


一、Pip
(1)pip升级
python -m pip install --upgrade pip
(2)查看pip配置文件位置
pip -v config list
(3)pip换源
# 阿里云 https://mirrors.aliyun.com/pypi/simple/ # 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
单次换源:pip install Scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
修改配置换源:pip.ini
[global] index-url=https://pypi.tuna.tsinghua.edu.cn/simple
二、Scrapy:
(1)安装scrapy报错 Running setup.py install for Twisted ... error:
下载 Twisted‑20.3.0‑cp39‑cp39‑win_amd64.whl 进行安装,地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install C:\python\Twisted-20.3.0-cp39-cp39-win_amd64.whl
(2)框架图
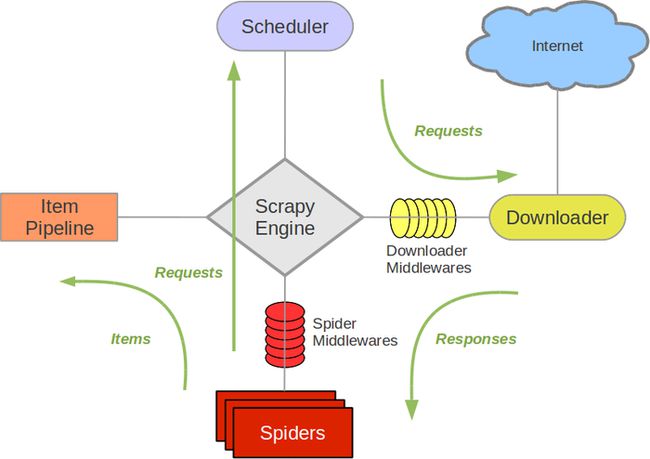
Scrapy Engine(引擎):负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等
Scheduler(调度器): 负责接收引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理
Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
Item Pipeline:负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):一个可以自定义扩展和操作引擎,负责Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses和从Spiders出去的Requests)
(3)scrapy命令:
创建scrapy项目:scrapy startproject 项目名称
查看可用的创建爬虫模板(basic、crawl、csvfeed、xmlfeed):scrapy genspider -l
创建爬虫:scrapy genspider -t basic toutiaoCrawl toutiao.com
执行爬虫:scrapy crawl toutiaoCrawl
测试(在spiders将response写到文件):
def parse(self, response): with open('d:/abin.html',"w+",encoding=response.encoding) as f: f.seek(0) f.truncate() f.write(response.body.decode(response.encoding)) pass
(4)setting.py
# 是否遵循robots协议 ROBOTSTXT_OBEY = False # 是否启用cookie # COOKIES_ENABLED = False # 默认request header DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8', #'Referer': 'https://www.baidu.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36', } # 下载同一个网站下一个页面前需要等待的时间 # DOWNLOAD_DELAY = 2 # 启用后,当从相同的网站获取数据时,Scrapy将会等待一个随机的值,延迟时间为0.5到1.5之间的一个随机值乘以DOWNLOAD_DELAY # RANDOMIZE_DOWNLOAD_DELAY = True # 对单个网站进行并发请求的最大值 # CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 对单个IP进行并发请求的最大值,如果非0,则忽略CONCURRENT_REQUESTS_PER_DOMAIN设定,使用该IP限制设定 # CONCURRENT_REQUESTS_PER_IP = 16 # 自动限速扩展 # 默认为False,设置为True可以启用该扩展 # AUTOTHROTTLE_ENABLED = True # 初始下载延迟,单位为秒 # AUTOTHROTTLE_START_DELAY = 5 # 设置在高延迟情况下的下载延迟,单位为秒 # AUTOTHROTTLE_MAX_DELAY = 60 # 用于启动Debug模式,默认为False # AUTOTHROTTLE_DEBUG = False
(5)日志
settings.py: # 日志 LOG_ENABLED = True # 日志编码 LOG_ENCODING = 'utf-8' # 日志文件,默认为 None LOG_FILE = '.\log\scrapy.log' # CRITICAL(严重错误)、ERROR(一般错误)、WARNING(警告)、INFO(一般信息)、DEBUG(调试信息) LOG_LEVEL = 'DEBUG' # 进程所有的标准输出(及错误)将会被重定向到log中(例如print,print默认级别是Info) LOG_STDOUT = True 输出日志的py文件: import logging def parse(self, response): logging.info(response.body.decode(response.encoding)) pass
按日期输出日志(settings.py):
import datetime to_day = datetime.datetime.now() #...... #...... #...... LOG_FILE = '.\log\scrapy_{}_{}_{}.log'.format(to_day.year, to_day.month,to_day.day)
日志格式:文件、行号、函数等(settings.py)
# 日志日期格式 LOG_DATEFORMAT = "%Y-%m-%d %H:%M:%S" # 日志格式 LOG_FORMAT = "%(asctime)s-%(levelname)s-%(filename)s-%(funcName)s-%(lineno)d: %(message)s"
(6)fake-useragent
安装:pip install fake_useragent
使用:
settings.py: DOWNLOADER_MIDDLEWARES = { '项目名称.middlewares.RandomUserAgentMiddleware': 543, } middlewares.py: class RandomUserAgentMiddleware: def process_request(self, request, spider): ua = UserAgent() request.headers['User-Agent'] = ua.random
(7)selenium
(8)scrapy+scrapyd+scrapy-redis+Gerapy(spiderkeeper 、scrapydweb、Crawlab)
(9)其他
开源request等测试地址:http://httpbin.org/get
三、VS Code
(1)注释及取消注释:CTRL+/
注释:CTRL+K+C 、取消注释:CTRL+K+U
四、Mysql8
(1)修改密码:
ALTER USER "root"@"localhost" IDENTIFIED BY "你的新密码";
(2)插入数据提示:[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
在my.ini的mysqld下增加:
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
(3)执行mysql命令提示找不到msvcp140.dll
缺VC++2015,安装即可。微软下载地址:https://www.microsoft.com/zh-cn/download/details.aspx?id=53840
(4)windows启动服务及net start mysql命令启动服务,提示 “服务没有及时响应启动或控制请求”、“NET HELPMSG 2186”
我的电脑(此电脑)->右键“管理”->“服务”->找到对应的Mysql服务->右键“属性” ->“登录” ->选“此账户”->选用户输入密码
(5)mysql函数
length: 一个汉字是算三个字符,一个数字或字母算一个字符
char_length: 不管汉字还是数字或者是字母都算是一个字符
replace:Update `table_name` SET `field_name` = replace (`field_name`,’from_str’,'to_str’)
五、命令行
(1)tree /f 查看树状目录结构
(2)命令行输出过滤 pip list | find /I "scrapy"
六、GIS
OSM:https://www.openstreetmap.org/
OSM数据下载:http://download.geofabrik.de/asia/
QGIS:https://www.qgis.org/zh-Hans/site/
QGIS插件:https://plugins.qgis.org/
GeoHey Toolbox 插件(坐标转换)、QuickMapServices 插件(底图)、QuickOSM
QGIS DESKTOP设置中文:setting->options->general->override system locale->user interface translation->简体中文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号