数据采集与融合技术作业二
作业①
实验要求及结果
- 要求
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。 - 代码
点击查看代码
from bs4 import BeautifulSoup, UnicodeDammit
import urllib.request
import sqlite3
# 天气数据库类
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), constraint pk_weather primary key (wCity, wDate))")
except Exception as err:
print("Table already exists, clearing data:", err)
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity, wDate, wWeather, wTemp) values (?, ?, ?, ?)",
(city, date, weather, temp))
except Exception as err:
print("Insert error:", err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("City", "Date", "Weather", "Temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
# 天气预报类
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
self.db = None
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(f"{city} code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print("Parsing error:", err)
except Exception as err:
print("Request error:", err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
# 调用天气预报程序
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("Completed")
- 运行结果
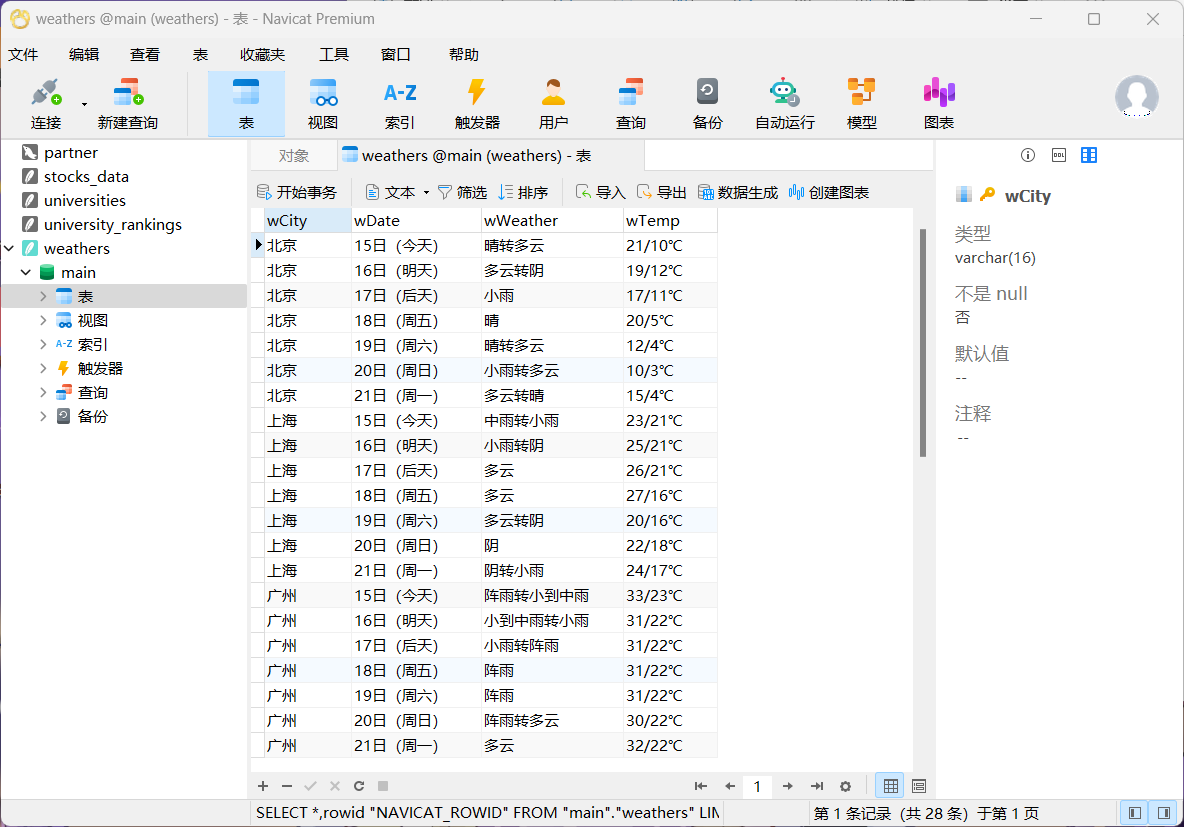
心得体会
- 通过这次作业,我学会了如何利用Python的requests和BeautifulSoup库来爬取中国气象网的7日天气预报数据。
- 在这个过程中,我学会了如何分析和处理HTML页面结构此外,我还熟练掌握了SQLite数据库的基本操作,包括创建表、插入数据和查询数据。
作业②
实验要求及结果
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/ -
代码:
点击查看代码
import requests
import re
import sqlite3
# 连接SQLite数据库,创建数据库文件
connection = sqlite3.connect('stocks_data.db')
cursor = connection.cursor()
# 创建表格
create_table_sql = """
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
latest_price REAL,
change_rate REAL,
change_amount REAL,
volume INTEGER,
turnover INTEGER,
amplitude REAL,
highest REAL,
lowest REAL,
opening_price REAL,
previous_close REAL,
volume_ratio REAL,
turnover_rate REAL,
pe_ratio REAL,
pb_ratio REAL
);
"""
cursor.execute(create_table_sql)
connection.commit()
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0",
"Cookie": "qgqp_b_id=c358a3ef431fdeb8bab829150de55857; st_si=45644677308239; HAList=ty-0-300059-%u4E1C%u65B9%u8D22%u5BCC; st_asi=delete; st_pvi=36719701084546; st_sp=2024-10-15%2014%3A56%3A34; st_inirUrl=https%3A%2F%2Fwww.eastmoney.com%2F; st_sn=7; st_psi=20241015151240611-113200301321-6110855007"
}
# 获取股票数据的接口函数
def get_html(cmd, page):
url = f"https://98.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409605352694558194_1728976797660&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728976797661"
