K8S单节点二进制部署
目录:
一、环境准备
二 、部署etcd集群
三、flannel网络配置
四、部署master组件
五、部署node组件
一、环境准备
k8s集群master1:192.168.91.5 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集群node1: 192.168.91.10 kubelet kube-proxy docker flannel k8s集群node2: 192.168.91.15 kubelet kube-proxy docker flannel
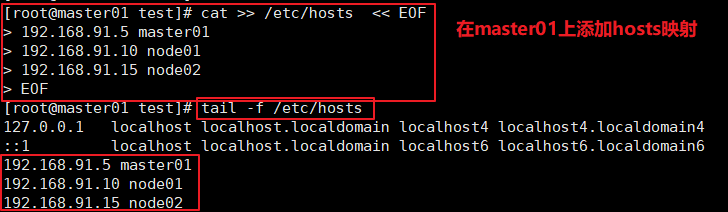
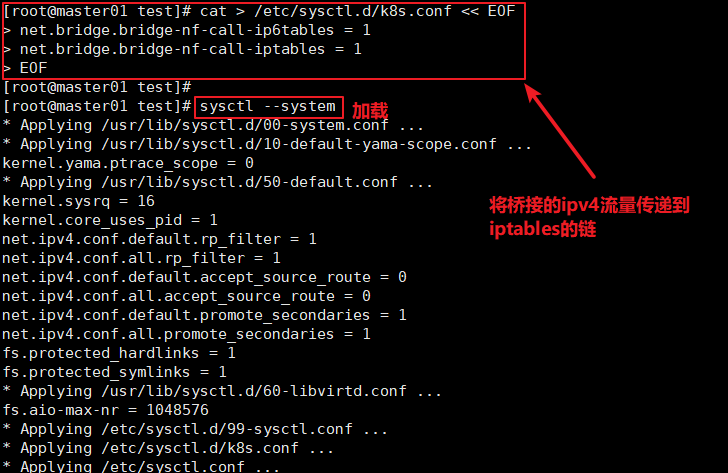
#关闭防火墙 systemctl disable --now firewalld #关闭selinux setenforce 0 sed -i 's/enforcing/disabled/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #根据规划设置主机名 hostnamectl set-hostname master01 hostnamectl set-hostname node01 hostnamectl set-hostname node02 #在master添加hosts cat >> /etc/hosts << EOF 192.168.91.5 master01 192.168.91.10 node01 192.168.91.15 node02 EOF #将桥接的ipv4流量传递到iptables的链 cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl --system #时间同步 yum -y install ntpdate ntpdate time.windows.com



二 、部署etcd集群
etcd作为服务发现系统,有以下的特点:
• 简单 安装配置简单,而且提供了HTTP API进行交互,使用也很简单
• 安全: 支持SSL证书验证
• 快速: 单实例支持每秒2k+读操作
• 可靠: 采用raft算法实现分布式系统数据的可用性和一致性
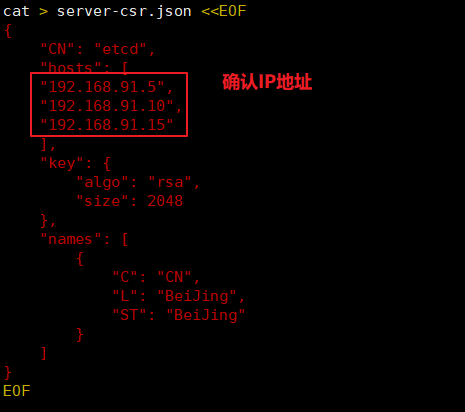
准备签发证书环境 CFSSL是CloudFlare 公司开源的一款PKI/TLS工具。CESSL 包含一个命令行工具和一个用于签名、验证和捆绑TLS证书的HTTP API服务。使用Go语言编写。 CFSSL使用配置文件生成证书,因此自签之前,需要生成它识别的json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。 CFSSL用来为etcd提供TLS证书,它支持签三种类型的证书: 1、client证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如kube-apiserver 访问etcd; 2、server证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如etcd对外提供服务: 3、peer证书,相互之间连接时使用的证书,如etcd节点之间进行验证和通信。 这里全部都使用同一套证书认证。
注:etcd这里就不做集群了,直接部署在master节点上
1、master节点部署
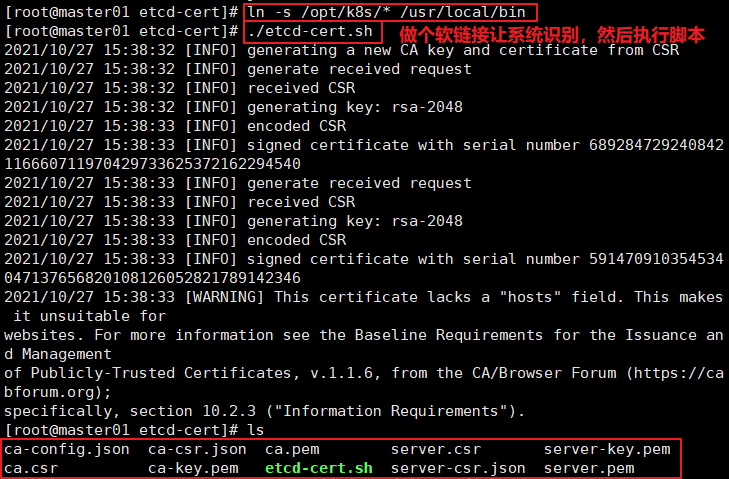
