
nodeEE双写与分布式事务要点一二
数据库与缓存双写问题
计算机领域任何一个问题都可以通过增加一个抽象“层”来解决。
业务中为了减少热点数据不必要的db查询,往往会增加一层缓存来解决I/O性能。可是I/O多了一层也就多了一层的更新维护与容错保障,当修改db中某些数据时,往往会面临缓存更新的问题,在这里简单介绍 数据库与缓存双写问题以及在业务场景如何使用双写策略。
缓存更新时机
缓存在以下情况下需要更新:
- 不存在缓存,回源至db后添加缓存
- 缓存超时,重复上个步骤
- 修改db,更新缓存
缓存更新策略
- 若不存在缓存或者缓存超时:
- 查询db
- 设置缓存
- 若缓存存在,且需要更新db,则有多种缓存更新策略:
- 先更新db,然后更新缓存
- 先删除缓存,然后更新db
- 先更新db,在删除缓存
本节主要讨论更新db时如何更新缓存的问题,且暂时不考虑缓存操作失败的情况(如网络原因、redis服务不可用等)。
如果业务场景中不会出现修改相同数据字段竞争的问题,那么这三种更新策略毫无疑问都可以使用。如果出现缓存竞争态的情况,那么第一种策略是最先排除的:
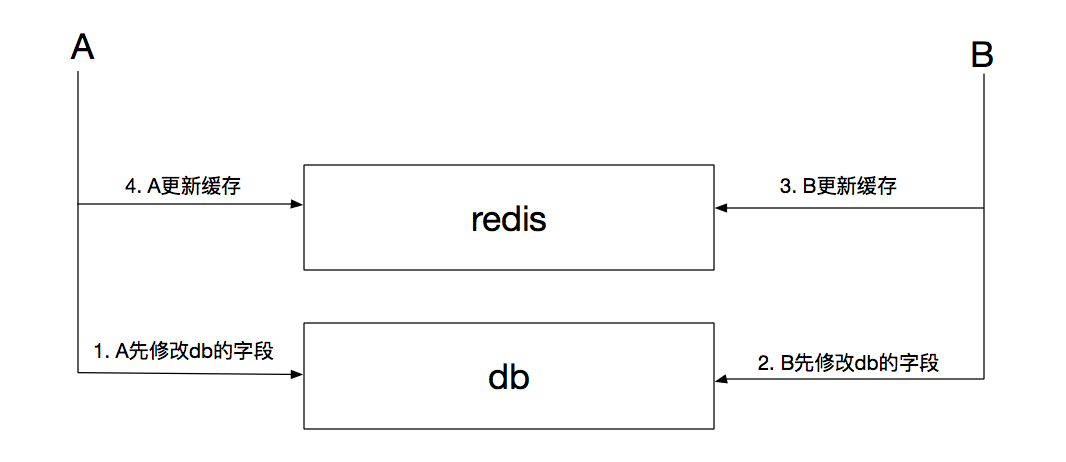
上图所示,如果A、B先后修改db,会出现最终缓存与db不一致的现象,导致随后至缓存超时或下次更新的时间段内使用脏数据的现象。
而且业务方需要考虑的是,是否每次更新db,都需要立即刷新缓存。如果在“写频繁,而读频率远小于写的情况下,频繁的刷新缓存是否有必要?”
