
MongoDB 数据碎片处理
2025-04-09 10:38 abce 阅读(216) 评论(0) 收藏 举报识别数据碎片
数据碎片会严重影响数据库的整体效率。为确保顺利运行,定期实施压缩和清理数据的策略至关重要。
使用以下命令检测数据库碎片
db.getSiblingDB(dbName).getCollection(coll).stats().wiredTiger['block-manager']['file bytes available for reuse']
解释一下:
db.getSiblingDB(dbName) // 切换到指定数据库 `dbName` .getCollection(coll) // 获取集合 `coll` .stats() // 返回集合的统计信息 .wiredTiger // WiredTiger 存储引擎相关统计 ['block-manager'] // WiredTiger 的块管理器(管理存储文件) ['file bytes available for reuse'] // 指标:文件可重复利用的字节数
从 mongodb 5.5 开始,一个新的字段 freeStorageSize 被引入,可以借助该属性来识别碎片。
#数据的碎片大小
db.stats({ freeStorage: 1, scale: 1024*1024*1024 }).freeStorageSize
#索引和数据的碎片总和
db.stats({ freeStorage: 1, scale: 1024*1024*1024 }).totalFreeStorageSize
碎片的处理
数据和索引都可能出现碎片。管理碎片的方法主要有两种:
1.压缩(Compaction)
2.初始同步(Initial synchronization)
压缩(Compaction)
压缩会重写指定集合中的所有数据和索引,从而去掉碎片。通过重组数据存储,它有助于优化数据访问并提高整体性能。在使用 WiredTiger 存储引擎的数据库中,这一过程不仅能提高效率,还能将不必要的磁盘空间释放回操作系统。这对管理存储资源尤其有益,可在数据随时间变化时更好地利用磁盘空间。
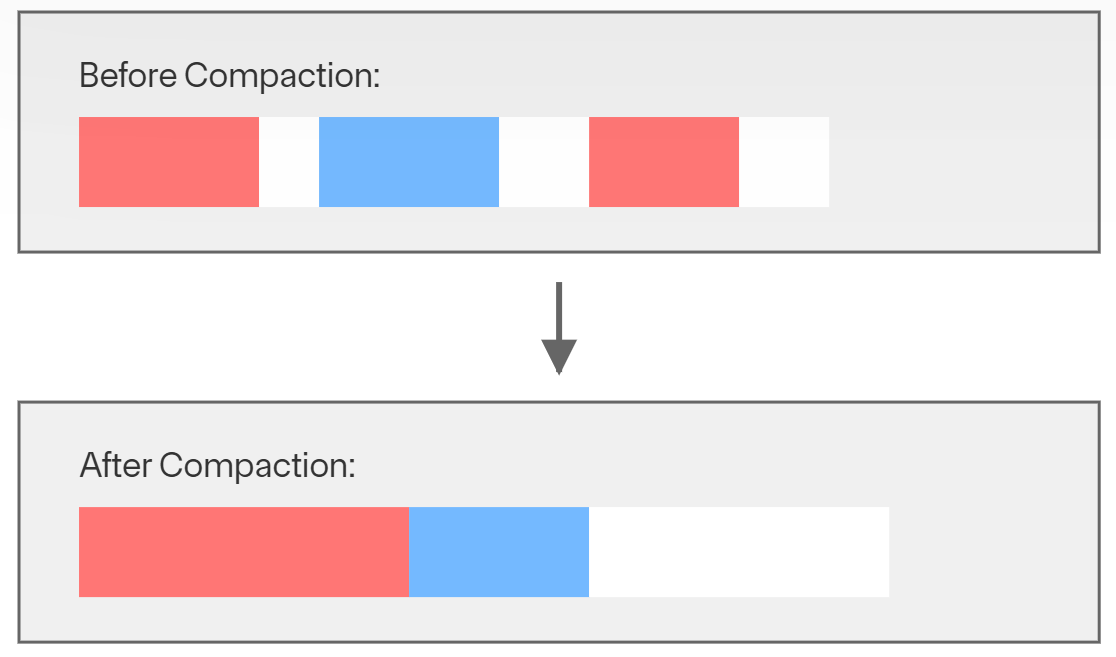
使用压缩时的注意事项
·对于强制执行身份验证的群集,必须以目标集合上具有压缩权限的用户身份登录。dbAdmin 和 hostManager 角色授予在非系统集合上运行压缩命令的必要权限。对于系统集合,需要创建自定义角色和压缩权限。
·主节点不会向次节点复制压缩命令。
·要观察数据集存储空间的变化,可在压缩前后执行 collStats 命令。
·压缩的效果取决于工作负载,而且可能无法恢复磁盘空间。
·从 Mongo 2.6 版开始,mongod 会在压缩操作后并行重建所有索引。
·从 MongoDB 5.0.12 开始,在执行压缩过程时,副本可以复制数据,可以对副本读取数据
8.0之前版本的压缩命令:
db.runCommand(
{
compact: <string>, //指定要压缩的集合名
force: <boolean>, // Optional
comment: <any>, // Optional
})
8.0开始支持的压缩命令:
db.runCommand(
{
compact: <string>,
