Hadoop综合大作业&补交两次作业
Hadoop综合大作业 :
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。

把文件上传到hdfs上
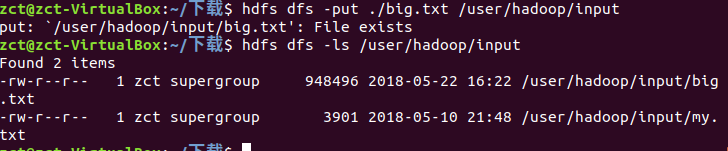
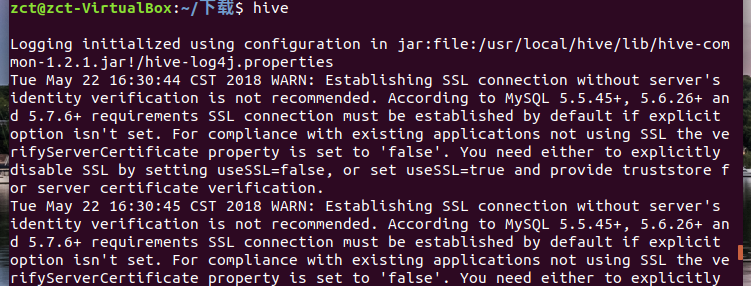
启动hive
将数据写入到study表

创建分析表统计

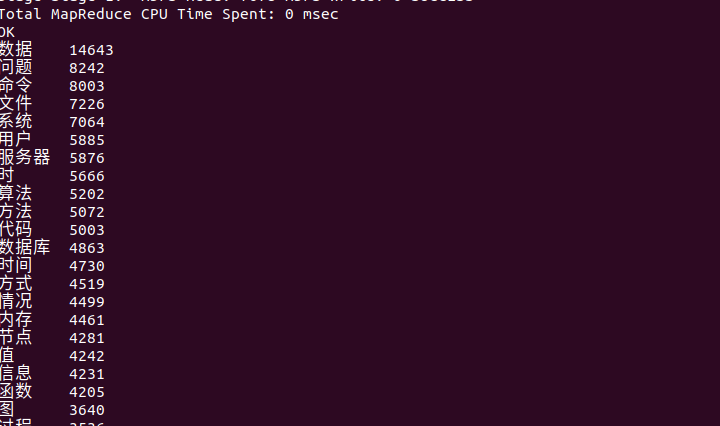
查看分析统计结果

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
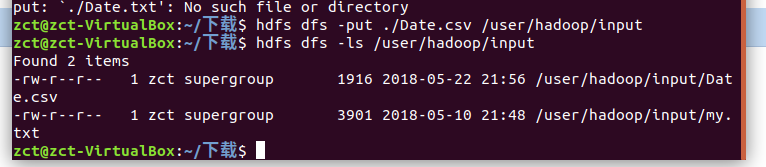
将数据以csv格式上传到hdfs
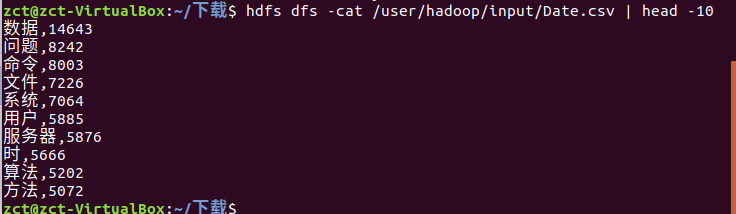
查看前10个数据
启动hive
创建表将csv数据导入到表中

查看前22个数据
补交的作业:
熟悉常用的HDFS
1.在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件txt,里面可以随意输入一些单词.
mkdir hadoop
cd hadoop
touch test.txt
gedit test.txt
2.在本地查看文件位置(ls)
cd ~/hadoop
ls -al
3.在本地显示文件内容
cat test.txt
4.使用命令把本地文件系统中的“txt”上传到HDFS中的当前用户目录的input目录下
cd /usr/local/hadoop ./sbin/start-dfs.sh ./bin/hdfs dfs -mkdir -p /user/hadoop ./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ~/hadoop/test.txt input
5.查看hdfs中的文件(-ls)
./bin/hdfs dfs -ls input
6.显示hdfs中该的文件内容
./bin/hdfs dfs dfs -cat input/test.txt
7.删除本地的txt文件并查看目录
cd ~/hadoop
re -r test.txt
8.从hdfs中将txt下载地本地原来的位置
cd /usr/local/hadoop
./bin/hdfs dfs -get input/test.txt ~/hadoop
9.从hdfs中删除txt并查看目录
./bin/hdfs dfs -rm -ls input/test.txt
Hive基本操作与应用
通过hadoop上的hive完成WordCount
1.启动hadoop

2.Hdfs上创建文件夹


3.上传文件至hdfs

4上传文件至hdf

5.创建原始文档表

6.导入文件内容到表docs并查看

7.用HQL进行词频统计,结果放在表word_count里

8.查看统计结果



 浙公网安备 33010602011771号
浙公网安备 33010602011771号