第二种策略,先删除缓存再更新数据库旨在牺牲性能下尽可能降低使用脏缓存的情况,可是此种情况下仍有可能出现脏缓存的情况:
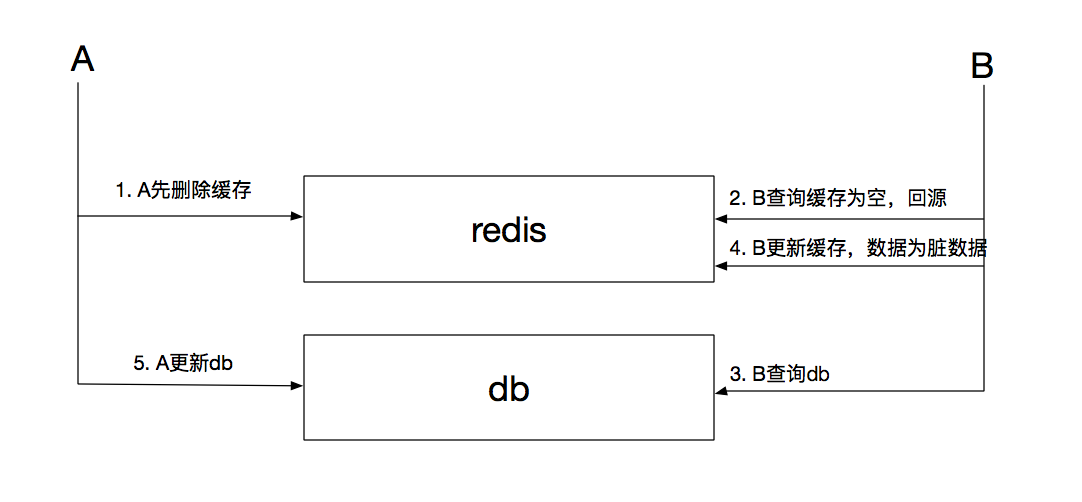
如上图,A先删除缓存,同时开始更新db;与此同时B查询缓存为空,进而查询db,由于db的读性能高于写且数据库隔离级别默认为提交读,因此B查询db的数据往往为旧数据,此后B查询完毕更新缓存,导致缓存在超时时间或者下次修改db的范围内为脏数据。
如果db底层做了读写分离的情况下,这种现象更容易出现,B查询db是读库,而A修改主库后需要一定时间的同步才能保障从库的数据最新,因此在此种情况下,缓存肯定仍是脏数据。
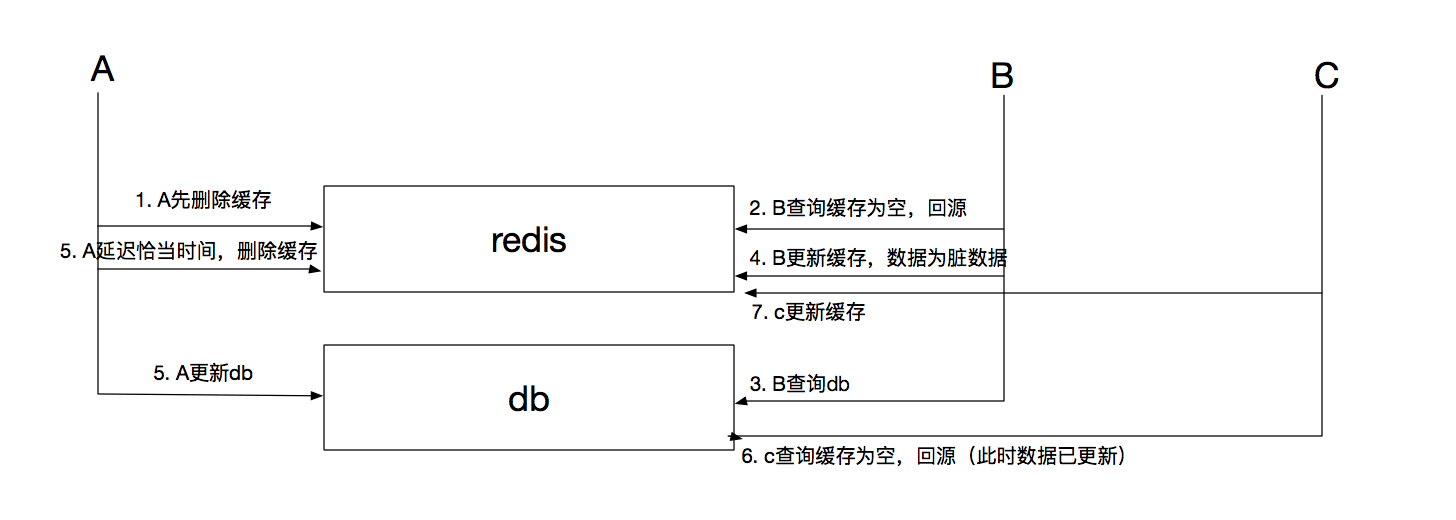
为了避免这种情况,A可以在更新db后延时一定间隔(往往是查询db时间+设置缓存的时间)删除缓存,尽量缩短脏缓存的时段,新的请求回源db并设置新的缓存数据。如下图所示。
第三种策略先更新数据库再删除缓存,此种策略较为安全,几乎不会出现脏缓存的情况,就算出现也是会在极不合理的情况下导致脏缓存:
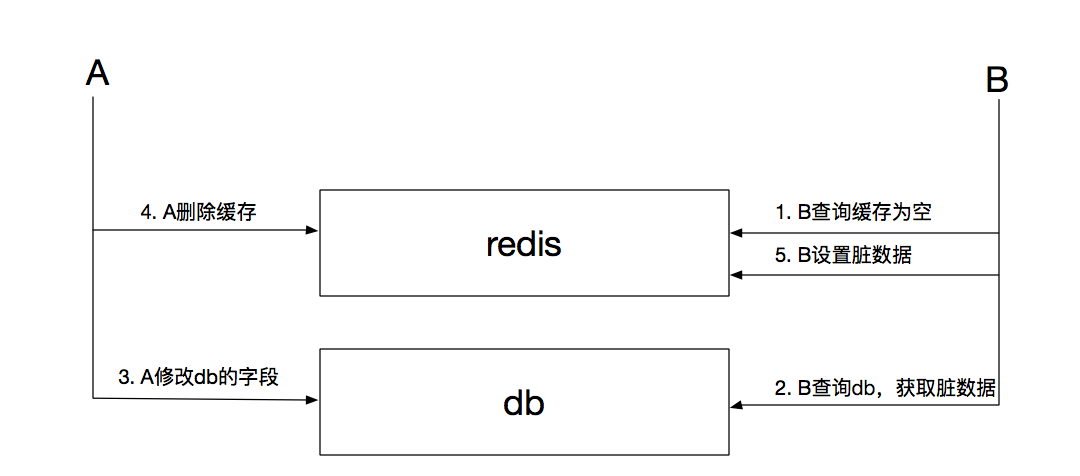
如上图,缓存出现脏数据的前提是第2步骤耗时大于第3、4步骤,即读耗时大于写耗时,这几乎不可能发生。就算发生,也可以通过A再次延迟删除缓存(两次删除)解决。
缓存操作问题
在上一节中提到的所有缓存更新策略都是在暂时不考虑缓存操作失败的情况(如网络原因、redis服务不可用等)前提下讨论的,如果缓存操作失败,则必须通过业务代码重试、消息队列或者设置缓存超时解决。
业务代码重试,设置合理的重试次数与间隔,如果超时后缓存仍然无法操作则需要等待缓存超时或者人为介入;
消息队列则在缓存操作失败后投递对应消息,在非业务代码中进行重试;
缓存超时则是兜底方案,这是允许最长的缓存不一致的时间。
分布式事务
