
第四次作业
作业①
股票爬取
实验要求
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
核心代码和运行结果
点击查看代码
import pymysql
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'root'
MYSQL_DB = 'stocks_db'
MYSQL_PORT = 3306
board_list = [
("沪深A股", "#hs_a_board"),
("上证A股", "#sh_a_board"),
("深证A股", "#sz_a_board")
]
max_page = 3
def get_driver():
options = Options()
# 防止被检测为自动化测试软件
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=options)
driver.maximize_window()
return driver
def main():
print("作业开始运行了...")
print("正在连接 MySQL 数据库...")
try:
conn = pymysql.connect(
host=MYSQL_HOST,
user=MYSQL_USER,
password=MYSQL_PASSWORD,
database=MYSQL_DB,
port=MYSQL_PORT,
charset='utf8mb4'
)
c = conn.cursor()
except Exception as e:
print(f"数据库连接失败: {e}")
return
c.execute("DROP TABLE IF EXISTS stock_data")
sql = '''
CREATE TABLE stock_data \
( \
id INT AUTO_INCREMENT PRIMARY KEY, \
board_type VARCHAR(50), \
stock_code VARCHAR(20), \
stock_name VARCHAR(50), \
latest_price VARCHAR(20), \
change_percent VARCHAR(20), \
change_amount VARCHAR(20), \
volume VARCHAR(50), \
turnover VARCHAR(50), \
amplitude VARCHAR(20), \
high VARCHAR(20), \