==下载证书制作工具== curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o /usr/local/bin/cfssl curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o /usr/local/bin/cfssljson curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o /usr/local/bin/cfssl-certinfo chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson /usr/local/bin/cfssl-certinfo chmod +x /usr/local/bin/cfssl ================================= cfssl: 证书签发的工具命令 cfssljson: 将cfssl 生成的证书( json格式)变为文件承载式证书 cfssl-certinfo:验证证书的信息 cfssl-certinfo -cert <证书名称> #查看证书的信息 ================================= //创建k8s.工作目录 mkdir /opt/k8s cd /opt/k8s/ //上传etcd-cert.sh 和etcd.sh 到/opt/k8s/ 目录中 chmod +x etcd-cert.sh etcd.sh //创建用于生成CA证书、etcd服务器证书以及私钥的目录 mkdir /opt/k8s/etcd-cert mv etcd-cert.sh etcd-cert/ cd /opt/k8s/etcd-cert/ ./etcd-cert.sh #生成CA证书、etcd服务器证书以及私钥

2、启动etcd服务//etcd二进制包地址: https://github.com/etcd-io/etcd/releases
//上传etcd-v3.3.10-1inux-amd64.tar.gz 到/opt/k8s/ 目录中,解压etcd 压缩包
cd /opt/k8s/
tar zxvf etcd-v3.3.10-linux-amd64.tar.gz
1s etcd-v3.3.10-linux-amd64
Documentation etcd etcdctl README-etcdctl.md README.md
READMEv2-etcdctl.md
==========================
etcd就是etcd服务的启动命令,后面可跟各种启动参数
etcdct1主要为etcd服务提供了命令行操作
============================
//创建用于存放etcd配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}
mv /opt/k8s/etcd-v3.3.10-linux- amd64/etcd /opt/k8s/etcd-v3.3.10-1inux-amd64/etcdct1 /opt/etcd/bin/
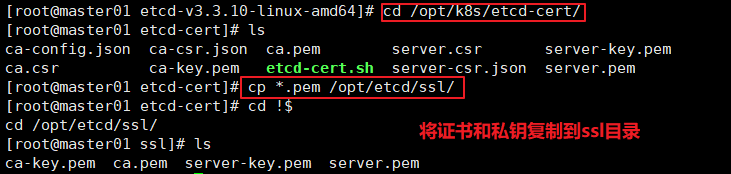
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
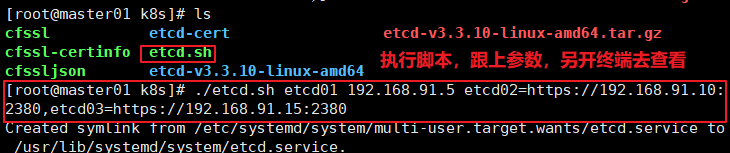
./etcd.sh etcd01 192.168.80.10 etcd02=https://192.168.80.11:2380,etcd03=https://192.168.80.12:2380
