数据结构杂谈
限于作者水平不高,就讲一些水题。
做完你就数据结构入门了。
分为多个部分。
RMQ
P14638 [NOIP2025] 序列询问
思路
套路的将区间求值等转换为二维数点,这是一个常用trick。于是可以变成求这样一个梯形中的最大值。
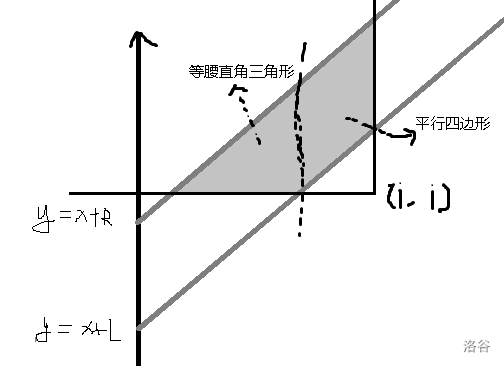
想到这个图上的梯形可以像如图中所示一样分成一个平行四边形和一个三角形,三角形可以使用如下分法转换成平行四边形和正方形:
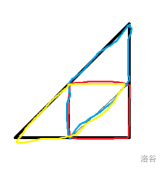
转换成平行四边形和正方形的最大值用单调队列是好求的,做完了。
注意不要6次单调队列求,常数大并且不好调,可以拿一个数组存一下再求可以优化到四次并且错误率低。
队列建议手写。
代码
void ACehomoxue() {
cin >> n;
for(int i = 1; i <= n; i++) { cin >> sum[i]; sum[i] += sum[i - 1]; }
cin >> q;
for(int _ = 1, l, R, k; _ <= q; _++) {
ans = 0;
cin >> l >> R;
k = (R - l) >> 1;
qu.clear();
for(int i = n; i >= 0; i--) {
while(!qu.empty() && qu.front() > i + k) qu.pop_front();
while(!qu.empty() && sum[qu.back()] <= sum[i]) qu.pop_back();
qu.push(i);
mx[i] = sum[qu.front()];
}
qu.clear();
for(int i = 0; i <= n; i++) {
while(!qu.empty() && qu.front() < i - k) qu.pop_front();
while(!qu.empty() && sum[qu.back()] >= sum[i]) qu.pop_back();
qu.push(i);
mn[i] = sum[qu.front()];
}
for(int i = 1; i <= n; i++) res[i] = -1e18;
for(int i = l; i <= n; i++) res[i] = mx[i] - mn[i - l];
for(int i = 1; i <= n; i++) {
a[i] = -1e18;
if(i + l - 1 <= n) a[i] = max(mx[i + l - 1], mx[max(0ll, min(n, i + R - k - 1))]) - sum[i - 1];
}
qu.clear();
for(int i = 1; i <= n; i++) {
while(!qu.empty() && qu.front() <= i - l) qu.pop_front();
while(!qu.empty() && a[qu.back()] <= a[i]) qu.pop_back();
qu.push(i);
res[i] = max(res[i], a[qu.front()]);
}
for(int i = l; i <= n - k; i++) {
if(R - l == 2 * k) a[i] = max(mx[i + k] - sum[i - l], sum[i + k] - mn[i - l]);
else a[i] = max(max(mx[i + k], sum[min(n, i + R - l)]) - sum[i - l], sum[i + k] - min(mn[i - l], sum[max(0LL, i - R + k)]));
}
for(int i = n - k + 1; i <= n; i++) a[i] = -1e18;
qu.clear();
for(int i = l; i <= n; i++) {
while(!qu.empty() && qu.front() < i - k) qu.pop_front();
while(!qu.empty() && a[qu.back()] <= a[i]) qu.pop_back();
qu.push(i);
res[i] = max(res[i], a[qu.front()]);
}
for(int i = 1; i <= n; i++) ans = ans ^ (1ull * i * res[i]);
cout << ans, el;
}
}
P2048 [NOI2010] 超级钢琴
思路
提供一种 \(n log ^ 2n\) 的做法,RMQ但又不RMQ,比较stdag又不stdag。
考虑取k次最大值,并且每次把找到的最大值删掉。
单次求最大值可以使用st表加上堆。先预处理前缀和,每个点作为起点开个堆记为 \(p_i\) ,堆顶表示为可作为终点的点中前缀和最大的点的前缀和。这样第 \(i\) 个点的答案显然为 \(p_i.top() - sum_{i - 1}\)。最朴素的想法就是 \(p_i\) 去push所有 \(sum_j(j \in [i + L - 1,i + R - 1])\) 。显然这样复杂度不对,可以预处理前缀和数组的st表,并且把st表的段段给push进去。最后再把每个 \(p_i.top() - sum_{i - 1}\) push到一个大的堆里面,大的堆的堆顶即为答案。
单次解决了考虑 \(k\) 次。我们可以考虑每次取最大值然后再将其删掉。
但直接把代表最大值的段段删了显然是不行的。想到st表的大段段是从下面的小段段一个个合并上来的,那么一个大段段也可以拆成若干个小段段。我们发现可以递归找到一直包含最大值的段段并删掉并加入其兄弟段段,即将一个大段段拆成log个小段段的同时删除所有包含原来最大值的段段。
具体看起来长这样:

考虑到为了使段段不重合,最开始初始化每个起点的堆的时候得用二进制拆分。所以为什么用st表而不用线段树?
log很小其实,跑的不慢。
代码
int n, k, l, r, a[maxn], sum[maxn][20], ans = 0;
struct node {
int i, k;
node(int ii = 0, int kk = 0) { i = ii, k = kk; }
} ;
inline bool operator <(node a, node b) { return sum[a.i][a.k] < sum[b.i][b.k]; }
int top[maxn];
priority_queue <node> p[maxn];
priority_queue < pair <int, int> > pq;
void del(int i, int k, int id) {
if(k == 0) AC;
if(sum[i][k - 1] == top[id]) {
p[id].push(node(i + (1 << (k - 1)), k - 1));
del(i, k - 1, id);
} else {
p[id].push(node(i, k - 1));
del(i + (1 << (k - 1)), k - 1, id);
}
}
int solve() {
int i = pq.top().second; pq.pop();
int pi = p[i].top().i, k = p[i].top().k; p[i].pop();
del(pi, k, i);
if(!p[i].empty()) {
top[i] = sum[p[i].top().i][p[i].top().k];
pq.push({top[i] - sum[i - 1][0], i});
}
return sum[pi][k] - sum[i - 1][0];
}
void ACehomoxue() {
cin >> n >> k >> l >> r;
for(int i = 1; i <= n; i++) {
cin >> a[i];
sum[i][0] = sum[i - 1][0] + a[i];
}
for(int j = 1; j < 20; j++) {
for(int i = 1; i <= n; i++) {
if(i + (1ll << j) - 1 > n) continue;
sum[i][j] = max(sum[i][j - 1], sum[i + (1ll << (j - 1))][j - 1]);
}
}
for(int i = 1; i <= n; i++) {
int ll = i + l - 1, rr = min(i + r - 1, n);
if(ll > n) continue;
for(int k = 19; k >= 0; k--) {
if(ll + (1 << k) - 1 <= rr) p[i].push(node(ll, k)), ll += (1 << k);
}
top[i] = sum[p[i].top().i][p[i].top().k];
pq.push({top[i] - sum[i - 1][0], i});
}
while(k--) ans += solve();
cout << ans, el;
}
二维数点
P8339 [AHOI2022] 钥匙
思路
首先离线并拆贡献,设二维平面上的点坐标 \((x,y)\) 表示从dfs序为 \(x\) 的点到dfs序为 \(y\) 的点的答案。
由于每种钥匙极少可以预处理出每种钥匙在每种方向会到达哪个宝箱,然后将包含这段路径的点值加一。加点值显然是要按dfs序上的子树什么的来,细节可以看代码(很好推,但是要分几种情况并且注意一些细节。)。至于找宝箱,可以使用简单的dfs。但在原图上dfs是 \(n^2\) 的,所以需要将每种颜色的箱子和钥匙建一棵虚树后在虚树上跑dfs。
需要卡卡常,必要的话可以使用欧拉序加st表 \(O(1)\) 地求lca。
代码
int n, m, g[maxn], c[maxn]; // g: 1 为钥匙, 2 为箱子
vector <int> vec[maxn], co1[maxn], co0[maxn], tr[maxn];
int nxt[maxn][20], dep[maxn], idx, in[maxn], out[maxn];
void pre(int x = 1, int fa = 1) {
in[x] = ++idx;
dep[x] = dep[fa] + 1;
nxt[x][0] = fa;
for(int i = 1; i < 20; i++) nxt[x][i] = nxt[nxt[x][i - 1]][i - 1];
for(auto to : vec[x]) if(to != fa) pre(to, x);
out[x] = idx;
}
int lca(int u, int v) {
if(dep[u] > dep[v]) swap(u, v);
for(int i = 19; i >= 0; i--) if(dep[nxt[v][i]] >= dep[u]) v = nxt[v][i];
if(u == v) return u;
for(int i = 19; i >= 0; i--) if(nxt[v][i] != nxt[u][i]) v = nxt[v][i], u = nxt[u][i];
return nxt[u][0];
}
bool cmp(int a, int b) { return in[a] < in[b]; }
class virtual_tree {
private:
vector <int> vir[maxn];
map <int, bool> vis, is;
void build(vector <int> &p) {
is.clear(), vis.clear();
sort(p.begin(), p.end(), cmp);
int sz = p.size();