low VARCHAR(20), \
open_price VARCHAR(20), \
prev_close VARCHAR(20)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
'''
c.execute(sql)
conn.commit()
print("数据库表创建成功!")
driver = get_driver()
try:
for board in board_list:
b_name = board[0]
b_code = board[1]
url = "http://quote.eastmoney.com/center/gridlist.html" + b_code
print(f"\n正在爬取:{b_name},网址是:{url}")
driver.get(url)
driver.refresh()
for i in range(1, max_page + 1):
tr_list = driver.find_elements(By.XPATH, "//table//tbody/tr")
data_to_save = []
for tr in tr_list:
tds = tr.find_elements(By.TAG_NAME, "td")
if len(tds) < 10:
continue
code = tds[1].text
if not code:
continue
one_row = (
b_name,
code,
tds[2].text,
tds[4].text,
tds[5].text,
tds[6].text,
tds[7].text,
tds[8].text,
tds[9].text,
tds[10].text,
tds[11].text,
tds[12].text,
tds[13].text
)
data_to_save.append(one_row)
if len(data_to_save) > 0:
insert_sql = '''
INSERT INTO stock_data (board_type, stock_code, stock_name, latest_price,
change_percent, change_amount, volume, turnover,
amplitude, high, low, open_price, prev_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
'''
c.executemany(insert_sql, data_to_save)
