
2.mysql-进阶2_索引
索引
1.索引概述
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足 特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,
这样就可以在这些数据结构 上实现高级查找算法,这种数据结构就是索引。
|
优势 |
劣势 |
|
提高数据检索的效率,降低数据库 的IO成本 |
索引列也是要占用空间的。 |
|
通过索引列对数据进行排序,降低 数据排序的成本,降低CPU的消 耗。 |
索引大大提高了查询效率,同时却也降低更新表的速度, 如对表进行INSERT、UPDATE、DELETE时,效率降低。 |
2.索引的结构
1.MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种
|
索引结构 |
描述 |
|
B+Tree索引 |
最常见的索引类型,大部分引擎都支持 B+ 树索引 |
|
Hash索引 |
底层数据结构是用哈希表实现的 , 只有精确匹配索引列的查询才有效 , 不 支持范围查询 |
|
R-tree(空间索引) |
空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类 型,通常使用较少 |
|
Full-text(全文 索引 ) |
是一种通过建立倒排索引 ,快速匹配文档的方式。类似于Lucene,Solr,ES |
2.上述是MySQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持 情况。
我们平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引。
|
索引 |
InnoDB |
MyISAM |
Memory |
|
B+tree索引 |
支持 |
支持 |
支持 |
|
Hash 索引 |
不支持 |
不支持 |
支持 |
|
R-tree 索引 |
不支持 |