for(auto v : p) is[v] = vis[v] = true;
for(int i = 1; i < sz; i++) {
int l = lca(p[i], p[i - 1]);
if(!vis[l]) {
vis[l] = true;
p.push_back(l);
}
}
sort(p.begin(), p.end(), cmp);
for(auto v : p) vir[v].clear();
for(int i = 1; i < p.size(); i++) {
int l = lca(p[i - 1], p[i]);
vir[l].push_back(p[i]);
vir[p[i]].push_back(l);
}
}
void gettreasure(int x, int fa, int cnt, int from) {
if(c[x] == c[from]) {
if(g[x] == 1) cnt++;
else if(cnt > 0) cnt--;
else { tr[from].push_back(x); AC; }
}
for(auto to : vir[x]) {
if(to == fa) continue;
gettreasure(to, x, cnt, from);
}
}
void initcolor(int ty) {
vector <int> p;
p.clear();
for(auto pt : co0[ty]) p.push_back(pt);
for(auto pt : co1[ty]) p.push_back(pt);
build(p);
for(auto pt : co1[ty]) gettreasure(pt, pt, -1, pt);
}
public:
void debug_output() {
for(int i = 1; i <= n; i++) {
cout << i << ':';
for(auto to : tr[i]) cout << to << ' ';
el;
}
}
void solve() {
for(int i = 1; i <= n; i++) {
if(co1[i].empty() || co0[i].empty()) continue;
initcolor(i);
}
// debug_output();
}
} vt;
class BIT {
private:
int c[maxn];
public:
void modify(int p, int x) { for(int i = p; i < maxn; i += lowbit(i)) c[i] += x; }
int query(int p) { int res = 0; for(int i = p; i; i -= lowbit(i)) res += c[i]; return res; }
} ;
class count_point_2D {
private:
int ans[maxn * 2];
BIT ds;
vector < pair <int, int> > upd[maxn], ask[maxn];
void add(int lx, int rx, int ly, int ry, int x = 1) {
upd[lx].push_back({ly, 1 * x});
upd[rx + 1].push_back({ly, -1 * x});
upd[lx].push_back({ry + 1, -1 * x});
upd[rx + 1].push_back({ry + 1, 1 * x});
}
int find(int l, int x) {
for(int i = 19; i >= 0; i--) if(dep[nxt[x][i]] > dep[l]) x = nxt[x][i];
return x;
}
void addline(int s, int t) {
int l = lca(s, t);
if(l != s && l != t) {
add(in[s], out[s], in[t], out[t]);
} else if(l == s) {
add(1, n, in[t], out[t]);
int son = find(l, t);
add(in[son], out[son], in[t], out[t], -1);
} else {
add(in[s], out[s], 1, n);
int son = find(l, s);
add(in[s], out[s], in[son], out[son], -1);
}
}
public:
void addask(int s, int t, int id) { ask[in[s]].push_back({in[t], id}); }
void solve() {
for(int u = 1; u <= n; u++) for(auto v : tr[u]) addline(u, v);
for(int x = 1; x <= n; x++) {
// debug(x);
for(auto tmp : upd[x]) ds.modify(tmp.first, tmp.second);
for(auto tmp : ask[x]) ans[tmp.second] = ds.query(tmp.first);
}
for(int i = 1; i <= m; i++) cout << ans[i] << '\n';
}
} s;
void ACehomoxue() {
cin >> n >> m;
for(int i = 1; i <= n; i++) {
cin >> g[i] >> c[i];
if(g[i] == 1) co1[c[i]].push_back(i);
else co0[c[i]].push_back(i);
}
for(int _ = 1, u, v; _ < n; _++) {
cin >> u >> v;
vec[u].push_back(v);
vec[v].push_back(u);
}
pre();
vt.solve();
for(int i = 1, sp, tp; i <= m; i++) {
cin >> sp >> tp;
s.addask(sp, tp, i);
}
s.solve();
}
ps:这代码常数极大。
李超线段树
这里主要讲其在于斜率优化的题。由于真的很少的斜率优化的题会卡成 \(O(n)\),所以大部分的题都可以直接李超水掉。
这里提供一个小常数板子:
int calc(int k, int b, int x) { return k * x + b; }
class Lichao_xds {
private:
struct tree {
int l, r, k, b;
} t[maxn << 2];
public:
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r, t[i].k = 0, t[i].b = -1e18;
if(l == r) AC;
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
}
void updata(int i, int k, int b) {
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(calc(k, b, mid) > calc(t[i].k, t[i].b, mid)) swap(t[i].k, k), swap(t[i].b, b);
if(calc(k, b, t[i].l) > calc(t[i].k, t[i].b, t[i].l)) updata(i * 2, k, b);
if(calc(k, b, t[i].r) > calc(t[i].k, t[i].b, t[i].r)) updata(i * 2 + 1, k, b);
}
int query(int i, int x) {
if(t[i].l == x && t[i].r == x) return calc(t[i].k, t[i].b, x);
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(x <= mid) return max(calc(t[i].k, t[i].b, x), query(i * 2, x));
else return max(calc(t[i].k, t[i].b, x), query(i * 2 + 1, x));
}
} ds;
P6047 丝之割
silksong ~
思路
由于只能从左往右切割,那么可以注意到对于交叉的两根线,切割了左斜的那一条就一定能切割右斜的那一条。即对于题目中的图来说:

对于左边的两根线来说,以上端点从左至右排序第一根线被切了,那么第二根也一定会被切掉。由于所有的线都要切,所以类似于上图第二根线这样的线完全不用考虑,所以可以考虑先把这些线去掉。由于交叉的线都去掉了一根,所以去掉之后的图案应该是左端点和右端点都单调递增的,那么就可以写出dp式子:
然后预处理一下套个板子做完了。
代码
class Lichao_xds {
private:
struct tree {
int l, r, k, b;
} t[maxn * 4];
public:
int calc(int k, int b, int x) { return k * x + b; }
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r, t[i].k = 0, t[i].b = 1e18;
if(l == r) AC;
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
}
void updata(int i, int k, int b) {
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(calc(k, b, mid) < calc(t[i].k, t[i].b, mid)) swap(k, t[i].k), swap(b, t[i].b);
if(calc(k, b, t[i].l) < calc(t[i].k, t[i].b, t[i].l)) updata(i * 2, k, b);
if(calc(k, b, t[i].r) < calc(t[i].k, t[i].b, t[i].r)) updata(i * 2 + 1, k, b);
}
int query(int i, int x) {
if(t[i].l == t[i].r) return calc(t[i].k, t[i].b, x);
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(x <= mid) return min(calc(t[i].k, t[i].b, x), query(i * 2, x));
else return min(calc(t[i].k, t[i].b, x), query(i * 2 + 1, x));
}
} t;
int n, m, a[maxn], b[maxn], up[maxn], down[maxn], dp[maxn], mna[maxn], mnb[maxn];
vector < pair <int, int> > v;
pair <int, int> p[maxn];
bool cmp(pair <int, int> a, pair <int, int> b) {
if(a.first != b.first) return a.first < b.first;
else return a.second > b.second;
}
void main_() {
memset(mna, 0x3f, sizeof(mna));