conn.commit()
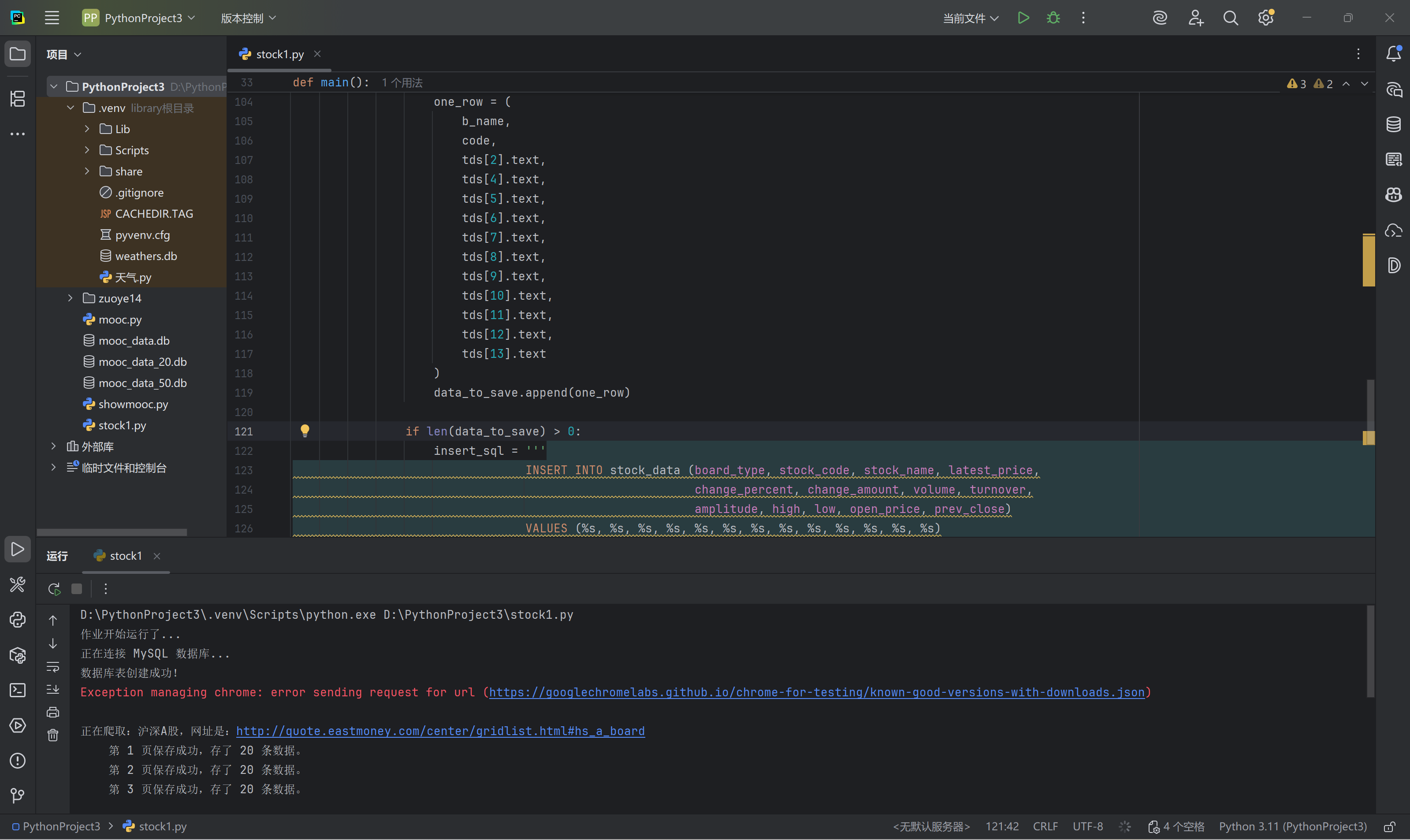
print(f" 第 {i} 页保存成功,存了 {len(data_to_save)} 条数据。")
else:
print("lose")
if i < max_page:
try:
next_button = driver.find_element(By.CSS_SELECTOR, "a[title='下一页']")
driver.execute_script("arguments[0].click();", next_button)
time.sleep(5)
except Exception as e:
print(f"翻页失败: {e}")
break
time.sleep(2)
finally:
driver.quit()
c.close()
conn.close()
print("easy ")
if __name__ == "__main__":
main()
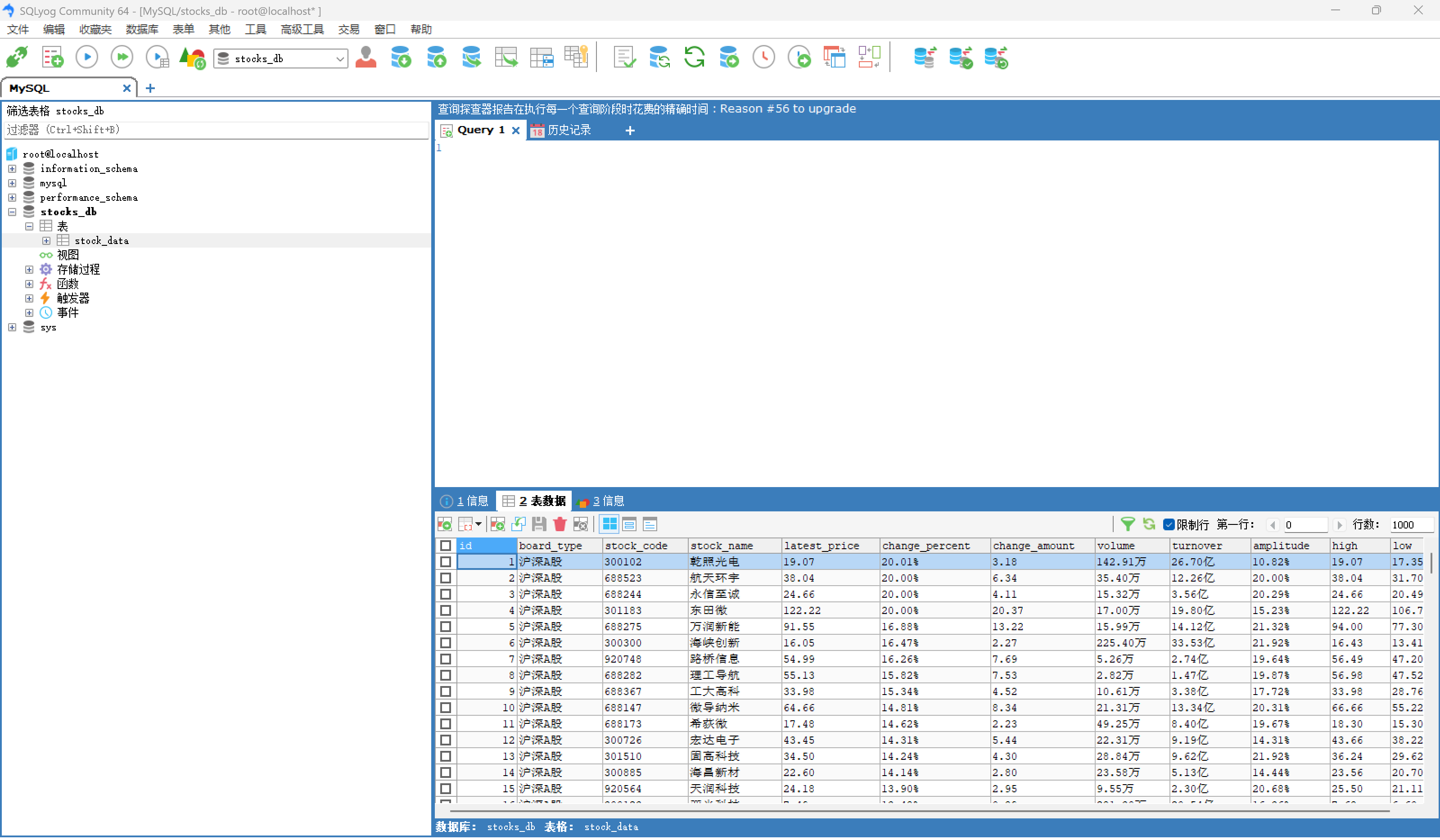
心得体会
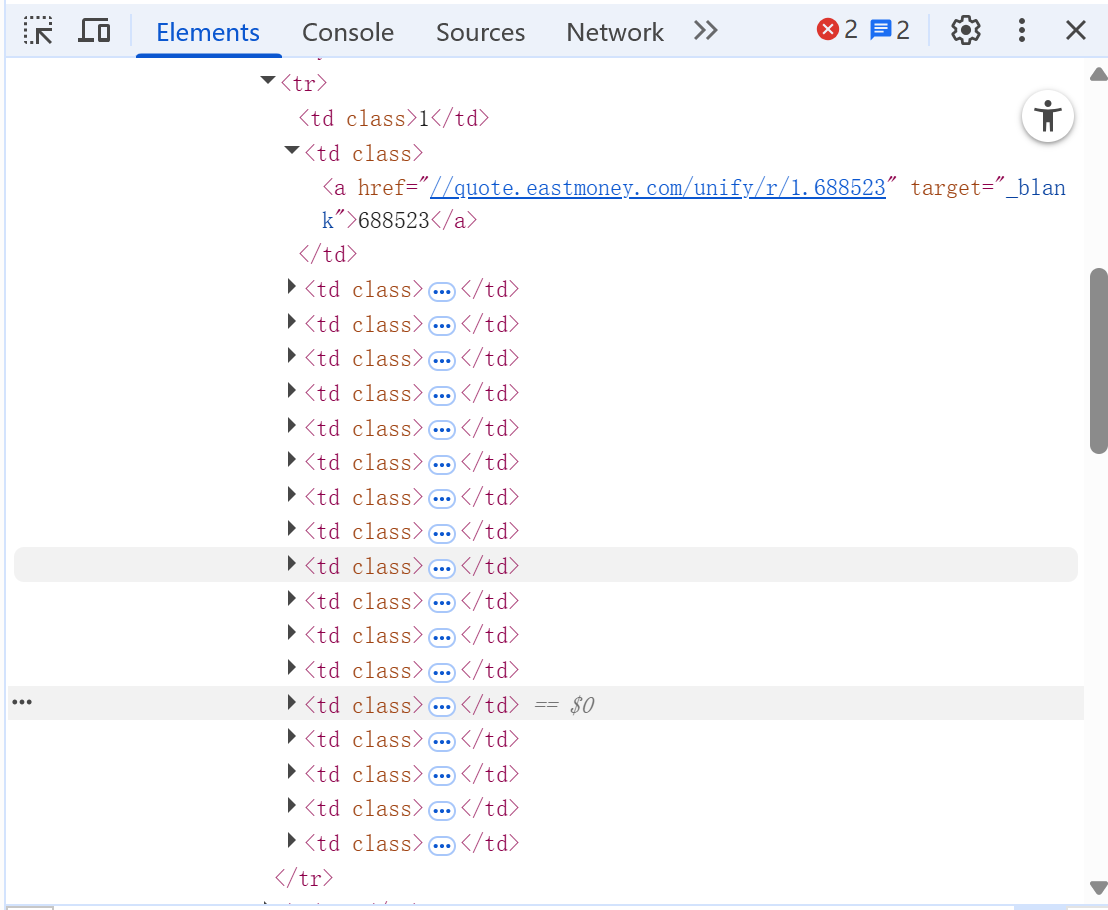
我首先用xpath来抓取表格行tr,然后直接定位他的td标签,每个td标签内就有我要的数据,最后在翻页上用css选择器定位title来找到翻页按钮,最开始我用.click,但是由于弹出广告的缘故会失败,所有我最后改用js点击,这样就可以成功

gitee:https://gitee.com/abcman12/2025_crawl_project/blob/master/作业4/stock.csv
作业②
mooc爬取
实验要求
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
核心代码与运行结果
点击查看代码
import pymysql
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# --- 数据库配置 (请修改) ---
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASS = 'root'
MYSQL_DB = 'mooc'
target_url = 'https://www.icourse163.org/home.htm?userId=1528358600#/home/course'
def main():
print("正在连接数据库...")