支持 |
不支持 |
|
Full-text |
5.6版本之后支持 |
支持 |
不支持 |
1二叉树 和红黑树
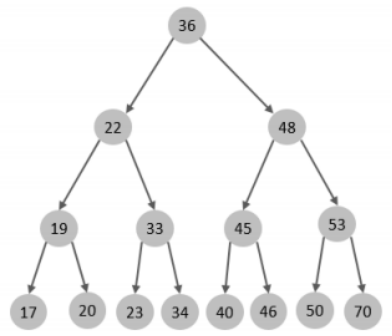
如果主键是顺序插入的,则会形成一个单向链表,结构如下

所以,如果选择二叉树作为索引结构,会存在以下缺点:顺序插入时,会形成一个链表,查询性能大大降低。大数据量情况下,层级较深,检索速度慢。
此时大家可能会想到,我们可以选择红黑树,红黑树是一颗自平衡二叉树,那这样即使是顺序插入数 据,最终形成的数据结构也是一颗平衡的二叉树 ,结构如下 :
但是,即使如此,由于红黑树也是一颗二叉树,所以也会存在一个缺点:
大数据量情况下,层级较深,检索速度慢。
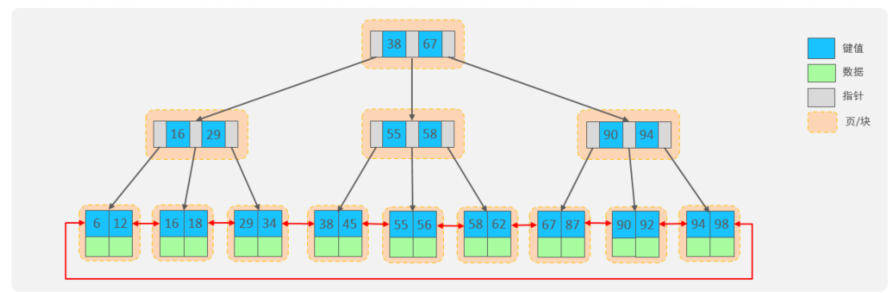
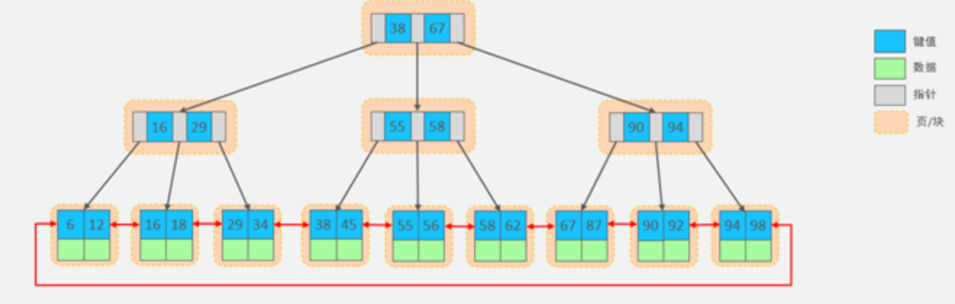
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是 B+Tree呢?在详解B+Tree之前,先来介绍一个B-Tree。
2.B-Tree
B-Tree,B树是一种多叉路衡查找树,相对于二叉树, B树每个节点可以有多个分支,即多叉。
以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key, 5 个指针:
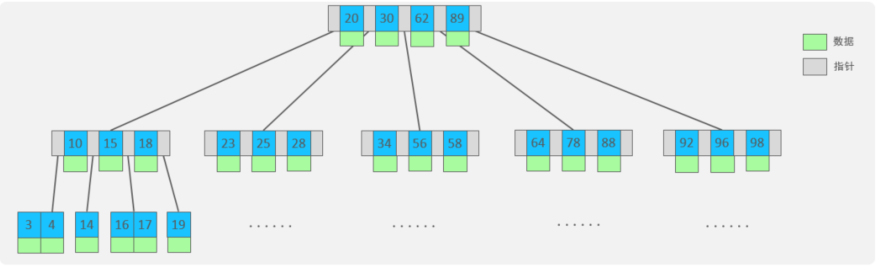
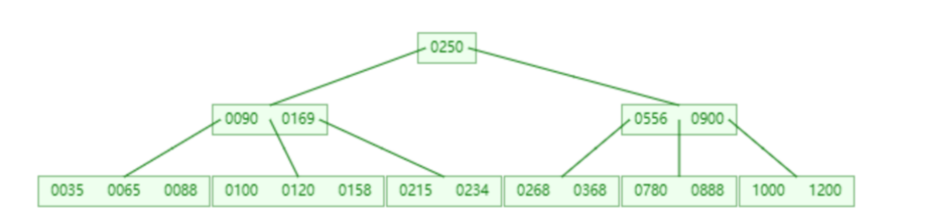
3. B+Tree
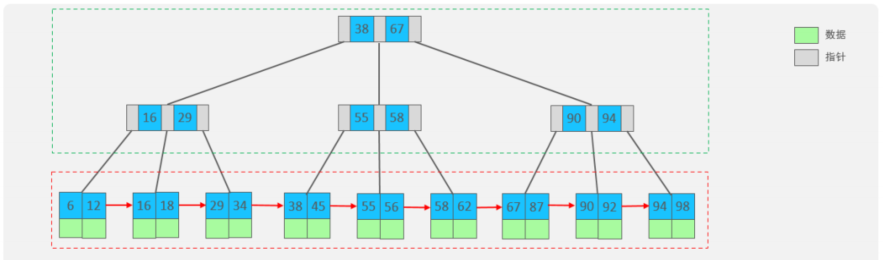
4. mysql中的B+Tree
5.Hash
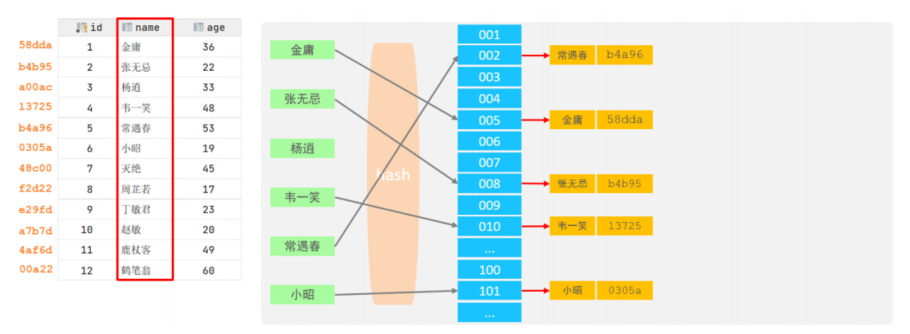
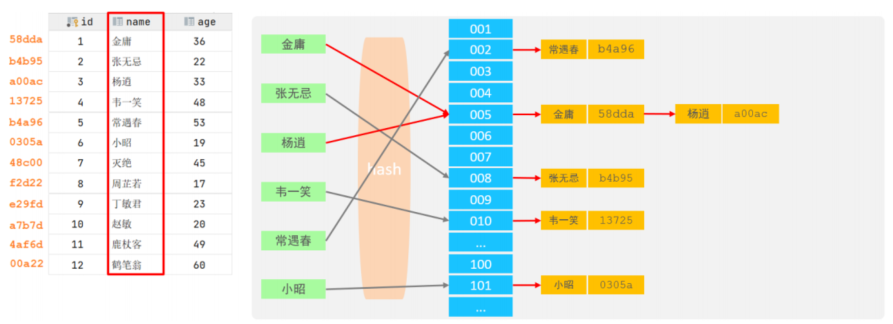
5.1.特点
3.索引的分类
1.按具体类型分
|
分类 |
含义 |