memset(mnb, 0x3f, sizeof(mnb));
cin >> n >> m;
t.build(1, 1, 1e6);
for(int i = 1; i <= n; i++) cin >> a[i];
for(int i = 1; i <= n; i++) cin >> b[i];
while(m--) {
pair <int, int> o;
cin >> o.first >> o.second;
v.push_back(o);
}
m = 0;
sort(v.begin(), v.end(), cmp);
for(auto tmp : v) {
if(m == 0 || tmp.second > p[m].second) p[++m] = tmp;
}
p[m + 1] = {n, n};
p[0] = {1, 1};
for(int i = 1; i <= n; i++) mna[i] = min(mna[i - 1], a[i]);
for(int i = n; i >= 1; i--) mnb[i] = min(mnb[i + 1], b[i]);
for(int i = 1; i <= m; i++) {
up[i] = mna[p[i].first - 1];
down[i] = mnb[p[i].second + 1];
}
for(int i = 1; i <= m; i++) {
t.updata(1, up[i], dp[i - 1]);
dp[i] = t.query(1, down[i]);
}
cout << dp[m]; el;
}
莫队
P7708 「Wdsr-2.7」八云蓝自动机 Ⅰ
思路
发现是对操作序列进行莫队。
先对问题进行转换。
首先对于两种修改,第一种修改显然是没有第二种好写的,考虑将第一种转换为第二种。想到对于每一次第一种修改可以单开一个点,将其值赋值为要修改的值,这样就可以将第一种修改转换为第二种修改了,即将赋值转换为这个点与新开的点交换点值,这样方便撤销修改。
接下来就应该考虑 add() 与 del() 的写法了。
删除和扩展到的如果是查询点只有加与减的差别。如果是修改点,由于修改的操作是交换,换两次相当于没换,删除和扩展的操作应是一样的。
对于向右扩展与删除,是不会影响到前面的修改的,但对于向左的扩展与删除显然是会的,所以需要分开写。我们假设我们不直接在 \(a\) 数组上修改,而是在 \(rfl\) 数组上修改,\(rfl_i\) 表示进行一系列的交换后 \(i\) 位置所对应的原来的在 \(a\) 数组上的位置,再开两个数组分别为 \(pos\) 与 \(cnt\),\(pos_i\) 表示原来 \(a\) 数组上的 \(i\) 位置现在在 \(rfl\) 数组上对应的位置下标,\(cnt_i\) 表示原来的 \(a\) 数组中 \(i\) 的位置在答案中加了几次。
先考虑更简单的向右扩展或删除。
向右扩展显然是在 \(rfl\) 数组上进行修改。如果扩展到的是查询点,直接修改答案与 \(cnt\) 数组即可。如果扩展到的是修改点,假设交换的位置为 \(u\) 和 \(v\),直接交换 \(rfl\) 数组上对应位置的值,并且修改 \(pos\) 数组上对应位置的值,即交换 \(rfl_u\) 和 \(rfl_v\) 的值,同时交换 \(pos_{rfl_u}\) 和 \(pos_{rfl_v}\) 的值。
再考虑向左扩展或删除。
显然向左扩展我们应该在 \(a\) 数组上进行操作,因为向左扩展或删除的操作显然是最先进行的。如果是查询点方法与向右类似,不再多说。如果是修改点,首先应该减去 \(u\) 和 \(v\) 两点对答案的贡献。显然直接交换 \(a\) 的值是不行的,不然多次交换后会出问题。所以我们应该交换其在 \(rfl\) 对应位置上的值,并交换 \(cnt\) 数组上的值。毕竟如果最开始就将两个位置的值交换了,那后续对这两个位置的查询次数显然也是要交换的。总结下来就是要交换 \(pos_u\) 与 \(pos_v\) 的值,交换 \(rfl_{pos_u}\) 与 \(rfl_{pos_v}\) 的值,交换 \(cnt_u\) 与 \(cnt_v\) 的值,最后别忘了把两个位置的贡献加上。
然后外面套个莫队板子就做完了。
代码
const int maxn = 2 * 1e5 + 6;
int n, block, m, a[maxn * 2], tot, ans[maxn], q, pos[maxn * 2], cnt[maxn * 2], rfl[maxn * 2];
struct node {
int l, r, id;
node(int ll = 0, int rr = 0, int idt = 0) { l = ll, r = rr, id = idt; }
} ;
vector <node> ask;
bool cmp(node a, node b) {
if(a.l / block != b.l / block) return a.l < b.l;
else return a.r < b.r;
}
struct node1 {
int op, u, v;
} b[maxn];
usd answer = 0;
void addl(int i) {
if(b[i].op == 0) { int x = b[i].u; answer += a[x], cnt[x]++; AC; }
answer -= a[b[i].u] * cnt[b[i].u];
answer -= a[b[i].v] * cnt[b[i].v];
swap(cnt[b[i].v], cnt[b[i].u]);
swap(pos[b[i].u], pos[b[i].v]);
swap(rfl[pos[b[i].u]], rfl[pos[b[i].v]]);
answer += a[b[i].u] * cnt[b[i].u];
answer += a[b[i].v] * cnt[b[i].v];
}
void dell(int i) {
if(b[i].op == 0) { int x = b[i].u; answer -= a[x], cnt[x]--; AC; }
answer -= a[b[i].u] * cnt[b[i].u];
answer -= a[b[i].v] * cnt[b[i].v];
swap(cnt[b[i].v], cnt[b[i].u]);
swap(pos[b[i].u], pos[b[i].v]);
swap(rfl[pos[b[i].u]], rfl[pos[b[i].v]]);
answer += a[b[i].u] * cnt[b[i].u];
answer += a[b[i].v] * cnt[b[i].v];
}
void addr(int i) {
if(b[i].op == 0) { int x = rfl[b[i].u]; answer += a[x], cnt[x]++; AC; }
swap(rfl[b[i].u], rfl[b[i].v]);
swap(pos[rfl[b[i].u]], pos[rfl[b[i].v]]);
}
void delr(int i) {
if(b[i].op == 0) { int x = rfl[b[i].u]; answer -= a[x], cnt[x]--; AC; }
swap(rfl[b[i].u], rfl[b[i].v]);
swap(pos[rfl[b[i].u]], pos[rfl[b[i].v]]);
}
void ACehomoxue() {
cin >> n >> m;
block = sqrt(m);
for(int i = 1; i <= n; i++) cin >> a[i];
tot = n;
for(int i = 1; i <= m; i++) {
cin >> b[i].op >> b[i].u;
if(b[i].op == 3) { b[i].op = 0, b[i].v = b[i].u; continue; }
cin >> b[i].v;
if(b[i].op == 1) { a[++tot] = b[i].v; b[i].v = tot; }
else b[i].op = 1;
}
for(int i = 1; i <= tot; i++) cnt[i] = 0, pos[i] = rfl[i] = i;
cin >> q;
for(int i = 1, l, r; i <= q; i++) {
cin >> l >> r;
ask.push_back(node(l, r, i));
}
sort(ask.begin(), ask.end(), cmp);
int l = 1, r = 0;
for(auto tmp : ask) {
int ll = tmp.l, rr = tmp.r, id = tmp.id;
while(l > ll) l--, addl(l);
while(r < rr) r++, addr(r);
while(l < ll) dell(l), l++;
while(r > rr) delr(r), r--;
ans[id] = answer;
}
for(int i = 1; i <= q; i++) cout << ans[i] << '\n';
}
平衡树
我是fhq粉丝所以全用fhq。
P3586 [POI 2015 R2] 物流 Logistics
思路
我太菜了看了题解才会。
设第 \(i\) 个数的值为 \(a_i\)。
首先看到这道题很容易想到判断 \(c * s\) 与 \(\sum a_i\) 的关系。这个显然错误。但将 \(c * s\) 和某个值判断给了我们启发。对于一个大于 \(s\) 的 \(a_i\),他的贡献最多为 \(s\)。因为最多进行 \(s\) 次操作而每次操作最多只能减一个数一次。对于一个小于等于 \(s\) 的数,在减最多次的情况下,显然贡献是 \(a_i\)。于是我们可以算出每个数最多贡献次数之和与 \(c * s\) 比较,于是就做完了。
这个用树状数组和平衡树都可以,但树状数组要离散化麻烦一点。
代码
const int mod = 998244353, maxn = 1e6 + 18;
int n, m, a[maxn];
class fhqtreap {
private:
int ch[maxn][2], siz[maxn], val[maxn], rnd[maxn], tot = 0, rt = 0;
ll sum[maxn];
int add(int x) {
tot++;
siz[tot] = 1;
sum[tot] = val[tot] = x;
ls(tot) = rs(tot) = 0;
rnd[tot] = rand();
return tot;
}
void push_up(int i) {
siz[i] = 1 + siz[ls(i)] + siz[rs(i)];
sum[i] = 1ll * val[i] + sum[ls(i)] + sum[rs(i)];
}
int merge(int l, int r) {
if(l * r == 0) return l ^ r;
int rt;
if(rnd[l] < rnd[r]) {
rt = l;
rs(l) = merge(rs(l), r);
} else {
rt = r;
ls(r) = merge(l, ls(r));
}
push_up(rt);
return rt;
}
void split(int rt, int v, int &l, int &r) {
if(!rt) { l = r = 0; AC; }
if(val[rt] <= v) {
l = rt;
split(rs(l), v, rs(l), r);
push_up(l);
} else {
r = rt;
split(ls(r), v, l, ls(r));
push_up(r);
}
}