conn = pymysql.connect(
host=MYSQL_HOST,
user=MYSQL_USER,
password=MYSQL_PASS,
database=MYSQL_DB,
charset='utf8mb4'
)
cur = conn.cursor()
print("数据库连接成功")
# 删表
cur.execute("DROP TABLE IF EXISTS courses")
# 建表
sql = '''
CREATE TABLE courses \
( \
id INT AUTO_INCREMENT PRIMARY KEY, \
cCourse VARCHAR(255), \
cCollege VARCHAR(255), \
cTeacher VARCHAR(255), \
cCount VARCHAR(100), \
cProcess VARCHAR(100), \
cBrief TEXT, \
url VARCHAR(500)
)
'''
cur.execute(sql)
conn.commit()
print("表建好了")
# --- 2. 启动浏览器 ---
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(options=options)
driver.maximize_window()
# --- 3. 获取链接 ---
print(f"打开网页:{target_url}")
driver.get(target_url)
print("扫码登录")
time.sleep(10)
print("开始获取课程链接")
url_list = []
# 获取所有a标签
all_links = driver.find_elements(By.TAG_NAME, 'a')
for link in all_links:
href = link.get_attribute('href')
if href:
if '/course/' in href and 'search.htm' not in href:
if href not in url_list:
url_list.append(href)
print(f"一共找到 {len(url_list)} 个课程")
count = 0
for u in url_list:
count += 1
print(f"\n正在爬第 {count} 个:{u}")
driver.get(u)
time.sleep(3)
# 初始化变量
c_course = "未找到"
c_college = "未找到"
c_teacher = "未找到"
c_count = "0"
c_process = "未找到"
c_brief = "无简介"
#找学校
pic_xpath = '/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/a/img'
pic_eles = driver.find_elements(By.XPATH, pic_xpath)
if len(pic_eles) > 0:
# 列表不为空,说明找到了
school_name = pic_eles[0].get_attribute('alt')
if school_name:
c_college = school_name
else:
c_college = pic_eles[0].get_attribute('title')
else:
backup_xpath = '//*[@id="j-teacher"]/div/a'