dryRun: <boolean>,
force: <boolean>, // Optional
freeSpaceTargetMB: <int>, // Optional,默认值是20mb
comment: <any>, // Optional
}
)
压缩对应的阻塞行为
|
版本 |
阻塞行为 |
|
版本4.4之前 |
压缩会阻塞读和写活动 |
|
版本4.4 |
会阻塞以下操作: ·db.collection.drop() ·db.collection.createIndex() ·db.collection.createIndexes() ·db.collection.dropIndex() ·db.collection.dropIndexes() ·collMod |
|
版本4.4之后 |
会阻塞以下操作(锁行为发生了一些变化): ·db.collection.drop() ·db.collection.createIndex() ·db.collection.createIndexes() ·db.collection.dropIndex() ·db.collection.dropIndexes() ·collMod |
|
版本6.0.2开始(包含5.0.12) |
·压缩执行过程中,副本可以复制数据 ·可以读副本数据 |
终止正在进行的压缩
要检查正在进行的压缩,可以使用 db.currentOp() 命令。根据 db.currentOp() 的输出,可以使用操作 ID 和 db.killOp() 方法来终止服务器上正在进行的压缩。
执行压缩的步骤
1.在副本节点上启动压缩: 首先在辅助节点上运行压缩进程。这有助于尽量减少对主节点性能的影响。
2.将副本节点提升为主节点:副本节点上的压缩完成后,将其中一个副本节点提升为主节点。这可以使用群集管理工具或命令来完成。
3.在原主节点上运行压缩:旧的主节点现在作为副本节点运行,继续在该节点上运行压缩过程。这将确保在不影响主副本运行的情况下对其进行优化。
4.还原到原主节点: 在原主节点上完成压缩后,将其切换回主节点。这样就可以恢复所有节点都已优化的原始配置。
遵循此流程有助于确保将中断降至最低,并保持 MongoDB 群集的性能。
注意:从 MongoDB 版本 8.0 开始,引入了一项名为 autoCompact 的新功能。该功能在后台运行,以识别空闲空间并回收这些空间,从而优化存储效率。
初始同步(Initial synchronization)
还可以在服务器上执行初始同步,以消除碎片数据。在此过程中,副本节点会对主节点的数据进行初始快照,复制所有数据库、集合和索引,并将数据存储在有序的数据块中。这有助于消除碎片。
建议在非生产时间执行。
初始同步的步骤
1.关闭mongodb实例:关闭副本节点上的mongodb实例服务
2.将副本节点从副本集中移除
3.重启mongodb实例
4.重新将副本加入副本集中
5.验证复制的延迟,确保副本和主节点完全同步
最后
建议使用初始同步而不是压缩方法来解决数据碎片问题。这是因为压缩必须在每个单独的集合上执行,而且不能保证能有效回收所有要求的磁盘空间。通过选择初始同步,可以确保更彻底、更高效地管理数据碎片,同时最大限度地降低与碎片存储相关的潜在性能下降。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号