void splitsiz(int rt, int v, int &l, int &r) {
if(!rt) { l = r = 0; AC; }
if(siz[ls(rt)] + 1 <= v) {
l = rt;
splitsiz(rs(l), v - siz[ls(rt)] - 1, rs(l), r);
push_up(l);
} else {
r = rt;
splitsiz(ls(r), v, l, ls(r));
push_up(r);
}
}
public:
void change(int k, int v) {
int l, r, mid, m;
if(a[k]) {
split(rt, a[k], l, r);
split(l, a[k] - 1, l, mid);
splitsiz(mid, 1, m, mid);
l = merge(l, mid);
rt = merge(l, r);
}
a[k] = v;
if(a[k]) {
mid = add(a[k]);
split(rt, v, l, r);
l = merge(l, mid);
rt = merge(l, r);
}
}
ll query(int v) {
int l, r;
split(rt, v, l, r);
ll res = sum[l] + 1ll * siz[r] * v;
rt = merge(l, r);
return res;
}
} ds;
void ACehomoxue() {
cin >> n >> m;
while(m--) {
char op;
cin >> op;
if(op == 'U') {
int k, a;
cin >> k >> a;
ds.change(k, a);
} else {
int c, s;
cin >> c >> s;
if(1ll * c * s <= ds.query(s)) cout << "TAK";
else cout << "NIE"; el;
}
}
}
线段树
lxl 说过,当你不会做时,先把修改操作去掉想。这确实是个不错的技巧。
P7735 [NOI2021] 轻重边
思路
这是一道 trick 题。
考虑每次给一条路径设置成重边是将路径上的点染色,且每次颜色不同。那么对于一条边,如果两个端点的颜色相同就是重边,否则就是轻边。
这个可以树剖线段树维护,只不过注意一下合并两个区间是有左右顺序的,并且线段树的 query() 最好用结构体。反正就是一些细节了,类似P2486。
代码
const int mod = 998244353, maxn = 1e5 + 18;
int n, m, cnt;
vector <int> vec[maxn];
struct node {
int l, r, ls, rs, v, tag;
node(int L = 0, int R = 0, int LS = 0, int RS = 0, int VAL = 0, int TAG = 0) { l = L, r = R, ls = LS, rs = RS, v = VAL, tag = TAG; }
} ;
node merge(node u, node v) {
if(u.l == 0 && u.r == 0) return v;
if(v.l == 0 && v.r == 0) return u;
return node(u.l, v.r, u.ls, v.rs, u.v + v.v + (u.rs == v.ls && u.rs != 0));
}
node rev(node a) { return node(a.r, a.l, a.rs, a.ls, a.v, a.tag); }
class xds {
private:
node t[maxn << 2];
void push_down(int i) {
if(!t[i].tag) AC;
t[i * 2].tag = t[i * 2 + 1].tag = t[i].tag;
t[i * 2].ls = t[i * 2].rs = t[i * 2 + 1].ls = t[i * 2 + 1].rs = t[i].tag;
t[i * 2].v = t[i * 2].r - t[i * 2].l, t[i * 2 + 1].v = t[i * 2 + 1].r - t[i * 2 + 1].l;
t[i].tag = 0;
}
void push_up(int i) { t[i] = merge(t[i * 2], t[i * 2 + 1]); }
public:
void build(int i, int l, int r) {
t[i] = node(l, r);
if(l == r) AC;
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
push_up(i);
}
void updata(int i, int l, int r, int x) {
if(l > r) swap(l, r);
if(t[i].l >= l && t[i].r <= r) {
t[i].tag = x;
t[i].ls = t[i].rs = x;
t[i].v = t[i].r - t[i].l;
AC;
}
push_down(i);
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(l <= mid) updata(i * 2, l, r, x);
if(r > mid) updata(i * 2 + 1, l, r, x);
push_up(i);
}
node query(int i, int l, int r) {
bool re = false; node res = node();
if(l > r) swap(l, r), re = true;
if(t[i].l >= l && t[i].r <= r) res = t[i];
else {
push_down(i);
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(r <= mid) res = query(i * 2, l, r);
else if(l > mid) res = query(i * 2 + 1, l, r);
else res = merge(query(i * 2, l, r), query(i * 2 + 1, l, r));
}
return re ? rev(res) : res;
}
} ;
class tree {
private:
xds ds;
int in[maxn], out[maxn], head[maxn], fa[maxn], siz[maxn], dep[maxn], son[maxn], dfn;
void dfs1(int x, int f) {
fa[x] = f;
dep[x] = dep[f] + 1;
siz[x] = 1;
for(auto to : vec[x]) {
if(to == f) continue;
dfs1(to, x);
siz[x] += siz[to];
if(siz[to] > siz[son[x]]) son[x] = to;
}
}
void dfs2(int x, int f) {
in[x] = ++dfn;
if(son[f] != x) head[x] = x;
else head[x] = head[f];
if(son[x]) dfs2(son[x], x);
for(auto to : vec[x]) if(to != f && to != son[x]) dfs2(to, x);
out[x] = dfn;
}
public:
void init() {
memset(in, 0, sizeof(in));
memset(fa, 0, sizeof(fa));
memset(out, 0, sizeof(out));
memset(siz, 0, sizeof(siz));
memset(dep, 0, sizeof(dep));
memset(son, 0, sizeof(son));
memset(head, 0, sizeof(head));
dfn = cnt = 0;
ds.build(1, 1, n);
dfs1(1, 1);
dfs2(1, 1);
}
void updata(int u, int v, int x) {
while(head[u] != head[v]) {
if(dep[head[u]] > dep[head[v]]) swap(u, v);
ds.updata(1, in[v], in[head[v]], x);
v = fa[head[v]];
}
ds.updata(1, in[u], in[v], x);
}
int query(int u, int v) {
node resu = node(), resv = node();
while(head[u] != head[v]) {
if(dep[head[u]] > dep[head[v]]) {
resu = merge(resu, ds.query(1, in[u], in[head[u]]));
u = fa[head[u]];
} else {
resv = merge(ds.query(1, in[head[v]], in[v]), resv);
v = fa[head[v]];
}
}
return merge(resu, merge(ds.query(1, in[u], in[v]), resv)).v;
}
} s;
void ACehomoxue() {
cin >> n >> m;
for(int i = 0; i <= n; i++) vec[i].clear();
for(int i = 1, u, v; i < n; i++) {
cin >> u >> v;
vec[u].push_back(v);
vec[v].push_back(u);
}
s.init();
while(m--) {
int opt, u, v;
cin >> opt >> u >> v;
if(opt == 1) s.updata(u, v, ++cnt);
else cout << s.query(u, v), el;
}
}
P5278 算术天才⑨与等差数列
trick
这道题和下道题主要介绍一种trick,即是用线段树搭配平衡树(一般用set&map,但是我爱fhqtreap)进行区间判重。
记 \(pre_i\) 表示上一个值和 \(i\) 相同的位置。在带修的情况下,使用平衡树是好维护的。我们可以对于每个值开一个 set 或者手写的平衡树,方便快速求前驱。有的时候值是很大的需要开 map 存。对于区间 \([l, r]\),若其中没有重复的数,显然有:
这个在带修的情况下使用线段树是好维护的,每次更改好在线段树上更新以下所修改的点和它的后继即可,即下一个和他值相同的点。
于是我们就会了使用线段树和平衡树维护区间是否又重复的数。
思路
对于一个区间 \([l, r]\) 和公差 \(k\),题目中的条件可以转化为:
-
没有重复的数。
-
$ k \mid \gcd( \mid a_l-a_{l + 1} \mid, \mid a_{l + 1}-a_{l + 2} \mid, \dots, \mid a_{r -1}-a_{r} \mid ) $ 很好理解。
-
设区间最大数为 \(a\),最小值为 \(b\),那么 \(a - b = k \times (r - l)\),否则可能会出现漏了一项。
这三个都是线段树可以维护的。做完了。
代码
const int mod = 998244353, maxn = 3 * 1e5 + 18;
int n, a[maxn], pre[maxn], q, cnt = 0;
struct tree {
int l, r, pre, v, mnv, mxv;