特点 |
关键字 |
|
主键 索引 |
针对于表中主键创建的索引 |
默认自动创建 , 只能 有一个 |
PRIMARY |
|
唯一 索引 |
避免同一个表中某数据列中的值重复 |
可以有多个 |
UNIQUE |
|
常规 索引 |
快速定位特定数据 |
可以有多个 |
|
|
全文 索引 |
全文索引查找的是文本中的关键词,而不是比 较索引中的值 |
可以有多个 |
FULLTEXT |
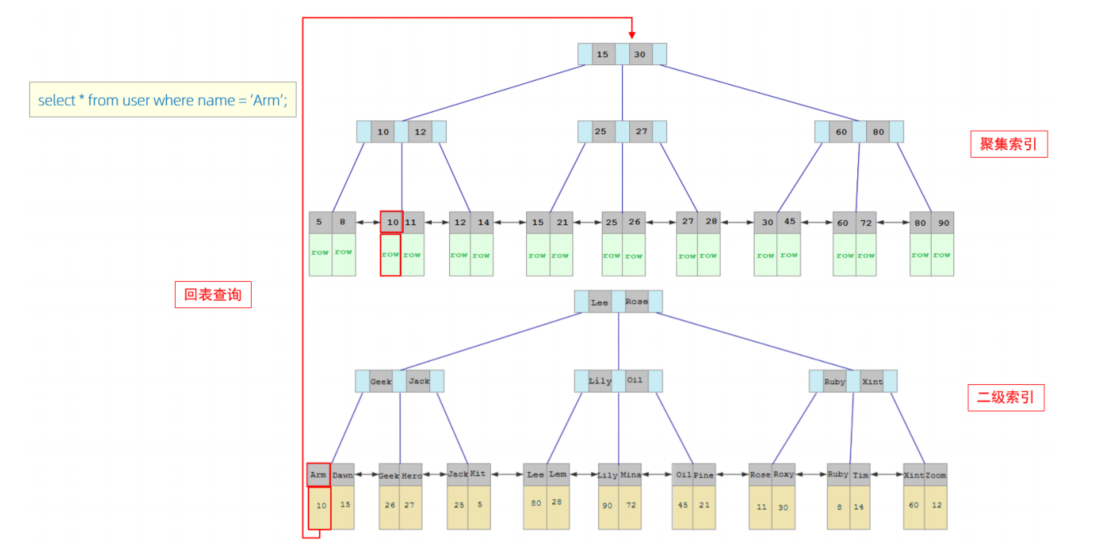
2. 按索引的存储形式分——聚集索引&二级索引
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
|
分类 |
含义 |
特点 |
|
聚集索引 (Clustered Index) |
将数据存储与索引放到了一块,索引结构的叶子 节点保存了行数据 |
必须有 ,而且只 有一个 |
|
二级索引 (Secondary Index) |
将数据与索引分开存储,索引结构的叶子节点关 联的是对应的主键 |
可以存在多个 |
1. 聚集索引选取规则 :
(1)如果存在主键,主键索引就是聚集索引。
(2)如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
(3)如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索 引。
2.聚集索引和二级索引的具体结构如下:
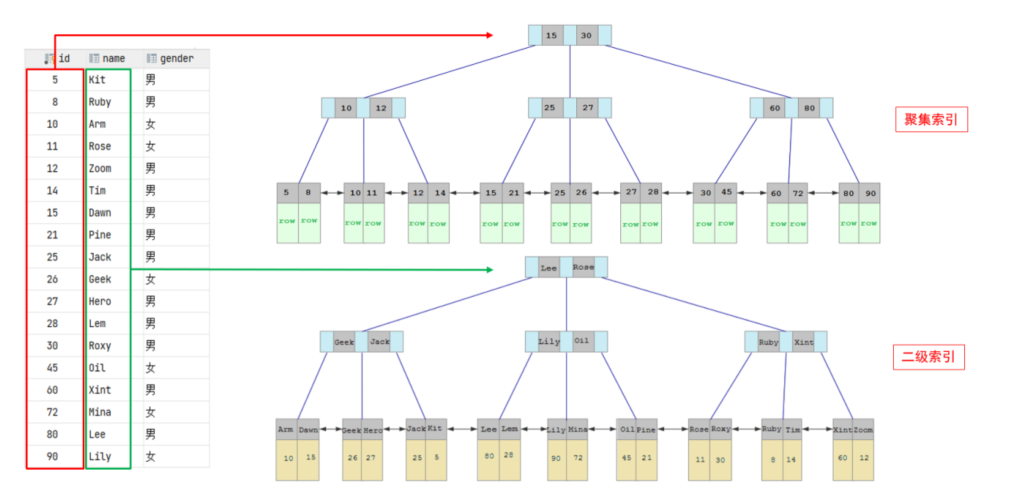
InnoDB主键索引的B+tree高度为多高呢?
4. 索引语法
1). 创建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... ) ;
DROP INDEX index_name ON table_name ;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号