backup_eles = driver.find_elements(By.XPATH, backup_xpath)
if len(backup_eles) > 0:
c_college = backup_eles[0].text
#找课程名
course_xpath = '/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]'
course_eles = driver.find_elements(By.XPATH, course_xpath)
if len(course_eles) > 0:
c_course = course_eles[0].text
#找老师
teacher_xpath = '/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div/div[1]/div/div/h3'
teacher_eles = driver.find_elements(By.XPATH, teacher_xpath)
if len(teacher_eles) > 0:
c_teacher = teacher_eles[0].text
#找简介
brief_xpath = '/html/body/div[5]/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/div[2]/div[1]'
brief_eles = driver.find_elements(By.XPATH, brief_xpath)
if len(brief_eles) > 0:
text = brief_eles[0].text
if len(text) > 200:
c_brief = text[:200] + "..."
else:
c_brief = text
# === 5. 找人数 ===
count_xpath = '/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[4]/span[2]'
count_eles = driver.find_elements(By.XPATH, count_xpath)
if len(count_eles) > 0:
c_count = count_eles[0].text
# === 6. 找进度 ===
process_xpath = '/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[4]/span[1]'
process_eles = driver.find_elements(By.XPATH, process_xpath)
if len(process_eles) > 0:
c_process = process_eles[0].text
# === 存入数据库 ===
insert_sql = '''
INSERT INTO courses (cCourse, cCollege, cTeacher, cCount, cProcess, cBrief, url)
VALUES (%s, %s, %s, %s, %s, %s, %s)
'''
cur.execute(insert_sql, (c_course, c_college, c_teacher, c_count, c_process, c_brief, u))
conn.commit()
print(f" 保存成功:{c_course}")
driver.quit()
cur.close()
conn.close()