tree(int L = 0, int R = 0, int PRE = 0, int V = 0, int MN = 0, int MX = 0) { l = L, r = R, pre = PRE, v = V, mnv = MN, mxv = MX; }
};
tree merge(tree u, tree v) {
if(u.l == 0 && u.r == 0) return v;
if(v.l == 0 && v.r == 0) return u;
return tree(u.l, v.r, max(u.pre, v.pre), __gcd(u.v, v.v), min(u.mnv, v.mnv), max(u.mxv, v.mxv));
}
class xds {
tree t[maxn << 2];
void push_up(int i) { t[i] = merge(t[i * 2], t[i * 2 + 1]); }
public:
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r;
if(l == r) {
t[i].v = abs(a[l] - a[l - 1]);
t[i].mnv = t[i].mxv = a[l];
t[i].pre = pre[l];
AC;
}
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
push_up(i);
}
void updata(int i, int p) {
if(t[i].l == p && t[i].r == p) {
t[i].v = abs(a[p] - a[p - 1]);
t[i].mnv = t[i].mxv = a[p];
t[i].pre = pre[p];
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) updata(i * 2, p);
else updata(i * 2 + 1, p);
push_up(i);
}
tree query(int i, int l, int r) {
if(t[i].l >= l && t[i].r <= r) return t[i];
int mid = t[i].l + (t[i].r - t[i].l) / 2; tree res = tree();
if(l <= mid) res = merge(query(i * 2, l, r), res);
if(r > mid) res = merge(res, query(i * 2 + 1, l, r));
return res;
}
} ds;
int ch[maxn][2], rnd[maxn], tot, siz[maxn], rt[maxn], mn[maxn], mx[maxn];
int add(int x) {
tot++;
rnd[tot] = rand();
ls(tot) = rs(tot) = 0;
mn[tot] = mx[tot] = x;
siz[tot] = 1;
return tot;
}
void push_up(int i) { siz[i] = siz[ls(i)] + siz[rs(i)] + 1; mn[i] = min(i, min(mn[ls(i)], mn[rs(i)])); mx[i] = max(i, max(mx[ls(i)], mx[rs(i)])); }
void split(int rt, int v, int &l, int &r) {
if(rt == 0) { l = r = 0; AC; }
if(rt <= v) {
l = rt;
split(rs(l), v, rs(l), r);
push_up(l);
} else {
r = rt;
split(ls(r), v, l, ls(r));
push_up(r);
}
}
int merge(int l, int r) {
if(l * r == 0) return l ^ r;
int res;
if(rnd[l] < rnd[r]) {
res = l;
rs(l) = merge(rs(l), r);
} else {
res = r;
ls(r) = merge(l, ls(r));
}
push_up(res);
return res;
}
unordered_map <int, int> mp;
void prepare() {
for(int i = 1; i <= n; i++) if(add(i) != i) debug("warning");
mn[0] = 1e9, mx[0] = 0;
for(int i = 1; i <= n; i++) {
int rt = mp[a[i]], l, r;
split(rt, i, l, r);
pre[i] = mx[l];
l = merge(l, i);
mp[a[i]] = merge(l, r);
}
ds.build(1, 1, n);
}
void del(int x) {
int l, r, mid;
split(mp[a[x]], x - 1, l, r);
split(r, x, mid, r);
if(mid != x) debug("error");
if(mn[r] <= n) { pre[mn[r]] = mx[l]; ds.updata(1, mn[r]); }
mp[a[x]] = merge(l, r);
}
void ins(int x) {
int l, r;
split(mp[a[x]], x, l, r);
pre[x] = mx[l]; ds.updata(1, x);
if(mn[r] <= n) { pre[mn[r]] = x; ds.updata(1, mn[r]); }
r = merge(x, r);
mp[a[x]] = merge(l, r);
}
bool check(int l, int r, int k) {
if(r - l == 0) return true;
tree res = ds.query(1, l, r);
if((res.mxv - res.mnv) != 1ll * (r - l) * k) return false;
if(k == 0) return true;
if(res.pre >= l) return false;
if(ds.query(1, l + 1, r).v % k != 0) return false;
return true;
}
void ACehomoxue() {
cin >> n >> q;
for(int i = 1; i <= n; i++) cin >> a[i];
prepare(); cnt = 0;
while(q--) {
int opt;
cin >> opt;
if(opt == 1) {
int x, y;
cin >> x >> y;
x ^= cnt, y ^= cnt;
del(x);
a[x] = y;
ins(x);
if(x < n) ds.updata(1, x + 1);
} else {
int l, r, k;
cin >> l >> r >> k;
l ^= cnt, r ^= cnt, k ^= cnt;
if(check(l, r, k)) cnt++, Ys, el;
else No, el;
}
}
}
P6617 查找 Search
思路
维护区间内有没有 \(w - a_i\)。和上面提到的 trick 是类似的。
需要注意的是,每次改一个值也要更新其后继,而这道题的话后继是由多个的。有一个转化,就是如果一个数的前驱比它前面第一个与他相同的位置要小,则我们直接把这个位置的前驱设为 0。这样可以发现后继只有 3 个。
代码
由于数据过水,我没加优化暴力修改多交了几发也过了。所以下面的代码严格来说并非正解,但正确性是对的,仅供参考。
const int mod = 998244353, maxn = 5 * 1e5 + 18;
mt19937 rd(time(0));
int n, m, w, a[maxn], cnt;
class fhqtreap {
private:
int ch[maxn][2], rnd[maxn], siz[maxn];
unordered_map <int, int> rt;
inline int add(int x) {
ls(x) = rs(x) = 0;
rnd[x] = rd();
siz[x] = 1;
return x;
}
void push_up(int i) { siz[i] = siz[ls(i)] + siz[rs(i)] + 1; }
void split(int rt, int v, int &l, int &r) {
if(rt == 0) { l = r = 0; AC; }
if(rt <= v) {
l = rt;
split(rs(l), v, rs(l), r);
push_up(l);
} else {
r = rt;
split(ls(r), v, l, ls(r));
push_up(r);
}
}
void splitsiz(int rt, int v, int &l, int &r) {
if(rt == 0) { l = r = 0; AC; }
if(siz[ls(rt)] + 1 <= v) {
l = rt;
splitsiz(rs(l), v - siz[ls(rt)] - 1, rs(l), r);
push_up(l);
} else {
r = rt;
splitsiz(ls(r), v, l, ls(r));
push_up(r);
}
}
inline int merge(int l, int r) {
if(l * r == 0) return l + r;
int res;
if(rnd[l] < rnd[r]) {
res = l;
rs(l) = merge(rs(l), r);
} else {
res = r;
ls(r) = merge(l, ls(r));
}
push_up(res);
return res;
}
void dfs(int x, vector <int> &vec) {
if(!x) AC;
vec.push_back(x);
dfs(ls(x), vec), dfs(rs(x), vec);
}
public:
void init() {
rt.clear();
for(int i = 1; i <= n; i++) add(i);
}
void collect(int x, vector <int> &vec) {
int y, l, r, mid, t, res;
split(rt[a[x]], x, l, r);
splitsiz(r, 1, mid, r);
y = mid == 0 ? n + 1 : mid;
debug(y);
r = merge(mid, r); rt[a[x]] = merge(l, r);
t = rt[w - a[x]];
split(t, x, l, r);
split(r, y - 1, mid, r);
vec.clear();
dfs(mid, vec);
r = merge(mid, r);
rt[w - a[x]] = merge(l, r);
}
void del(int x) {
int l, r, mid;
split(rt[a[x]], x - 1, l, r);
split(r, x, mid, r);
rt[a[x]] = merge(l, r);
}
void ins(int x) {
int l, r;
split(rt[a[x]], x - 1, l, r);
l = merge(l, x);
rt[a[x]] = merge(l, r);
}
inline int query(int x, int v) {