//进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
/另外打开一个窗口查看etcd进程是否正常
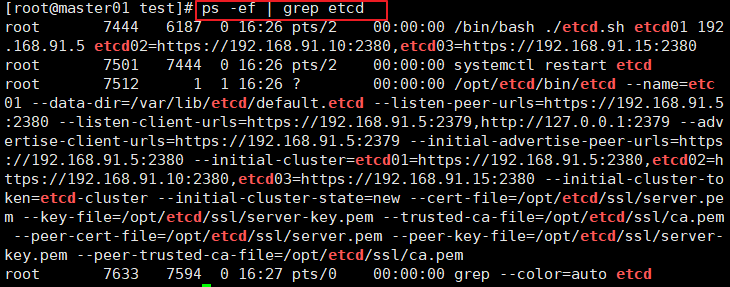
ps -ef | grep etcd
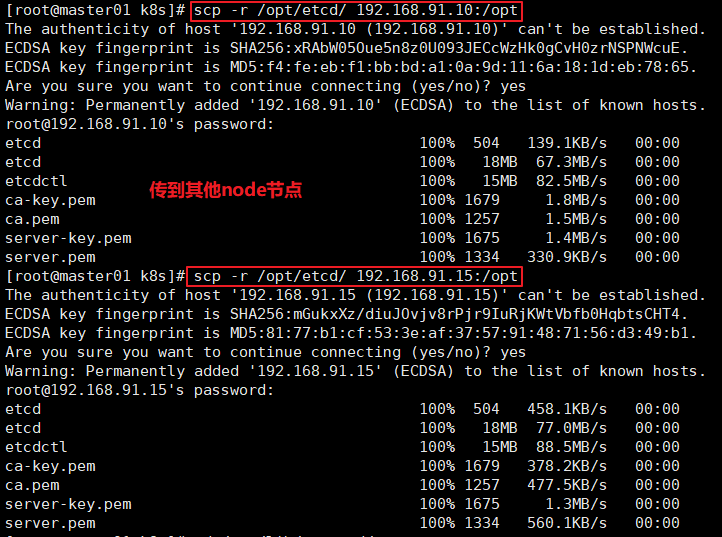
//把etcd相关证书文件和命令文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ root@192.168.80.11:/opt/
scp -r /opt/etcd/ root@192.168.80.12:/opt/
//把etcd服务管理文件拷贝到另外两个etcd集群节点
scp /usr/lib/systemd/system/etcd.service root@192.168.80.11:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service root@192.168.80.12:/usr/lib/systemd/system/
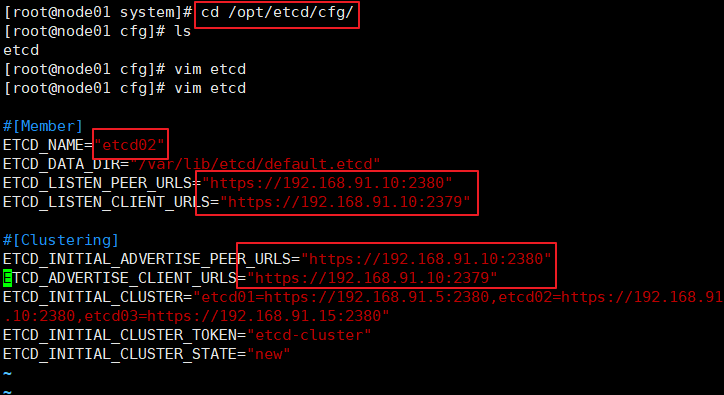
//在node1举例修改
cd /opt/etcd/cfg/
vim etcd
修改后内容
#[Member]
ETCD_NAME="etcd02"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.91.10:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.91.10:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.91.10:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.91.10:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.91.5:2380,etcd02=https://192.168.91.10:2380,etcd03=https://192.168.91.15:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
//修改后
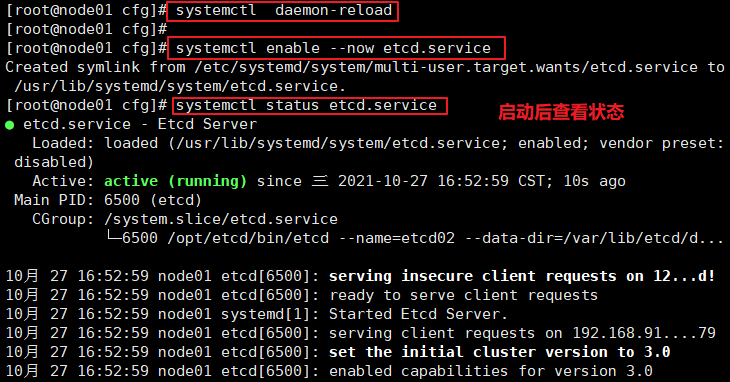
systemctl daemon-reload
systemctl enable --now etcd.service



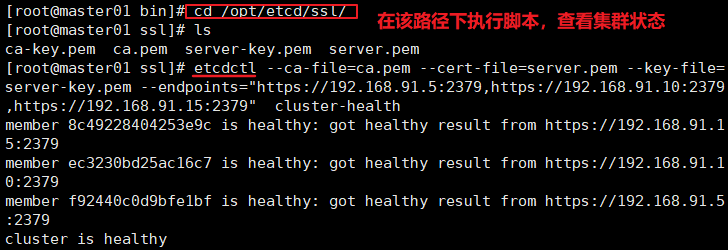
3、查看集群状态
#在master01上操作 ln -s /opt/etcd/bin/etcd* /usr/local/bin //检查etcd集群状态 cd /opt/etcd/ssl /opt/etcd/bin/etcdctl \ --ca-file=ca.pem \ --cert-file=server.pem \ --key-file=server-key.pem \ --endpoints="https://192.168.91.5:2379,https://192.168.91.10:2379,https://192.168.91.15:2379" \ cluster-health ----------------------------------------------- --ca-file:使用此CA证书验证启用HTTPS的服务器的证书 --cert-file:识别HTTPS端使用SSL证书文件 --key-file:使用此SSL秘钥文件标识HTTPS客户端 --endpoints:集群中以逗号分隔的机器地址列别 cluster-health:检查etcd集群运行状况 ------------------------------------------------- //切换到etcd3版本查看集群节点状态和成员列别 export ETCDCTL_API=3 #v2和v3略有不同,etcd2和etcd3也不兼容,默认是v2版本 etcdctl --write-out=table endpoint status etcdctl --write-out=table member list export ETCDCTL_API=3 #再切回v2版本
4、部署docker引擎
======所有node节点部署docker引擎====== yum install -y yum-utils device-mapper-persistent-data 1vm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/1inux/centos/docker-ce.repo yum install -y docker-ce dqsker-ce-cli containerd.io systenctl start docker.service systemct1 enable docker.service
三、flannel网络配置
===========flannel网络配置============= ===K8S中Pod网络通信: === ●Pod内容器与容器之间的通信 在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在网一台机器上一样,可以用 localhost地址访间彼此的端口 ●同一个Node内Pod之间的通信 每个Pod 都有一个真实的全局IP地址,同一个Node 内的不同Pod之间可以直接采用对方Pod的IP 地址进行通信,Pod1 与 Pod2都是通过veth连接到同一个docker0 网桥,网段相同,所以它们之间可以直接通信 ●不同Node上Pod之间的通信 Pod地址与docker0 在同一网段,dockor0 网段与宿主机网卡是两个不同的网段,且不同Nodo之间的通信贝能通过宿主机的物理网卡进行 要想实现不同Node 上Pod之间的通信,就必须想办法通过主机的物理网卡IP地址进行寻址和通信。 因此要满足两个条件: Pod 的IP不能冲突: 将Pod的IP和所在的Node的IP关联起来,通过这个关联让不同Node上Pod之间直接通过内网IP地址通信。 ===Overlay Network:=== 叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN) ===VXLAN:=== 将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址 ===Flannel:=== Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址 Flannel是Overlay 网络的一种,也是将TCP 源数据包封装在另一种网络 包里而进行路由转发和通信,目前己经支持UDP、VXLAN、AwS VPC等数据转发方式 ===ETCD之Flannel 提供说明:=== 存储管理Flanne1可分配的IP地址段资源 监控ETCD中每个Pod 的实际地址,并在内存中建立维护Pod 节点路由表
