 LSTM(200 个左右的单词效果最好) 等传统的 RNN 模型的效果好。
上述所说的,则是为何 Self Attention 逐渐替代 RNN、LSTM 被广泛使用的原因所在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号