![]()
##完全使用本地权重,识别时根据识别准确率来确定绘制
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import cv2
from torchvision.io.image import read_image
from torchvision.models.detection import FasterRCNN_ResNet50_FPN_V2_Weights
##屏蔽一些恼人的提示
import warnings
warnings.filterwarnings("ignore",category=ResourceWarning)
warnings.filterwarnings("ignore",category=DeprecationWarning)
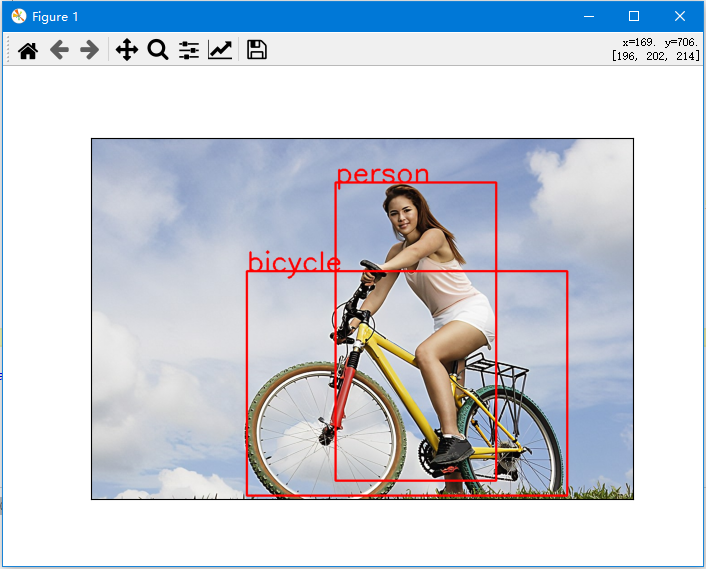
img_path = "./jupyterlab/doc/ccc.jpg" ##骑着自行车的美女,图片随意到哪里下载都行
img = read_image(img_path)##用pytorch提供的io函数
weights_info = FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT
##读本地权重文件,权重文件到pytorch下载
model = torchvision.models.detection.maskrcnn_resnet50_fpn_v2(weights=None, progress=False, weights_backbone=None)
myweights = torch.load('E:/study_2022/working_python/maskrcnn_resnet50_fpn_v2_coco-73cbd019.pth')
model.load_state_dict(myweights)
model.eval()
preprocess = weights_info.transforms()
batch = [preprocess(img)]
prediction = model(batch)[0]
labels = [weights_info.meta["categories"][i] for i in prediction["labels"]]
boxes = [i for i in prediction["boxes"]]
scores = [i for i in prediction["scores"]]
myimg = cv2.imread(img_path)
myimg = cv2.cvtColor(myimg, cv2.COLOR_BGR2RGB)
for i,score in enumerate(scores):
if score.item() < 0.9 : continue##舍弃准确率90%以下的
myimg = cv2.addWeighted(myimg, alpha=0.5, src2=myimg, beta=0.5, gamma=1)
##注意,cv2这里只接受整型坐标值,要将boxes的坐标转成int
start_point = (int(boxes[i][0]), int(boxes[i][1]))
end_point = (int(boxes[i][2]), int(boxes[i][3]))
cv2.rectangle(myimg, start_point, end_point, color = (255,0,0), thickness=3)
cv2.putText(myimg, labels[i], start_point, cv2.FONT_HERSHEY_SIMPLEX, 2, color = (255,0,0), thickness=3)
plt.figure(figsize=(7, 5))
plt.imshow(myimg)
plt.xticks([])
plt.yticks([])
plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号