int l, mid, r, res;
split(rt[v], x - 1, l, r);
splitsiz(l, siz[l] - 1, l, mid);
res = mid;
l = merge(l, mid);
rt[v] = merge(l, r);
return res;
}
} s;
class xds {
private:
struct tree {
int l, r, v;
} t[maxn << 2];
void push_up(int i) { t[i].v = max(t[i * 2].v, t[i * 2 + 1].v); }
public:
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r;
if(l == r) {
t[i].v = s.query(l, w - a[l]);
AC;
}
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
push_up(i);
}
void updata(int i, int p, int x = -1) {
if(t[i].l == p && t[i].r == p) {
t[i].v = x == -1 ? s.query(p, w - a[p]) : x;
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) updata(i * 2, p, x);
else updata(i * 2 + 1, p, x);
push_up(i);
}
inline int query(int i, int l, int r) {
if(t[i].l >= l && t[i].r <= r) return t[i].v;
int mid = t[i].l + (t[i].r - t[i].l) / 2, res = 0;
if(l <= mid) res = max(res, query(i * 2, l, r));
if(r > mid) res = max(res, query(i * 2 + 1, l, r));
return res;
}
void output(int i = 1) {
if(t[i].l == t[i].r) {
cout << t[i].l << ':' << t[i].v; el;
AC;
}
output(i * 2), output(i * 2 + 1);
}
} ds;
vector <int> vec;
void ACehomoxue() {
cin >> n >> m >> w;
for(int i = 1; i <= n; i++) cin >> a[i];
s.init();
for(int i = 1; i <= n; i++) s.ins(i);
ds.build(1, 1, n);
while(m--) {
int opt;
cin >> opt;
if(opt == 2) {
int l, r;
cin >> l >> r;
l ^= cnt, r ^= cnt;
if(ds.query(1, l, r) >= l) Ys, cnt++;
else No; el;
} else {
int p, v;
cin >> p >> v;
s.collect(p, vec);
s.del(p);
a[p] = v;
s.ins(p);
ds.updata(1, p);
for(auto x : vec) ds.updata(1, x);
s.collect(p, vec);
for(auto x : vec) ds.updata(1, x);
}
// ds.output();
}
}
P3401 洛谷树
思路
看到亦或什么的二进制拆位是大概率,尤其是在这里 \(w < 1024\) 的情况下。
我们先考虑是序列的情况。由于对于每一位只有 \(0\) 或 \(1\) 两种取值,所以我们可以分别维护 \(pre_{0/1}\)、\(suf_{0/1}\) 和 \(v_{0/1}\),分别代表两种取值的作为前缀、后缀和区间亦或和的方案数,再计一个区间亦或和。我们发现这样子的 push_up() 是简单的。
由于题目上是树,所以可以把边权转化为儿子点权然后树链剖分即可。
有几个细节需要注意。当查询 \(u\) 和 \(v\) 我们不能查到两个点的 lca,而是应该查到 lca 的儿子就结束,因为点权表示的是自己到父亲的边的边权,如果把 lca 的点权算进去显然是不对的。像 P5278 一样,由于存了前后缀的信息,合并是有前后方向性的,需要注意。
感觉讲的一坨。
代码
const int mod = 998244353, maxn = 3 * 1e4 + 18;
int n, q, w[maxn], fa[maxn], pos[maxn];
vector <int> vec[maxn];
struct edge {
int u, v, w;
edge(int U = 0, int V = 0, int W = 0) { u = U, v = V, w = W; }
} ;
vector <edge> e;
struct tree {
int l, r, pre[2], suf[2], v[2], sum;
tree(int L = 0, int R = 0, int pre0 = 0, int pre1 = 0, int suf0 = 0, int suf1 = 0, int v0 = 0, int v1 = 0, int s = 0) {
l = L, r = R, pre[0] = pre0, pre[1] = pre1, suf[0] = suf0, suf[1] = suf1, sum = s, v[0] = v0, v[1] = v1;
}
} ;
tree rev(tree x) { return tree(x.r, x.l, x.suf[0], x.suf[1], x.pre[0], x.pre[1], x.v[0], x.v[1], x.sum); }
tree merge(tree l, tree r) {
if(l.l == 0 && l.r == 0) return r;
if(r.l == 0 && r.r == 0) return l;
tree res = tree();
res.l = l.l, res.r = r.r, res.sum = l.sum ^ r.sum;
res.pre[0] = l.pre[0], res.pre[1] = l.pre[1], res.suf[0] = r.suf[0], res.suf[1] = r.suf[1];
res.pre[l.sum ^ 0] += r.pre[0], res.pre[l.sum ^ 1] += r.pre[1];
res.suf[r.sum ^ 0] += l.suf[0], res.suf[r.sum ^ 1] += l.suf[1];
res.v[0] = l.v[0] + r.v[0], res.v[1] = l.v[1] + r.v[1];
res.v[0] += l.suf[0] * r.pre[0] + l.suf[1] * r.pre[1];
res.v[1] += l.suf[1] * r.pre[0] + l.suf[0] * r.pre[1];
return res;
}
tree buildt(int p, int k) {
tree res = tree();
res.l = res.r = p;
int t = (w[pos[p]] >> k) & 1;
res.pre[t] = res.suf[t] = res.v[t] = 1;
res.sum = t;
return res;
}
class xds {
private:
tree t[maxn << 2];
int K;
void push_up(int i) { t[i] = merge(t[i * 2], t[i * 2 + 1]); }
public:
void build(int i, int l, int r, int k) {
K = k;
if(l == r) {
t[i] = buildt(l, K);
AC;
}
int mid = l + (r - l) / 2;
build(i * 2, l, mid, K);
build(i * 2 + 1, mid + 1, r, K);
push_up(i);
}
void updata(int i, int p) {
if(t[i].l == p && t[i].r == p) {
t[i] = buildt(p, K);
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) updata(i * 2, p);
else updata(i * 2 + 1, p);
push_up(i);
}
tree query(int i, int l, int r) {
int re = false;
if(l > r) swap(l, r), re = true;
if(t[i].l >= l && t[i].r <= r) return t[i];
int mid = t[i].l + (t[i].r - t[i].l) / 2; tree res = tree();
if(l <= mid) res = merge(query(i * 2, l, r), res);
if(r > mid) res = merge(res, query(i * 2 + 1, l, r));
return re ? rev(res) : res;
}
void output(int i) {
if(t[i].l == t[i].r) {
debug(pos[t[i].l]);
debug(t[i].sum);
AC;
}
output(i * 2), output(i * 2 + 1);
}
} ;
class TREE {
private:
xds ds[10];
int son[maxn], in[maxn], dfn, out[maxn], head[maxn], siz[maxn], dep[maxn];
void dfs1(int x, int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = x == 1 ? 1 : dep[f] + 1;
son[x] = 0;
for(auto to : vec[x]) {
if(to == f) continue;
dfs1(to, x);
siz[x] += siz[to];
if(siz[to] > siz[son[x]]) son[x] = to;
}
}
void dfs2(int x) {
in[x] = ++dfn;
pos[dfn] = x;
if(son[fa[x]] == x && x != 1) head[x] = head[fa[x]];
else head[x] = x;
if(son[x]) dfs2(son[x]);
for(auto to : vec[x]) {
if(to == fa[x] || to == son[x]) continue;
dfs2(to);
}
out[x] = dfn;
}
public:
void build() {
dfn = 0;
dfs1(1, 1);
dfs2(1);
for(auto tmp : e) {
int u = tmp.u, v = tmp.v;
if(fa[u] == v) w[u] = tmp.w;
else w[v] = tmp.w;
}
for(int i = 0; i < 10; i++) ds[i].build(1, 1, n, i);
}
void updata(int u, int v, int x) {
int p;
if(fa[u] == v) p = u;