Flannel工作原理:
node1上的pod1 要和node2上的pod1进行通信
1.数据从node1上的Pod1源容器中发出,经由所在主机的docker0 虚拟网卡转发到flannel0虚拟网卡;
2.再由flanneld把pod ip封装到udp中(里面封装的是源pod IP和目的pod IP);
3.根据在etcd保存的路由表信息,通过物理网卡发送给目的node2的flanneld,来进行解封装暴露出udp里的pod IP;
4.最后根据目的pod IP经flannel0虚拟网卡和docker0虚拟网卡转发到目的pod中,最后完成通信
在master1 节点 添加flannel 网络配置信息
======在master1 节点上操作======
//添加flannel 网络配置信息,写入分配的子网段到etcd 中,供flannel使用
cd /opt/etcd/ss1
/opt/etcd/bin/etcdctl \
--ca-file=ca.pem \
--cert-file=server.pem \
--key-file=server-key.pem \
--endpoints="https://192.168.91.5:2379,https://192.168.91.10:2379,https://192.168.91.15:2379" \
set /coreos.com/network/config '{"Network": "172.17.0.0/16","Backend": {"Type": "vxlan"}}'
//查看写入的信息 /opt/etcd/bin/etcdctl \ --ca-file=ca.pem \ --cert-file-server.pem \ --key-file=server-key.pem \ --endpoints="https://192.168.91.5:2379,https://192.168.91.10:2379,https://192.168.91.15:2379" \ get /coreos.com/network/config --------------------------------------------------------- set /coreos.com/network/confiq添加一条网络配置记求,这个配置将用于flannel分配给每个docker的虛拟IP地址段 get <ckey> got /coreos.com/octwork/config获取网络配置记录,后面不用再跟参数了 Network:用于指定Flane1地址池 Backend:用于指定数据包以什么方式转发,默认为udp模式,Backend为vxlan比起预设的udp性能相对好一些

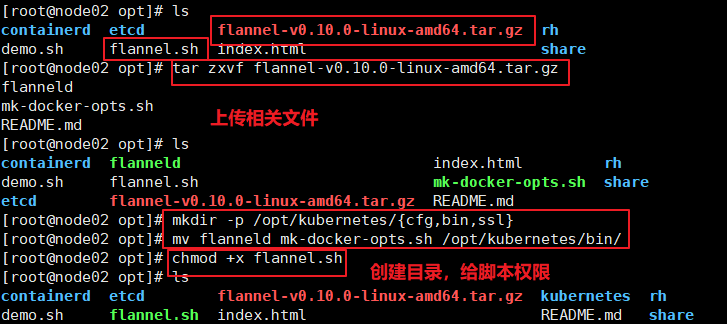
在所有node节点上操作
//上传flannel.sh 和flanne1-v0.10.0-1inux-amd64.tar.gz 到/opt 目录中,解压flannel 压缩包
cd /opt
tar zxvf flannel-v0.10.0-1inux-amd64.tar.gz
flanneld
#flanneld为主要的执行文件
mk-docker-opts.sh
#mk-docker-opts . sh脚本用于生成Docker启动参数
README.md
//创建kubernetes工作目录
mkdir -p /opt/kubernetes/{cfg,bin,ss1}
cd /opt
mv mk-docker-opts.sh flanneld /opt/kubernetes/bin/
//启动flanneld服务,开启flanne1网络功能