print("运行结束")
if __name__ == "__main__":
main()
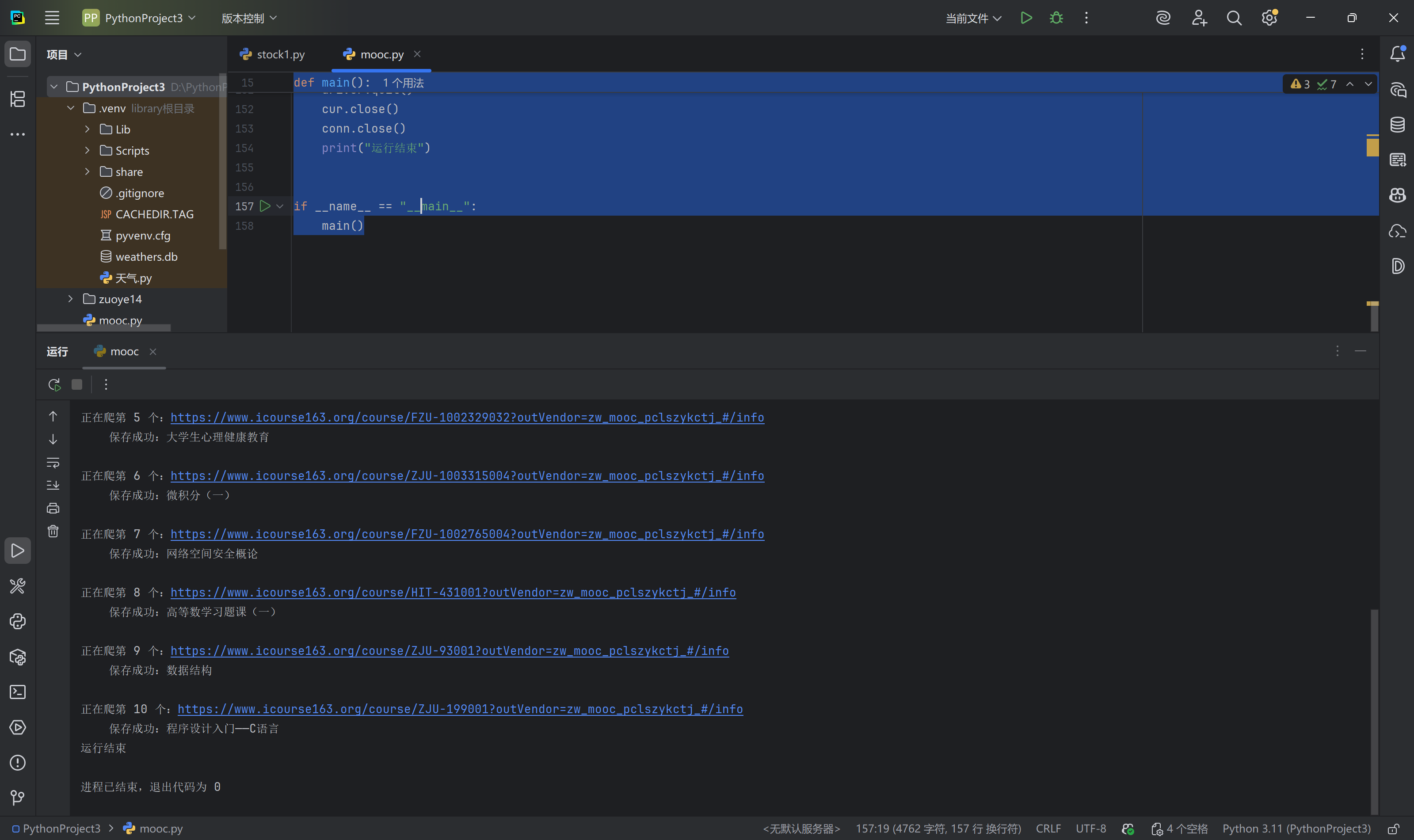
心得体会
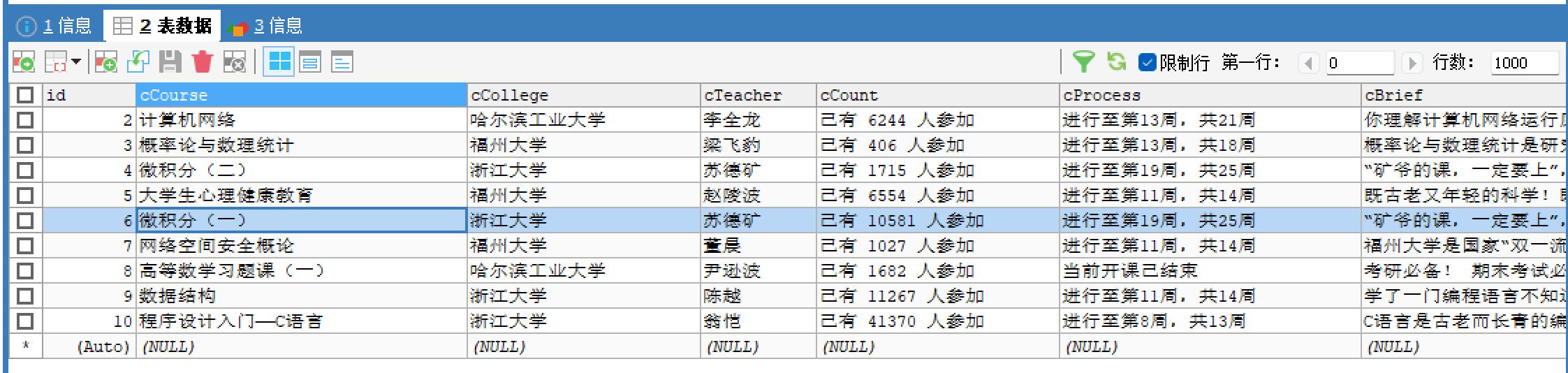
我选择爬取的是mooc的我的课程部分的信息,如图所示
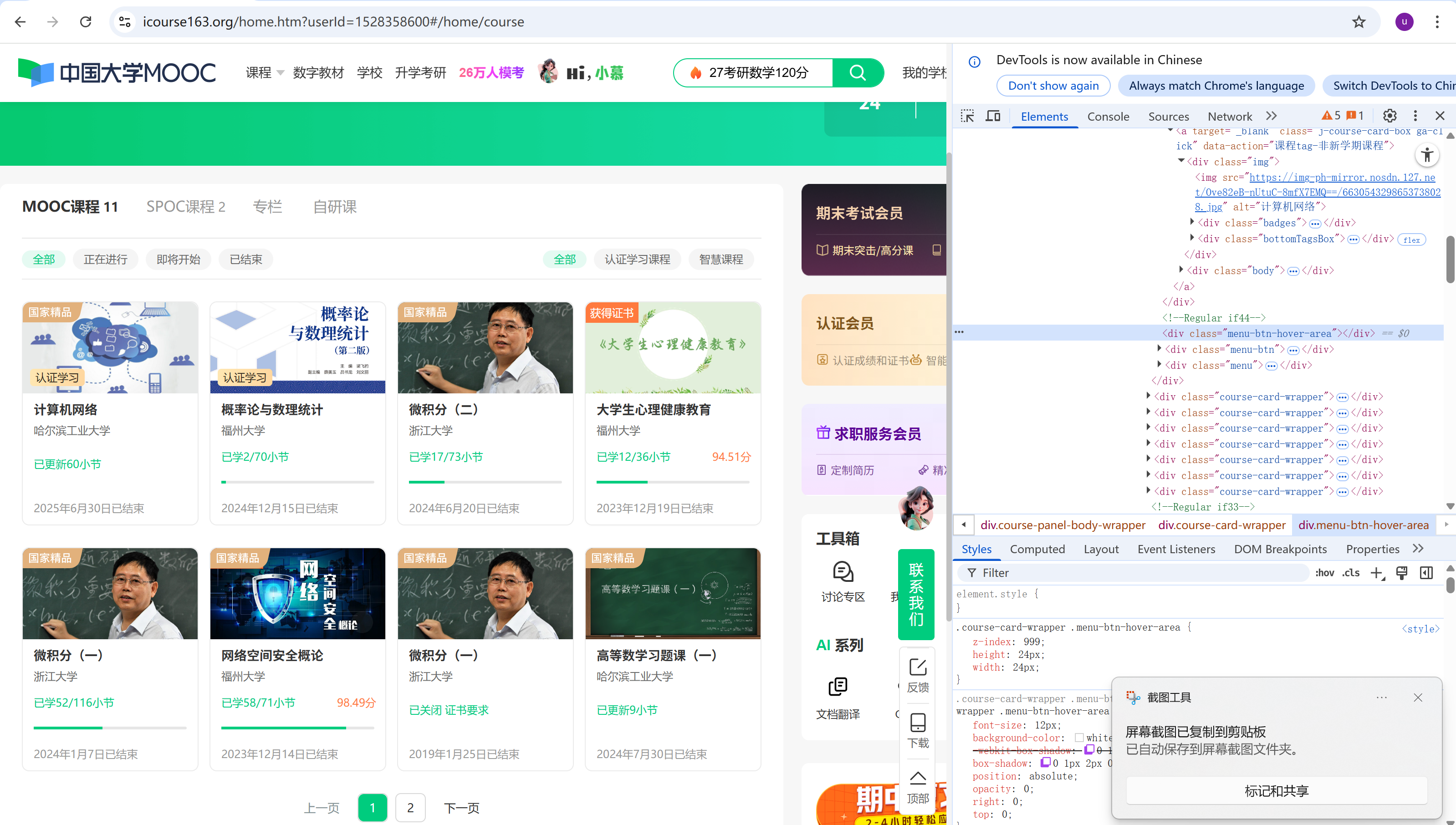
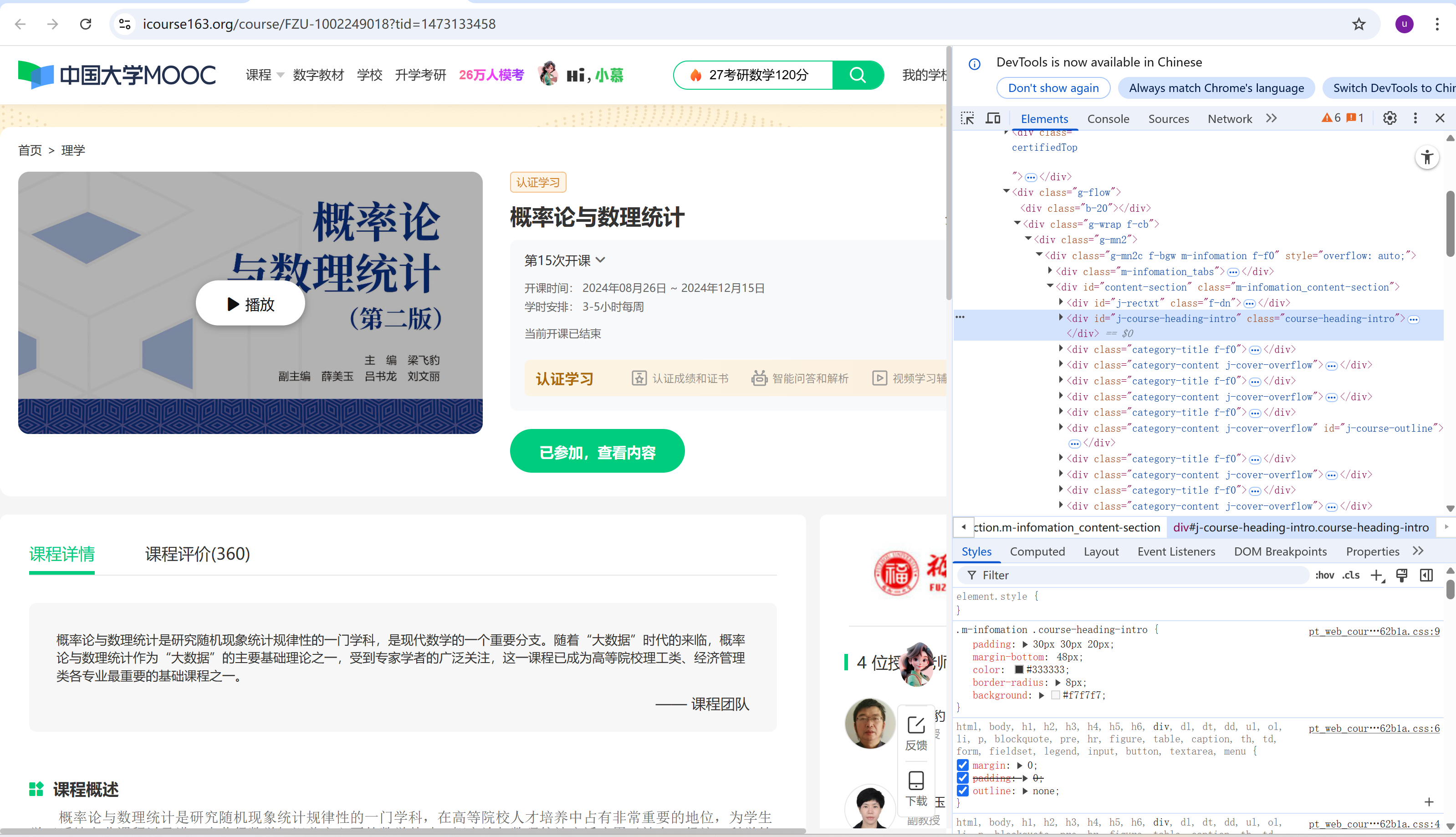
我的主要思路是先拿到url,再查找题目所需要的每个要爬取信息的xpath复制下来这样就能简单粗暴的爬取到所需信息,这样就能实现题目要求
gitee:https://gitee.com/abcman12/2025_crawl_project/blob/master/作业4/mooc.csv
作业③
flume
实验要求
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部
分)v2.docx 中的任务
运行结果
python脚本生成测试数据,查看生成结果

配置kafka
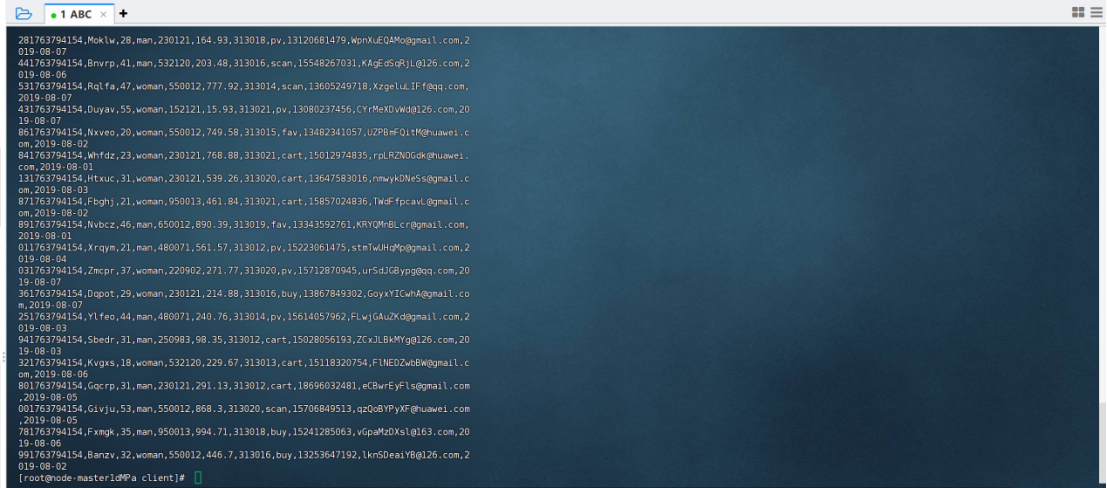
创建topic
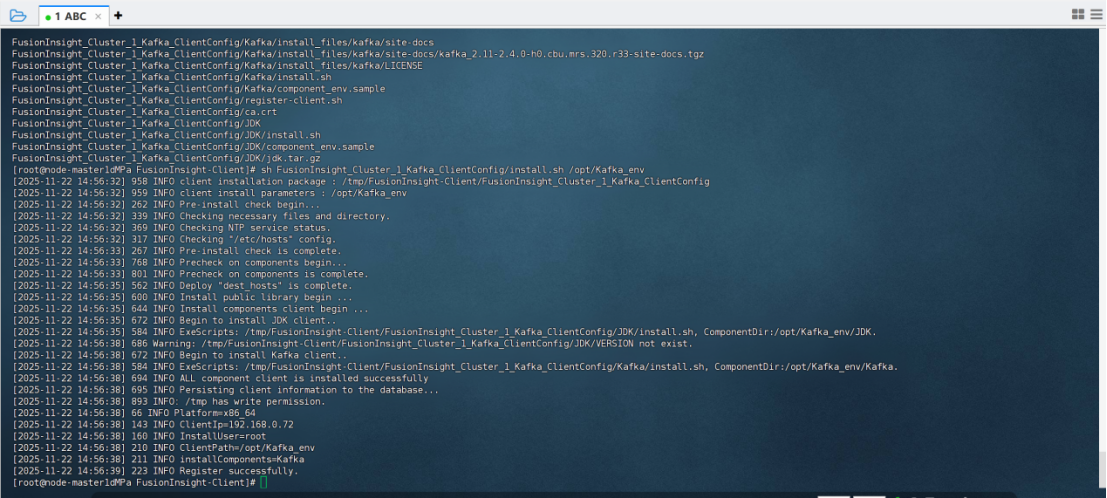
安装flume客户端
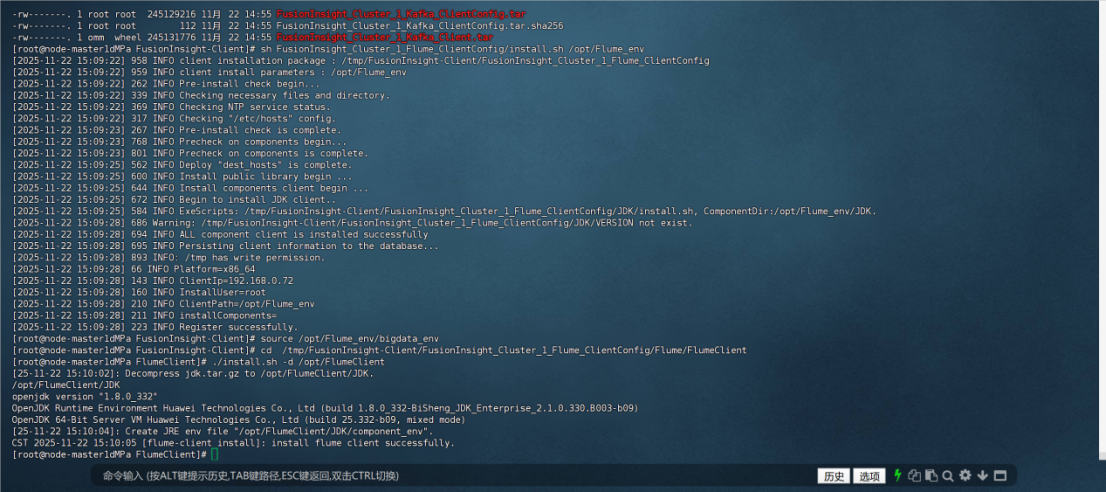
安装成功

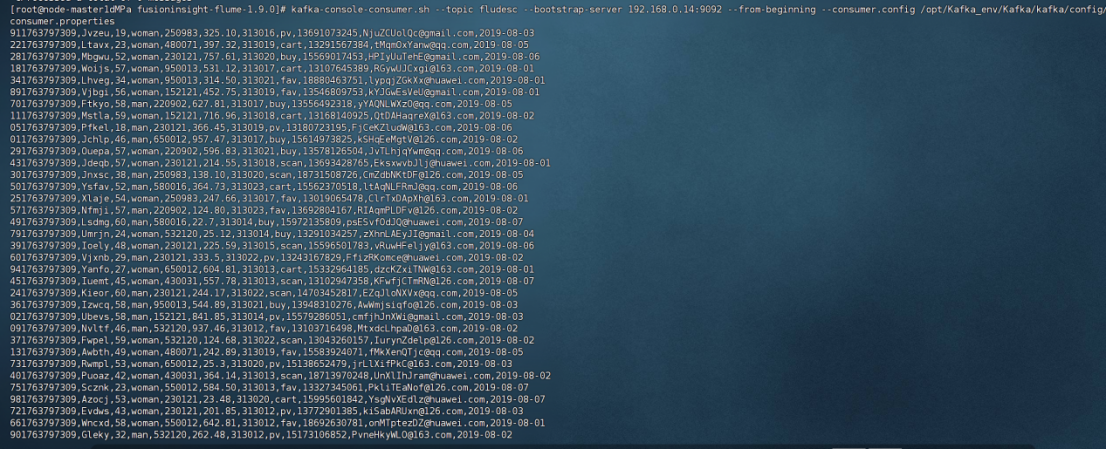
配置flume采集数据

心得体会
熟悉了flume操作过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号