else p = v;
w[p] = x;
for(int i = 0; i < 10; i++) ds[i].updata(1, in[p]);
}
int query(int uu, int vv) {
int ans = 0; tree resu, resv, res;
for(int k = 0, u, v; k < 10; k++) {
u = uu, v = vv;
resu = resv = res = tree();
while(head[u] != head[v]) {
if(dep[head[u]] > dep[head[v]]) {
resu = merge(resu, ds[k].query(1, in[u], in[head[u]]));
u = fa[head[u]];
} else {
resv = merge(ds[k].query(1, in[head[v]], in[v]), resv);
v = fa[head[v]];
}
}
if(in[u] == in[v]) res = tree();
if(dep[u] < dep[v]) res = ds[k].query(1, in[u] + 1, in[v]);
if(dep[v] < dep[u]) res = ds[k].query(1, in[u], in[v] + 1);
res = merge(merge(resu, res), resv);
ans += res.v[1] * (1 << k);
}
return ans;
}
void output() {
debug("_---------------------");
for(int k = 0; k < 10; k++) {
cout << k << ':'; el;
ds[k].output(1);
debug(ds[k].query(1, 1, n).v[1]);
}
}
} s;
void ACehomoxue() {
cin >> n >> q;
for(int i = 1, u, v, w; i < n; i++) {
cin >> u >> v >> w;
vec[u].push_back(v);
vec[v].push_back(u);
e.push_back(edge(u, v, w));
}
s.build();
while(q--) {
int opt;
cin >> opt;
if(opt == 1) {
int u, v;
cin >> u >> v;
cout << s.query(u, v);
el;
} else {
int u, v, w;
cin >> u >> v >> w;
s.updata(u, v, w);
}
// s.output();
}
}
P8990 [北大集训 2021] 小明的树
前面的题码量太大了来到小的。
思路
很巧妙的转换呢。
设亮了灯的点为白点,没亮的为黑点。对于一个边,两端点都黑为黑边,两端点都白为白边,各一个为黑白边。
我们发现如果白连通块全部是一整个子树的话,此时只存在一个黑连通块。当只有一个黑连通块的时候,白连通块的个数显然为黑白边的数量。显然,黑连通块的数量 = 黑点数 - 黑边数。注意到这些其实已经做完了。
我们可以维护一个时间轴线段树,分别维护区间最小黑联通数量与黑连通块最小的时候的黑白边个数之和。因为根结点永远为黑,所以黑连通个数至少为一,所以为护最小黑连通块的个数是正确的。关于具体维护黑连通块个数的方法,假设叶子节点表示在时间轴上位置为 \(i\),我们可以赋初值 \(n - i\),即此时黑点的数量,多一条黑边直接区间减即可。维护黑白边的方法同理,不过初值直接赋值成 \(0\) 即可。
考虑修改。假设我们加了一条边,两个点被点亮的时间分别为 \(l\) 和 \(r\),那么在 \([1, l - 1]\) 的时间段内显然会增加一个黑边,\([l, r - 1]\) 会增加一条黑白边,区间加减即可。删除一条边直接反着来就行。
代码
#define int ll
#define ll long long
const int mod = 998244353, maxn = 5 * 1e5 + 18;
int n, q, t[maxn];
class xds {
private:
struct tree {
int l, r, b, tb, bw, tbw, cbw;
} t[maxn << 2];
void push_up(int i) {
t[i].b = min(t[i * 2].b , t[i * 2 + 1].b);
t[i].cbw = 0, t[i].bw = 0;
if(t[i].b == t[i * 2].b) t[i].cbw += t[i * 2].cbw, t[i].bw += t[i * 2].bw;
if(t[i].b == t[i * 2 + 1].b) t[i].cbw += t[i * 2 + 1].cbw, t[i].bw += t[i * 2 + 1].bw;
}
void push_down(int i) {
if(t[i].tb != 0) {
t[i * 2].tb += t[i].tb;
t[i * 2 + 1].tb += t[i].tb;
t[i * 2].b += t[i].tb;
t[i * 2 + 1].b += t[i].tb;
t[i].tb = 0;
}
if(t[i].tbw != 0) {
t[i * 2].tbw += t[i].tbw;
t[i * 2 + 1].tbw += t[i].tbw;
t[i * 2].bw += t[i].tbw * t[i * 2].cbw;
t[i * 2 + 1].bw += t[i].tbw * t[i * 2 + 1].cbw;
t[i].tbw = 0;
}
}
public:
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r, t[i].tb = t[i].tbw = t[i].bw = 0;
if(l == r) {
if(l == n) t[i].b = 1e9;
else {
t[i].cbw = 1;
t[i].b = n - l;
t[i].bw = 0;
}
AC;
}
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
push_up(i);
}
void updata(int i, int l, int r, int x, int y) {
if(l > r) AC;
if(t[i].l >= l && t[i].r <= r) {
t[i].tb += x;
t[i].b += x;
t[i].tbw += y;
t[i].bw += t[i].cbw * y;
AC;
}
push_down(i);
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(l <= mid) updata(i * 2, l, r, x, y);
if(r > mid) updata(i * 2 + 1, l, r, x, y);
push_up(i);
}
int query() { return t[1].b == 1 ? t[1].bw : 0; }
} ds;
void addedge(int l, int r, int x) {
l = t[l], r = t[r];
if(l > r) swap(l, r);
ds.updata(1, 1, l - 1, -x, 0);
ds.updata(1, l, r - 1, 0, x);
}
vector < pair <int, int> > e;
void ACehomoxue() {
cin >> n >> q;
for(int i = 1, u, v; i < n; i++) {
cin >> u >> v;
e.push_back({u, v});
}
for(int i = 1, x; i < n; i++) {
cin >> x;
t[x] = i;
} t[1] = n;
ds.build(1, 1, n - 1);
for(auto tmp : e) addedge(tmp.first, tmp.second, 1);
cout << ds.query(), el;
while(q--) {
int u1, v1, u2, v2;
cin >> u1 >> v1 >> u2 >> v2;
addedge(u1, v1, -1);
addedge(u2, v2, 1);
cout << ds.query(), el;
}
}
主席树
P2839 [国家集训队] middle
这是一道 trick 题。
trick
像这类有关中位数的题,不妨枚举中位数,将大于等于中位数的数设为 \(1\),小于的设为 \(-1\),再进行一些分析。
思路
利用上面的 trick。
我们考虑对答案二分。每次二分到一个中位数,先利用 trick 将序列转化,然后求出 \([a, b]\) 的后缀最大值、\((b,c)\) 的和还有 \([c, d]\) 的前缀最大值。这三个值的和如果大于等于 \(0\),说明中位数还可以变大,否则中位数应该更小。
我们不可能每次都暴力算一遍经过 trick 转化后的数组,那么我们可以预处理出来。我们知道和、前缀最大值和后缀最小值都是线段树很好维护的,那么最朴素的想法就是对每个可能的中位数(即数组中的所有数)都开一个线段树,但是存不下复杂度也不对,所以使用主席树维护。
代码
const int mod = 998244353, maxn = 2 * 1e4 + 18;
int n, q, a[maxn], v[maxn];
struct tree {
int l, r, sum, pre, suf;
tree(int L = 0, int R = 0, int S = 0, int Pr = 0, int Sf = 0) { l = L, r = R, sum = S, pre = Pr, suf = Sf; }
} ;
tree merge(tree l, tree r) {
if(l.l == 0 && l.r == 0) return r;
if(r.l == 0 && r.r == 0) return l;
return tree(l.l, r.r, l.sum + r.sum, max(l.pre, l.sum + r.pre), max(r.suf, r.sum + l.suf));
}
class xds {
private:
tree t[maxn << 7];
int ch[maxn << 7][2], tot;
void build(int &i, int l, int r) {
i = ++tot, t[i] = tree();
t[i].l = l, t[i].r = r;
if(l == r) {
t[i].pre = t[i].suf = t[i].sum = v[l];
// debug(v[l]);
AC;
}
int mid = l + (r - l) / 2;
build(ls(i), l, mid);
build(rs(i), mid + 1, r);
push_up(i);
}
void push_up(int i) { t[i] = merge(t[ls(i)], t[rs(i)]); }
public:
void init(int &rt) {
tot = 0;
build(rt, 1, n);
}
void updata(int &i, int ii, int p, int x) {
i = ++tot; t[i] = t[ii];
if(t[i].l == t[i].r) {
t[i].sum = t[i].pre = t[i].suf = x;
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) updata(ls(i), ls(ii), p, x), rs(i) = rs(ii);
