
V8R6集群备机故障处理
实验环境:
192.168.40.148 node1 primary
192.168.40.149 node2 standby
当备机149故障后,有三种方式拉起备机:①备机利用sys_rewind追平主机的数据;②重新clone主机148的数据;③从主机copy整个data到备机,修改部分配置文件;
方式一:备机利用sys_rewind追平主机的数据;
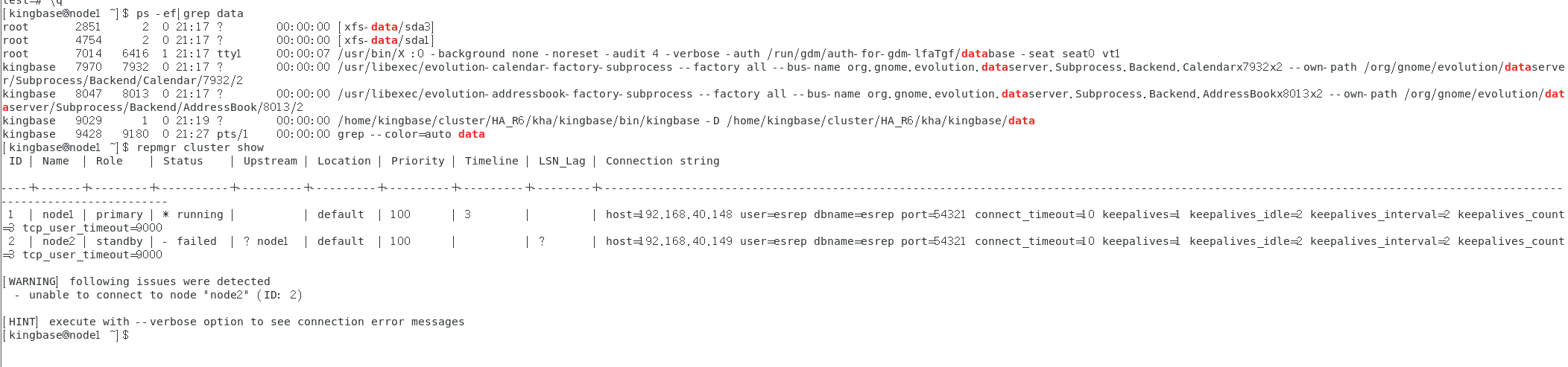
192.168.40.148 是主库的ip,需要将备库的数据库服务关闭,在备库node2上操作:
sys_ctl stop -D /home/kingbase/cluster/HA_R6/kha/kingbase/data
repmgr node rejoin -h 192.168.40.148 -U esrep -d esrep --force-rewind

主库node1上操作:repmgr cluster show

目前集群已经恢复;
方式二:重新clone主机148的数据;

node2 上停库,删除data,重新进行clone:
sys_ctl stop -D /home/kingbase/cluster/HA_R6/kha/kingbase/data
rm -rf /home/kingbase/cluster/HA_R6/kha/kingbase/data
node1上进行查询, 此时,repmgr cluster show看出备机挂了;

node2上执行:
repmgr standby clone -h192.168.40.148 -U esrep -d esrep
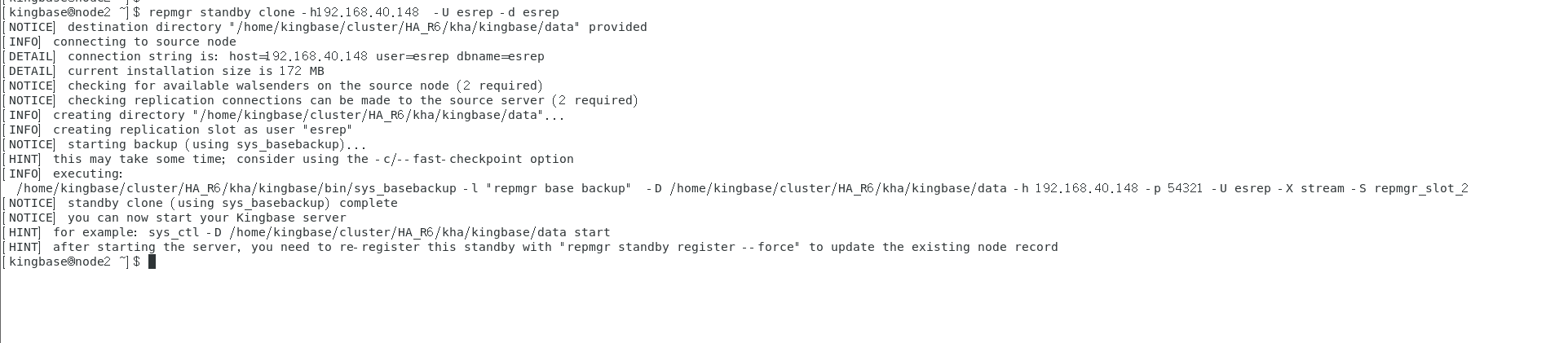
sys_ctl start -D /home/kingbase/cluster/HA_R6/kha/kingbase/data
repmgr standby register -F

node1上查看集群状态:

方式三:从主机copy整个data到备机,修改部分配置文件;
sys_ctl stop -D /home/kingbase/cluster/HA_R6/kha/kingbase/data
rm -rf /home/kingbase/cluster/HA_R6/kha/kingbase/data
node1上进行查询, 此时,repmgr cluster show看出备机挂了;
node1上执行:
scp -r data kingbase@192.168.40.149:/home/kingbase/cluster/HA_R6/kha/kingbase

node2上执行:
cd /home/kingbase/cluster/HA_R6/kha/kingbase/data/
touch standby.signal

cd sys_replslot;
rm -rf /home/kingbase/cluster/HA_R6/kha/kingbase/data/sys_replslot/*
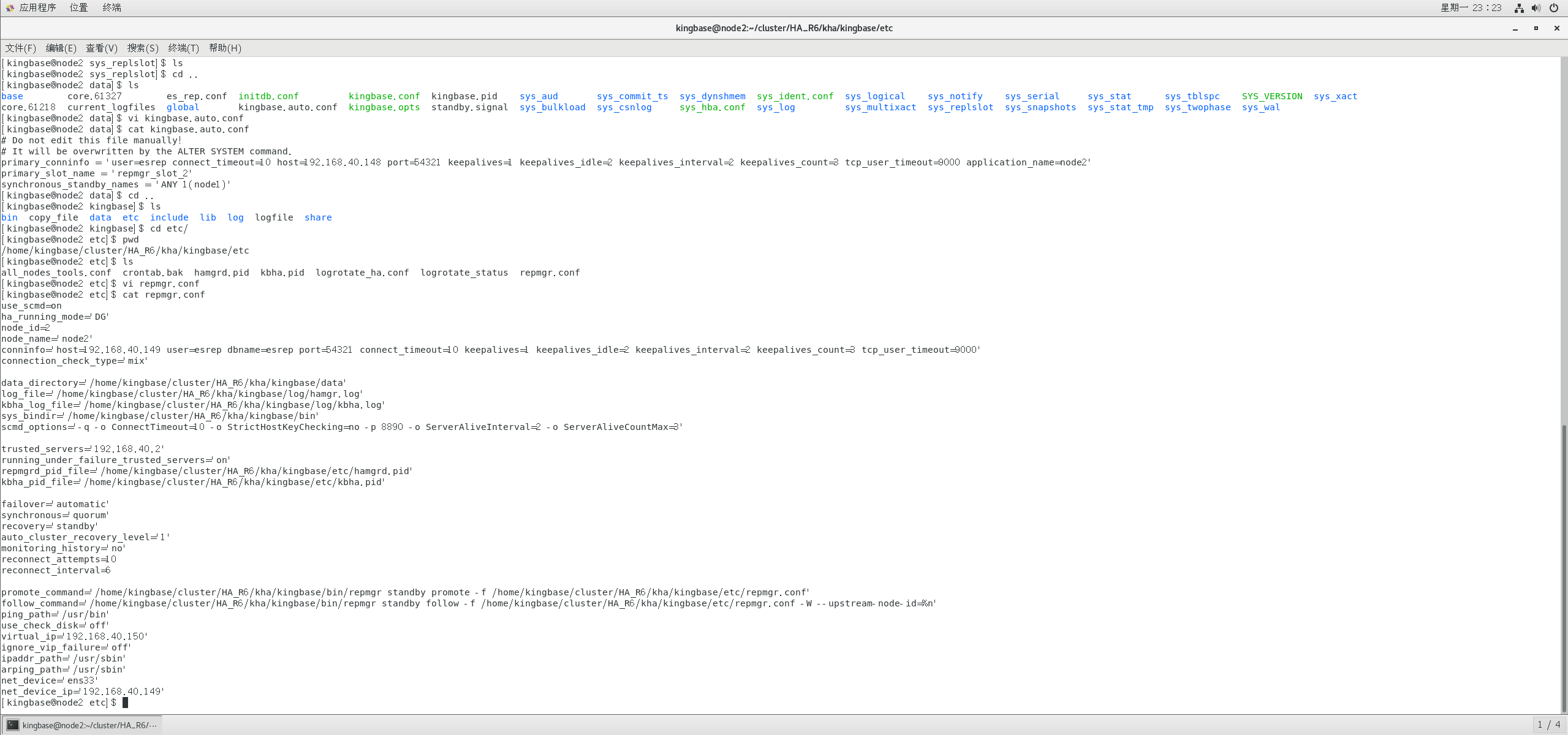
 node2上编辑kingbase.auto.conf
node2上编辑kingbase.auto.conf