cd /opt
chmod +x flannel.sh
./flannel.sh https://192.168.80.10:2379,https://192.168.80.11:2379,https://192.168.80.12:2379
systemctl status flanneld
//flanne1启动后会生成一个docker网络相关信息配置文件/run/flannel/subnet.env,包含了docker要使用flannel通讯的相关参数
cat /run/flannel/subnet.env
DOCKER_OPT_BIP="--bip=172.17.26.1/24"
DOCKER_OPT_IPMASQ="--ip-masq= false"
DOCKER_OPT_MTU="--mtu=1450"
DOCKER_NETWORK_OPTIONS=" --bip=172.17.26.1/24 --ip-masq=false --mtu=1450"
------------------------------------------------
--bi: 指定docker 启动时的子网
--ip-masq: 设置ipmasq=false 关闭snat 伪装策略
--mtu=1450:mtu要留出50字节给外层的vxlan封包的额外开销使用
Flannel启动过程解析:
1、从etcd中获取network的配置信息
2、划分subnet, 并在etcd中进行注册
3、将子网信息记录到/run/flannel/subnet.env中
------------------------------------------------
//修改docker服务管理文件,配置docker连接flannel
vim /lib/systemd/system/docker.service
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues stillt
# exists and systemd currently dges not support the cgroup feature set requi red
# for containers run by docker
EnvironmentFile=/run/flannel/subnet.env
#添加
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS -H fd:// --containerd=/run/containerd/containerd.sock
#修改
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
//重启docker服务
systemctl daemon-reload
systemctl restart docker
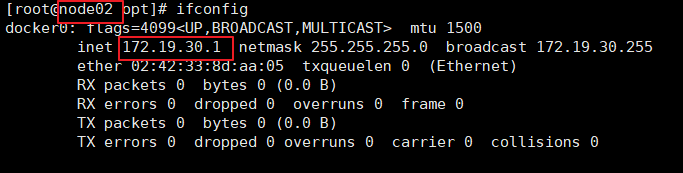
ifconfig #查看flannel网络
测试ping通对方docker0网卡 证明flannel起到路由作用
ping 172.17.38.1
docker run -it centos:7 /bin/bash #node1和node2都运行该命令
yum install net-tools -y #node1和node2都运行该命令
ifconfig //再次测试ping通两个node中的centos:7容器


四、部署master组件
======在master1 节点上操作======
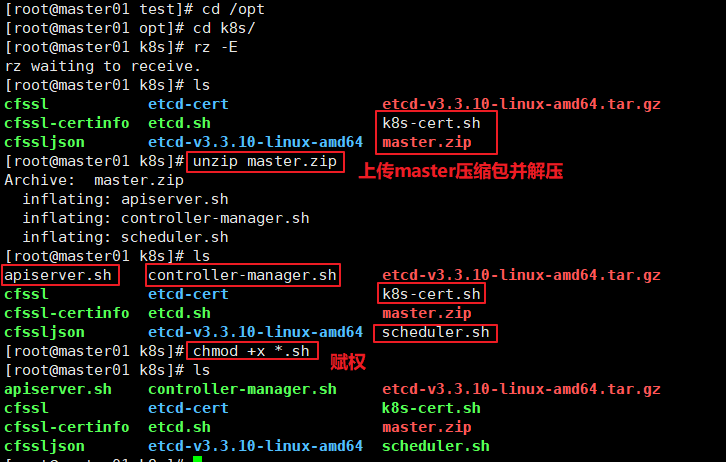