else updata(rs(i), rs(ii), p, x), ls(i) = ls(ii);
push_up(i);
}
tree query(int i, int l, int r) {
if(t[i].l >= l && t[i].r <= r) return t[i];
int mid = t[i].l + (t[i].r - t[i].l) / 2; tree res = tree();
if(l <= mid) res = merge(query(ls(i), l, r), res);
if(r > mid) res = merge(res, query(rs(i), l, r));
return res;
}
void output(int i) {
if(t[i].l == t[i].r) cout << t[i].sum << ' ';
else output(ls(i)), output(rs(i));
if(t[i].l == 1 && t[i].r == n) el;
}
} ds;
int cnt = 0, pos[maxn], rt[maxn];
map <int, vector <int> > mp;
vector <int> vec;
bool check(int a, int b, int c, int d, int i) {
int suf = ds.query(rt[i], a, b).suf, pre = ds.query(rt[i], c, d).pre, sum = b + 1 <= c - 1 ? ds.query(rt[i], b + 1, c - 1).sum : 0;
// debug(i), debug(suf), debug(pre);
if(suf + pre + sum >= 0) return true;
else return false;
}
void ACehomoxue() {
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> a[i];
v[i] = 1;
mp[a[i]].push_back(i);
}
int lst = 0;
for(auto tmp : mp) {
int i = tmp.first;
pos[++cnt] = i;
rt[cnt] = 0;
if(lst == 0) {
ds.init(rt[cnt]);
lst = i;
continue;
}
rt[cnt] = rt[cnt - 1];
for(auto x : mp[lst]) ds.updata(rt[cnt], rt[cnt], x, -1);
lst = i;
}
mp.clear();
cin >> q;
lst = 0;
while(q--) {
int a, b, c, d;
vec.clear();
for(int i = 1, x; i <= 4; i++) {
cin >> x;
vec.push_back((x + lst) % n + 1);
}
sort(vec.begin(), vec.end());
a = vec[0], b = vec[1], c = vec[2], d = vec[3];
// debug(a), debug(b), debug(c), debug(d);
int l = 1, r = cnt, ans = 0;
while(l <= r) {
int mid = l + (r - l) / 2;
if(check(a, b, c, d, mid)) {
ans = mid;
l = mid + 1;
} else r = mid - 1;
}
lst = pos[ans];
cout << lst, el;
}
}
树上启发式合并
又名 dsu on tree,可以平替许多淀粉质、线段树合并等的题,是 llj 推荐的不错的算法。
P10241 [THUSC 2021] 白兰地厅的西瓜
思路
两次 dsu on tree。
第一次维护从子树开始最长上升子序列到子树根(子树根要选)的最长上升子序列。分别开两个线段树优化,类比序列上的即可。
第二次计算答案。每次 dfs 到一个子树就算子树内到的点作为起点到子树外的点作为终点。所以还要维护一个子树外的数据结构,支持删除值(单点)并维护区间最大值。考虑线段树叶子节点开个平衡树即可。
剩下的就是 dsu on tree 板子。
代码
正解的还没写完。
这题其实有个乱搞,数据过水所以就算不算轻儿子间的贡献就能过。
const int mod = 998244353, maxn = 1e5 + 18;
int n, a[maxn];
map <int, int> mp;
int idx;
class xds {
private:
struct tree {
int l, r, v;
} t[maxn << 2];
void push_up(int i) { t[i].v = max(t[i * 2].v, t[i * 2 + 1].v); }
public:
void build(int i, int l, int r) {
t[i].l = l, t[i].r = r, t[i].v = 0;
if(l == r) AC;
int mid = l + (r - l) / 2;
build(i * 2, l, mid);
build(i * 2 + 1, mid + 1, r);
push_up(i);
}
void updata(int i, int p, int x) {
if(t[i].l == p && p == t[i].r) {
t[i].v = max(t[i].v, x);
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) updata(i * 2, p, x);
else updata(i * 2 + 1, p, x);
push_up(i);
}
void del(int i, int p) {
if(t[i].l == p && t[i].r == p) {
t[i].v = 0;
AC;
}
int mid = t[i].l + (t[i].r - t[i].l) / 2;
if(p <= mid) del(i * 2, p);
else del(i * 2 + 1, p);
push_up(i);
}
int query(int i, int l, int r) {
if(l > r) AK;
if(t[i].l >= l && t[i].r <= r) return t[i].v;
int mid = t[i].l + (t[i].r - t[i].l) / 2, res = 0;
if(l <= mid) res = max(res, query(i * 2, l, r));
if(r > mid) res = max(res, query(i * 2 + 1, l, r));
return res;
}
} ;
vector <int> vec[maxn];
int dp[maxn][2];
class dsu_on_tree {
private:
xds up, down;
int siz[maxn], in[maxn], out[maxn], dep[maxn], son[maxn], dfn, ans, pos[maxn];
void dfs1(int x, int fa) {
siz[x] = 1, dep[x] = dep[fa] + 1;
son[x] = 0;
for(auto to : vec[x]) {
if(to == fa) continue;
dfs1(to, x);
if(siz[to] > siz[son[x]]) son[x] = to;
siz[x] += siz[to];
}
}
void dfs2(int x, int fa) {
// debug(x);
in[x] = ++dfn;
pos[dfn] = x;
if(son[x]) dfs2(son[x], x);
for(auto to : vec[x]) if(to != fa && to != son[x]) dfs2(to, x);
out[x] = dfn;
}
void getans(int x) { ans = max(ans, max(dp[x][0] + down.query(1, a[x] + 1, idx), dp[x][1] + up.query(1, 1, a[x] - 1))); }
void add(int x) {
up.updata(1, a[x], dp[x][0]);
down.updata(1, a[x], dp[x][1]);
}
void del(int x) {
up.del(1, a[x]);
down.del(1, a[x]);
}
void dfs(int x, int fa, bool keep = true) {
for(auto to : vec[x]) {
if(to == son[x] || to == fa) continue;
dfs(to, x, false);
}
if(son[x]) dfs(son[x], x, true);
int upp = up.query(1, 1, a[x] - 1) + 1, downn = down.query(1, a[x] + 1, idx) + 1;
for(int id = in[x] + 1; id <= out[x]; id++) {
if(id == in[son[x]]) { id = out[son[x]]; continue; }
getans(pos[id]);
if(a[pos[id]] < a[x]) ans = max(ans, dp[pos[id]][0] + downn);
if(a[pos[id]] > a[x]) ans = max(ans, dp[pos[id]][1] + upp);
}
for(int id = in[x] + 1; id <= out[x]; id++) {
if(id == in[son[x]]) { id = out[son[x]]; continue; }
add(pos[id]);
}
dp[x][1] = down.query(1, a[x] + 1, idx) + 1;
// debug(dp[x][1]);
dp[x][0] = up.query(1, 1, a[x] - 1) + 1;
// debug(dp[x][0]);
ans = max(ans, max(dp[x][1], dp[x][0]));
add(x);
if(!keep) for(int i = in[x]; i <= out[x]; i++) del(pos[i]);
}
public:
int solve() {
up.build(1, 1, idx);
down.build(1, 1, idx);
dfn = 0;
dfs1(1, 1);
dfs2(1, 1);
ans = 0;
dfs(1, 1, true);
return ans;
}
} s;
void ACehomoxue() {
cin >> n;
for(int i = 1; i <= n; i++) { cin >> a[i]; mp[a[i]] = 1; }
for(auto &tmp : mp) tmp.second = ++idx;
for(int i = 1; i <= n; i++) a[i] = mp[a[i]];
for(int i = 1, u, v; i < n; i++) {
cin >> u >> v;
vec[u].push_back(v);
vec[v].push_back(u);
}
cout << s.solve(), el;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号