response = requests.get(url, headers=header)
data = response.text
# 提取JSON格式数据
left_data = re.search(r'^.*?(?=\()', data).group()
data = re.sub(left_data + '\(', '', data)
data = re.sub('\);', '', data)
data = eval(data) # 解析成Python字典格式
return data
# 股票分类及接口参数
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "f3&fs=m:1+t:2,m:1+t:23",
"深证A股": "f3&fs=m:0+t:6,m:0+t:80",
"北证A股": "f3&fs=m:0+t:81+s:2048",
}
# 爬取并保存股票数据到数据库
for market_name, market_code in cmd.items():
page = 0
while True:
page += 1
data = get_html(market_code, page)
if page <= 2:
print(f"正在爬取 {market_name} 第 {page} 页")
stock_list = data['data']['diff']
for stock in stock_list:
code = stock["f12"]
name = stock["f14"]
latest_price = stock["f2"]
change_rate = stock["f3"]
change_amount = stock["f4"]
volume = stock["f5"]
turnover = stock["f6"]
amplitude = stock["f7"]
highest = stock["f15"]
lowest = stock["f16"]
opening_price = stock["f17"]
previous_close = stock["f18"]
volume_ratio = stock["f10"]
turnover_rate = stock["f8"]
pe_ratio = stock["f9"]
pb_ratio = stock["f23"]
# 插入数据到SQLite数据库
insert_sql = """
INSERT INTO stocks (code, name, latest_price, change_rate, change_amount, volume, turnover, amplitude,
highest, lowest, opening_price, previous_close, volume_ratio, turnover_rate, pe_ratio, pb_ratio)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
cursor.execute(insert_sql,
(code, name, latest_price, change_rate, change_amount, volume, turnover, amplitude,
highest, lowest, opening_price, previous_close, volume_ratio, turnover_rate, pe_ratio,
pb_ratio))
else:
break
# 提交并关闭数据库连接
connection.commit()
cursor.close()
connection.close()
print("股票数据已成功存储到SQLite数据库中")
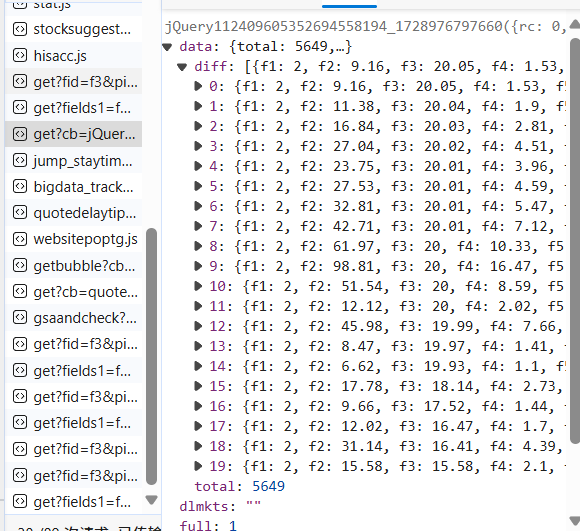
- 截图

心得体会
作业③
实验要求及结果
-
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
-
代码:

点击查看代码
import requests
import re
import sqlite3
class UniversityDB:
def __init__(self):
self.con = sqlite3.connect("universities.db")
self.cursor = self.con.cursor()
self.create_table()
def create_table(self):
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS universities (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER,
name TEXT,
province TEXT,
category TEXT,
score REAL
)
""")
self.con.commit()
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, rank, name, province, category, score):
self.cursor.execute("""
INSERT INTO universities (rank, name, province, category, score)
VALUES (?, ?, ?, ?, ?)