//上传master.zip 和k8s-cert.sh 到/opt/k8s 目录中,解压master.zip 压缩包
cd /opt/k8s/
unzip master.zip
apiserver.sh
scheduler.sh
controller-manager.sh
chmod +x * .sh
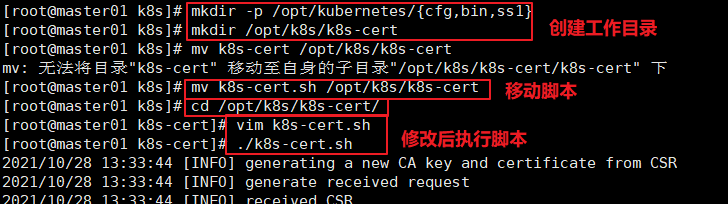
//创建kubernetes工作目录
mkdir -p /opt/kubernetes/{cfg,bin,ss1}
//创建用于生成CA证书、相关组件的证书和私钥的目录
mkdir /opt/k8s/k8s-cert
mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
cd /opt/k8s/k8s-cert/
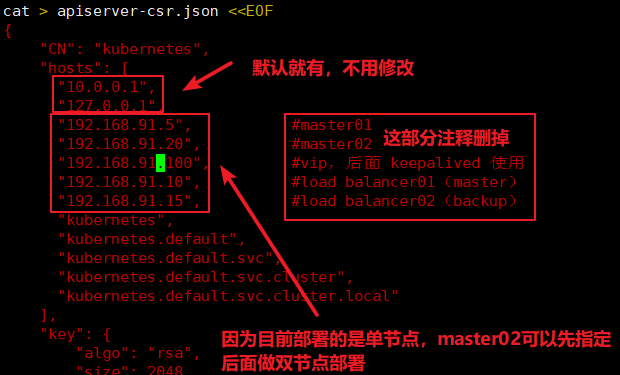
./k8s-cert.sh
#生成CA证书、相关组件的证书和私钥
//controller-manager和kube-scheduler设置为只调用当前机器的apiserver, 使用127.0.0.1:8080 通信,因此不需要签发证书
//复制CA证书、apiserver 相关证书和私钥到kubernetes. 工作目录的ssl子目录中
cp ca*pem apiserver*pem /opt/kubernetes/ssl/
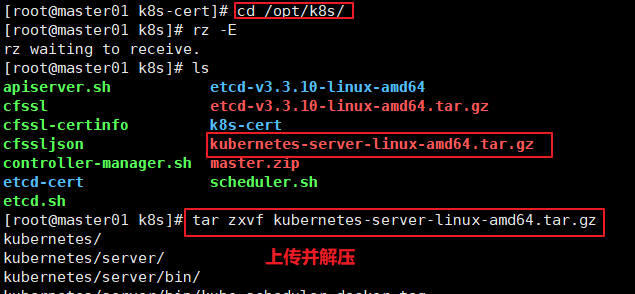
//上传kubernetes-server-linux-amd64.tar.gz 到/opt/k8s/ 目录中,解压kubernetes 压缩包
cd /opt/k8s/
tar zxvf kubernetes-server-linux-amd64.tar.gz
//复制master组件的关键命令文件到kubernetes. 工作目录的bin子目录中
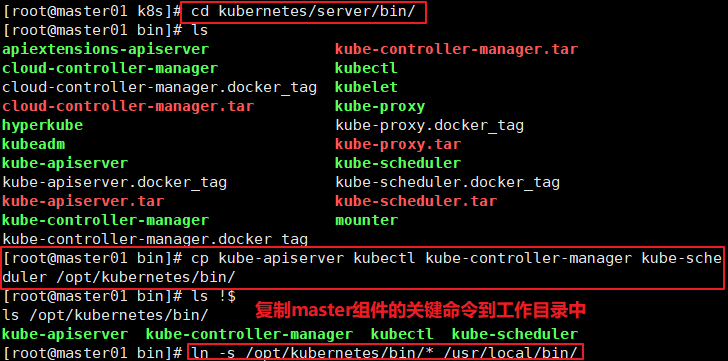
cd /opt/k8s/kubernetes/server/bin
cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
1n -s /opt/kubernetes/bin/* /usr/local/bin/
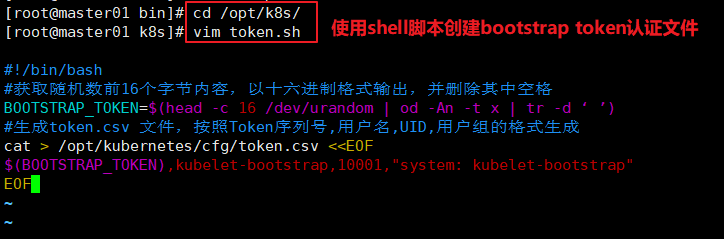
//创建bootstrap token 认证文件,apiserver 启动时会调用,然后就相当于在集群内创建了一个这个用户,接下来就可以用RBAC
给他授权
cd /opt/k8s/
vim token.sh
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ‘ ’)
#生成token.csv 文件,按照Token序列号,用户名,UID,用户组的格式生成
cat > /opt/kubernetes/cfg/token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOF
chmod +x token.sh
./token.sh
./apiserver.sh 192.168.91.5 https://192.168.91.5:2379,https://192.168.91.10:2379,https://192.168.91.15:2379
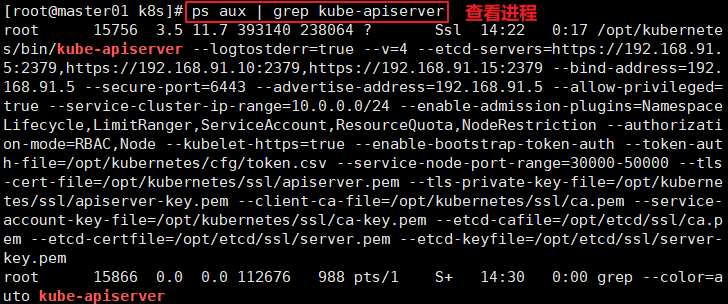
#检查进程是否启动成功
ps aux | grep kube