primary_conninfo = 'user=esrep connect_timeout=10 host=192.168.40.148 port=54321 keepalives=1 keepalives_idle=2 keepalives_interval=2 keepalives_count=3 tcp_user_timeout=9000 application_name=node2'
primary_slot_name = 'repmgr_slot_2'
synchronous_standby_names = 'ANY 1(node1)'
node2上编辑/home/kingbase/cluster/HA_R6/kha/kingbase/etc下的repmgr.conf
node2上启动数据库:
sys_ctl start -D /home/kingbase/cluster/HA_R6/kha/kingbase/data
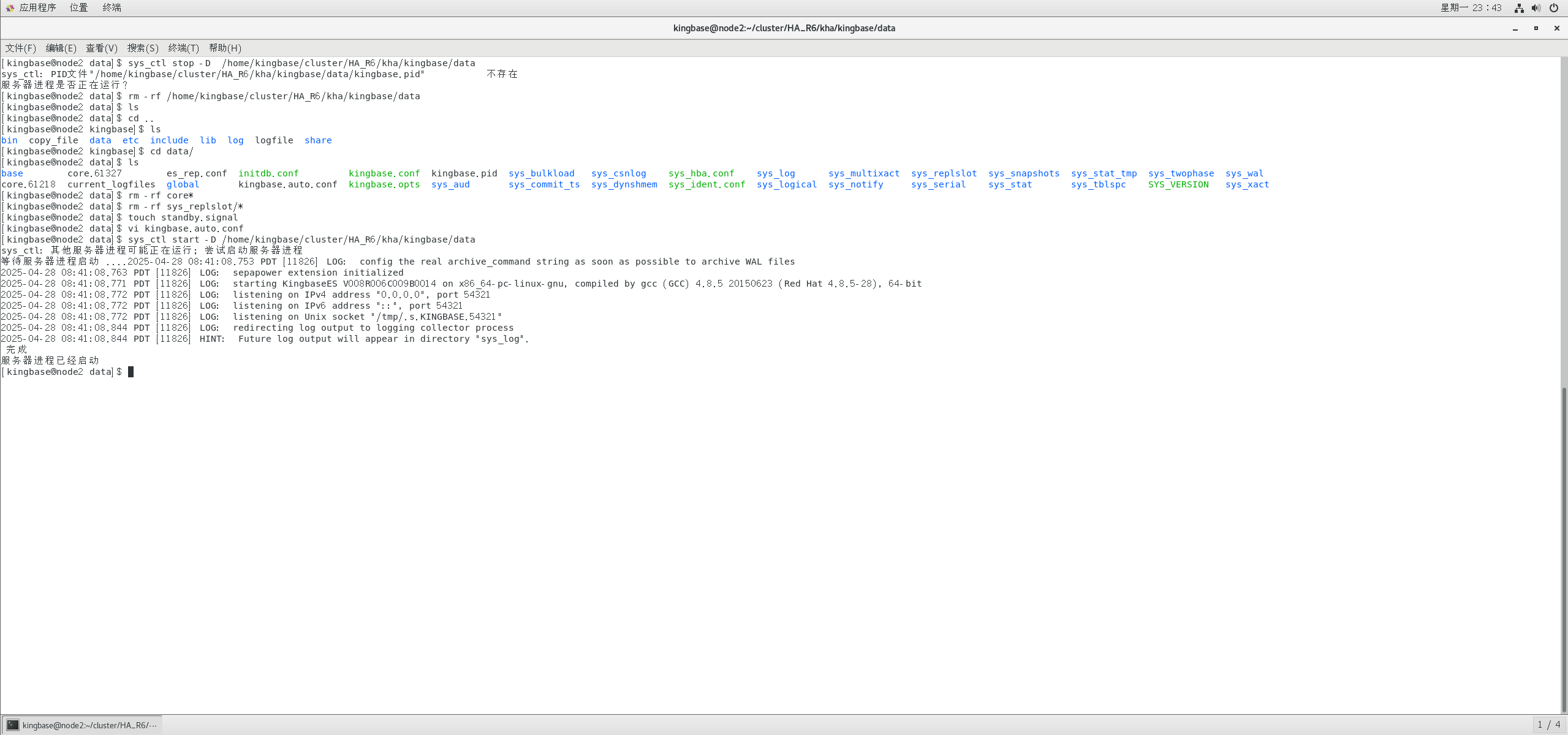
node1上查看集群状态:

此时集群正常,备机也恢复正常;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号