""", (rank, name, province, category, score))
def show(self):
self.cursor.execute("SELECT * FROM universities")
rows = self.cursor.fetchall()
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format("排名", "学校", "省份", "类型", "总分"))
for row in rows:
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format(row[1], row[2], row[3], row[4], row[5]))
class UniversityForecast:
def __init__(self):
self.db = UniversityDB()
def fetch_data(self, url):
response = requests.get(url)
response.raise_for_status()
return response.text
def parse_data(self, text):
name = re.findall(',univNameCn:"(.*?)",', text)
score = re.findall(',score:(.*?),', text)
category = re.findall(',univCategory:(.*?),', text)
province = re.findall(',province:(.*?),', text)
code_name = re.findall('function(.*?){', text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',')
value_name = re.findall('mutations:(.*?);', text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value + 1:end_value].split(",")
universities = []
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
category_name = value_name[code_name.index(category[i])][1:-1]
universities.append((i + 1, name[i], province_name, category_name, score[i]))
return universities
def process(self, url):
try:
text = self.fetch_data(url)
universities = self.parse_data(text)
for uni in universities:
self.db.insert(uni[0], uni[1], uni[2], uni[3], float(uni[4]))
except Exception as err:
print(f"Error processing data: {err}")
def show_database(self):
print("\n开始输出数据库:\n")
self.db.show()
def close_database(self):
self.db.closeDB()
# 使用示例
if __name__ == "__main__":
forecast = UniversityForecast()
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
forecast.process(url)
forecast.show_database()
forecast.close_database()
print("completed")
print("输出数据库完成")
- 运行结果:
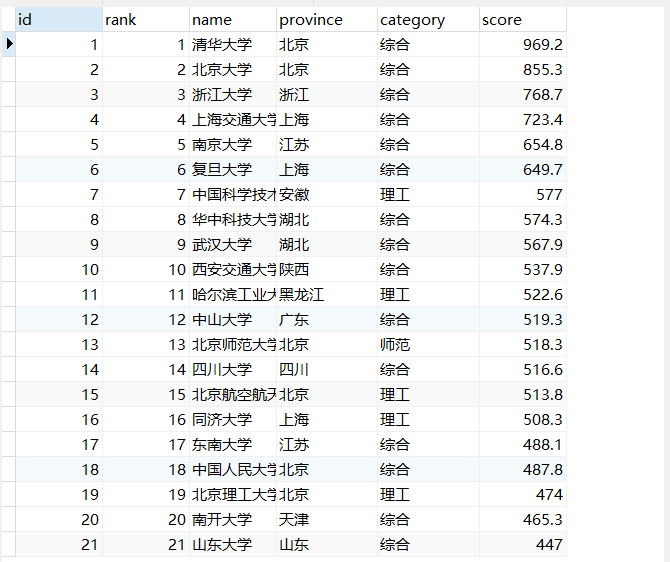
心得体会
- 正则表达式的应用:通过正则表达式提取复杂文本中的特定信息,提高了数据处理的灵活性,但也需要注意正则的匹配精度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号