三、Self-Attn 与 Deformable-Attn
1、Deformable Attention 的理解
Deforable Attention,是Deforable DETR 架构中使用的一个注意力模块,与传统Transformer 查询所有空间位置不同,Deformable Attention 只关注 参考点(reference Points) 附近的一组关键采样点,无需考虑特征图的大小。
2、单尺度的 Deformable Attention
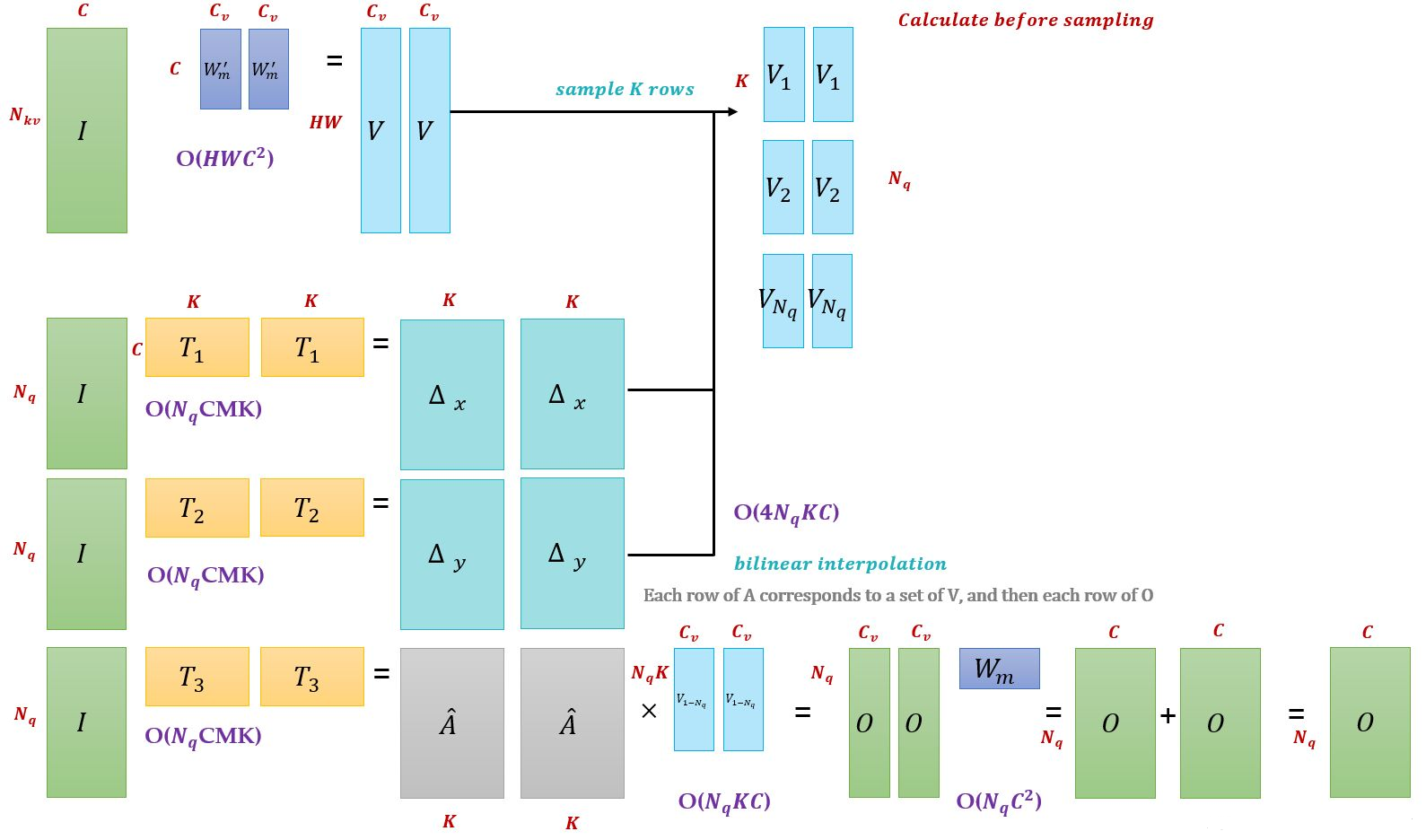
首先给出 MultiHead Attn 和 Deformable Attn 的公式,对于给定输入特征图 \(x \in \mathbb{R}^{C \times H \times W}\),有:
在 Self Attn 中,\(m\) 表示多头注意力中的第 \(m\) 个头,\(z \in \mathbb{R}^{C \times H \times W}\) 为 \(query\) 的输入特征, 可分解为\(N \times W\) 个 \(z_q \in \mathbb{R}^{C}\)。 \(x \in \mathbb{R}^{C \times H \times W}\) 是 \(key\) 和 \(value\) 的输入特征, 可分解为\(N \times W\) 个 \(x_k \in \mathbb{R}^{C}\)。 \(q\) 是 \(query\) 的索引,\(k\) 是 \(key\) 的索引。
\(W_m^{'} \in \mathbb{R}^{C_v \times C}\) (其中\(C_v = C/M\),分为多头) 是输入特征 \(x_k\) 到 \(value\) 的转移矩阵(通常和生成 \(query\) 方式一样,也是线性变换),\(W_m \in \mathbb{R}^{C_v \times C}\) 是对注意力施加在 \(value\) 后的结果进行线性变换从而得到不同头部的输出结果。
对比下这两个公式,在 MultiHeadAttn 中:
红色部分,\(p_q \in \mathbb{R}^2\) 代表 \(z_q\) 的位置,即参考点 (reference points), \(\Delta p_{mqk} \in \mathbb{R}^2\) 表示第 \(m\) 个注意力头中的第 \(k\) 个采样集合点相对参考点的位置偏移(offsets)。
蓝色部分, \(K\) 表示采样的 \(key\) 的总数,\(k \in [1,K](K<<HW)\), 即每个 \(query\) 在每个注意力头中采样 \(K\) 个位置,只需要和这些位置的特征进行交互,不需要和 Transformer 一样从全局位置开始学习才能逐步关注到局部、稀疏的位置。\(x(p_q + \Delta p_{mqk})\) 即为基于采样点通过 双线性插值(bilinear interpolation) 转为 \(feature\) \(map\) 上的特征点得到的 \(value\)。
其中,位置偏移 \(\Delta p_{mqk}\) 是可学习的,由 \(query\) 特征 \(z_q \in \mathbb{R}^C\) 经过全连接层得到,注意力权重同样由 \(query\) 特征 \(z_q \in \mathbb{R}^C\) 通过全连接层得到,同时在 \(K\) 个采样点之间归一化,而非像 Transformer 是由 \(query\) 与 \(key\) 交互计算得出的, \(A_{mpk} \in [0,1]\),并且 \(\sum_{k=1}^K A_{mqk}=1\).
TODO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号