比较遗憾的是,在node领域还没有类似JAVA的JTA规范及其实现,JTA规范中的核心“事务管理器TM”大都由容器来实现,如常见的jboss和websphere;TM接收业务层的事务请求,同时协同参与事务的各个资源管理器RM如dbms、mq等,实现分布式事务的提交与回滚;同时也提供分布式事务在不同自治系统的传递。
分布式事务的集中解决方案有如下几种:
1. 两阶段提交
2. 三阶段提交
3. 异步确保
4. TCC
在JAVA和其他生态已经证明了,两阶段提交的低效以及无法抗住高并发且存在单点的问题;三阶段提交虽然解决了两阶段的单点和减少协调者阻塞等待参与者的问题,但仍存在数据不一致的情况,因此这两种理论上的模型其实并不符合实际业务中的场景,在工程领域需要追求的是最优化,可见理论与现实仍然有不少差距。
那么在node场景中,处理分布式事务的方式也就只剩下两种工程上的解决方案。
node中使用异步确保模型可以使用相比较简单的基于消息队列的异步确保模型(也可基于本地数据库表)。将分布式长事务切分为多个本地事务,通过保障本地事务的可靠性实现分布式长事务的最终提交。如果参与分布式事务的某个本地事务执行出错进行回滚,则通过消息队列实现业务主动方的补偿,实现最终的数据一致性。
如下图:
TCC模型相比较异步确保而言则比较重,需要开发一个TCC的TM协调各个服务参与方,同时对参与事务的各个从服务侵入性比较大,必须提供try、confirm和cancel三个接口。其中try接口预留相关资源,并确保数据一致性,confirm接口和cancel接口保证幂等性,执行或回滚try阶段预留的资源。其中,在业务中主动调用所有参与分布式事务的从服务的try接口,并汇报给TM执行情况,由TM根据try阶段的结果完成后续的执行或回滚操作,同时记录分布式事务状态传递以及各个从服务的执行阶段等信息,便于追踪。
因此用node实现分布式事务时,在没有自研TCC中间件的前提下,可根据业务特性自行扩展异步确保型方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号