

SQL中为什么NULL与任意值(包括NULL)使用“=、!=”对比都为false?
设计理念上的解释:
在其他的计算机语言概念中NULL一般代表的是空,什么都没有。
但在SQL语言的概念中NULL代表的不是空,而是不清楚,是未知的。
例如:
张三的年龄是NULL,代表的是张三的年龄不清楚,而不是张三的年龄为空。
李四的年龄是NULL,代表的是李四的年龄不清楚,而不是李四的年龄为空。
王五的年龄是25,代表的是王五的年龄是25岁。
数据库认为张三和李四的年龄是不清楚的,两个不清楚的年龄进行对比,怎么能确定他们的年龄相同或者不相同呢,于是NULL = NULL和NULL != NULL都返回false。
而王五的年龄是25岁,25岁和不清楚的年龄进行对比,也不能确定25岁和不清楚的年龄是否相同或者不相同,于是25 = NULL和25 != NULL都会返回false。
实际应用场景中的解释:
当然我们知道,NULL = NULL、NULL != NULL、25 = NULL、25 != NULL,返回什么和NULL在概念上是空还是不清楚没有直接关系,主要看数据库的开发人员使得它返回什么。
现在我们再从实际应用场景中判断一下NULL与任意值(包括NULL)使用“=、!=”对比都为false这个设计到底合不合理。
-- 创建测试用户表
CREATE TABLE DEMO_USER
(
[ID] INT NULL -- ID(允许为空)
,[NAME] NVARCHAR(10) NOT NULL -- 姓名
,[AGE] INT NOT NULL -- 年龄
);
-- 接下来我用ID列进行演示,为什么ID列要允许为空呢?细思极恐……
-- 向表中插入4条数据
INSERT INTO DEMO_USER(ID, NAME, AGE)
VALUES
(1, '张三', 23)
,(2, '李四', 24)
,(NULL, '王五', 25)
,(NULL, '赵六', 26);
-- 查询表中的所有数据
/*
1 张三 23
2 李四 24
NULL 王五 25
NULL 赵六 26
*/
SELECT * FROM DEMO_USER;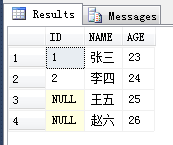
-- 查询ID等于NULL或者等于1的数据
-- 因为NULL = NULL为false,1 = 1为true,所以只有一条ID为1的用户数据符合查询条件
/*
1 张三 23
*/
SELECT * FROM DEMO_USER WHERE ID IN (NULL, 1); -- 相当于:WHERE ID = NULL OR ID = 1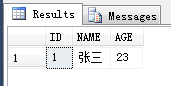
-- 查询ID不等于NULL并且不等于1的数据
-- 因为NULL != 任何数据(包括NULL)都为false,所以没有一条数据符合查询条件
SELECT * FROM DEMO_USER WHERE ID NOT IN (NULL, 1); -- 相当于:WHERE ID != NULL AND ID != 1
-- 没有查询到符合条件的数据
SELECT * FROM DEMO_USER WHERE NULL != NULL;
-- 没有查询到符合条件的数据
SELECT * FROM DEMO_USER WHERE NULL = NULL;
-- 没有查询到符合条件的数据
SELECT * FROM DEMO_USER WHERE 1 != NULL;
-- 没有查询到符合条件的数据
SELECT * FROM DEMO_USER WHERE 0 != NULL;
-- 把年龄为22岁用户的姓名修改为“二狗子”
BEGIN
-- 定义一个v_id变量接收查询到的ID
DECLARE @v_id INT;
-- 查询年龄为22岁的数据(表中没有年龄为22岁的用户数据,所以查询结果为null)
SELECT @v_id = ID FROM DEMO_USER WHERE AGE = 22;
-- NULL
SELECT @v_id;
-- 将测试用户表中ID = @v_id用户的姓名修改为“二狗子”
-- “1 = NULL”和“2 = NULL”为false这很好理解,但如果“NULL = NULL”为true的话,此时会误将年龄为25岁和26岁两个用户的姓名修改为“二狗子”
UPDATE DEMO_USER SET NAME = '二狗子' WHERE ID = @v_id;
-- 实际上并未修改任何数据,这样的结果是符合预期的,因为我们的初衷只想把年龄为22岁用户的姓名修改为“二狗子”
/*
1 张三 23
2 李四 24
NULL 王五 25
NULL 赵六 26
*/
SELECT * FROM DEMO_USER;
END;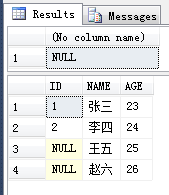
-- 把年龄不为25岁用户的姓名修改为“二愣子”
BEGIN
-- 定义一个v_id变量接收查询到的ID
DECLARE @v_id INT;
-- 查询年龄为25岁的数据(年龄25的用户数据是“王五”该数据的ID列为null,所以查询结果为null)
SELECT @v_id = ID FROM DEMO_USER WHERE AGE = 25;
-- NULL
SELECT @v_id;
-- 将测试用户表中ID != @v_id用户的姓名修改为“二愣子”
-- “NULL != NULL”为false这很好理解,如果“1 != NULL”和“2 != NULL”为true的话,会使得年龄为26岁用户的姓名仍然还是原来的赵六
UPDATE DEMO_USER SET NAME = '二愣子' WHERE ID != @v_id;
-- 实际上并未修改任何数据,这样的结果虽然不符合预期,但至少没有出现错误的数据修改操作。
-- 话说没改不一样是没成功吗?对没错,但在现实情况下改错了往往比没改成功的解决方案要麻烦的多。
/*
1 张三 23
2 李四 24
NULL 王五 25
NULL 赵六 26
*/
SELECT * FROM DEMO_USER;
END;
有眼尖的朋友可能已经发现了,我直接用
UPDATE DEMO_USER SET NAME = '二狗子' WHERE AGE = 22;
UPDATE DEMO_USER SET NAME = '二愣子' WHERE AGE != 25;
上面的这两条SQL不就大功告成了吗?为什么偏偏要脱裤子放屁整出这么些东西呢?
如果你已经想到了这些,说明你的思维很灵敏。
但现实中的很多情况下,你不得不创建一个参数用于接收一个值。然后用这个参数,作为后续SQL语句的判断条件。
总结:
在绝大多数情况下,NULL与任意值(包括NULL)使用“=、!=”对比都为false,这样的设计会极大减少误操作的可能。
-- 删除测试用户表,做个干净的程序员
DROP TABLE DEMO_USER;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号