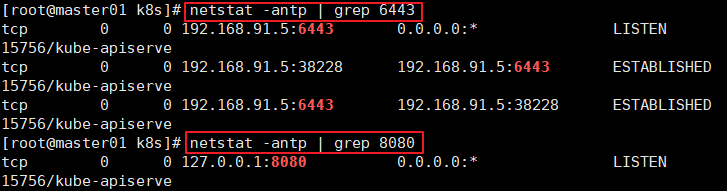
//k8s通过kube-apiserver这个进程提供服务,该进程运行在单个master节点上。默认有两个端口6443和8080
//安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证
netstat -natp | grep 6443
//本地端口8080用于接收HTTP请求,非认证或授权的HTTP请求通过该端口访问APIServer
netstat -natp | grep 8080
//查看版本信息(必须保证apiserver启动正常,不然无法查询到server的版本信息)
kubectl version
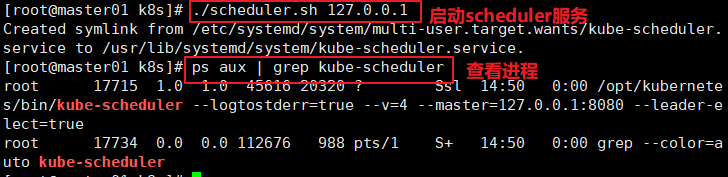
//启动scheduler 服务
cd /opt/k8s/
./scheduler.sh 127.0.0.1
ps aux | grep kube-scheduler
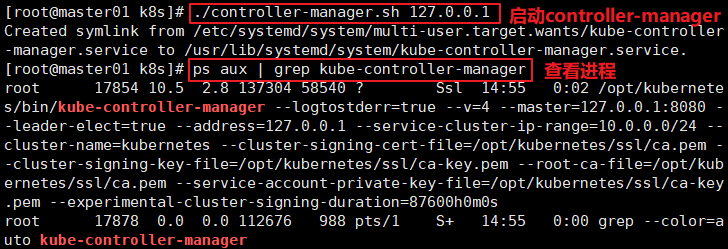
//启动controller-manager服务
cd /opt/k8s/
./controller-manager.sh 127.0.0.1
//查看master节点状态
kubectl get cs




五、部署node组件
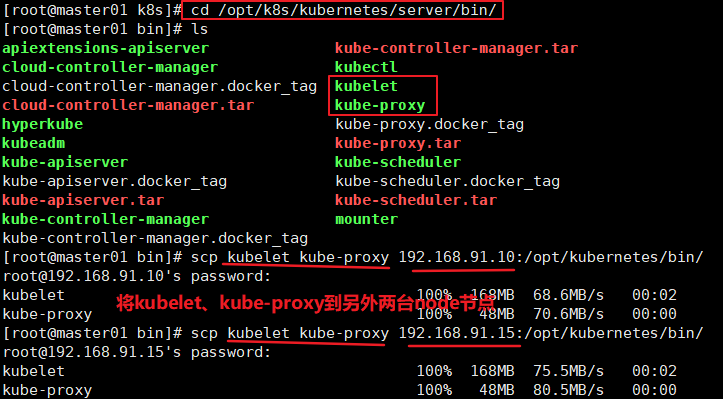
部署node组件 ======在master1 节点上操作====== //把kubelet、 kube-proxy拷贝到node 节点 cd /opt/k8s/kubernetes/server/bin scp kubelet kube-proxy root0192.168.80.11:/opt/kubernetes/bin/ scp kubelet kube-proxy root@192.168.80.12:/opt/kubernetes/bin/
======在node1 节点上操作====== //上传node.zip 到/opt 目录中,解压node.zip 压缩包,获得kubelet.sh、 proxy.sh cd /opt/ unzip node.zip

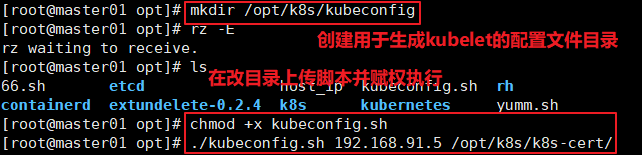
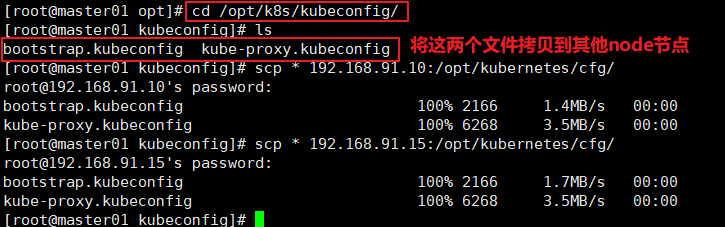
======在master1节点上操作======= //创建用于生成kubelet的配置文件的目录 mkdir /opt/k8s/kubeconfig //上传kubeconfig.sh 文件到/opt/k8s/kubeconfig 目录中 #kubeconfig.sh文件包含集群参数(CA 证书、API Server 地址),客户端参数(上面生成的证书和私钥),集群context 上下文参数(集群名称、用户名)。Kubenetes 组件(如kubelet、 kube-proxy) 通过启动时指定不同的kubeconfig文件可以切换到不同的集群,连接到apiserver cd /opt/k8s/kubeconfig chmod +x kubeconfig.sh //生成kubelet的配置文件 cd /opt/k8a/kubeconfig ./kubecontig.sh 192.168.80.10 /opt/k8s/k8s-cert/ 1s bootstrap.kubeconfig kubeconfig.sh kube-proxy.kubeconfig //把配置文件bootstrap.kubeconfig、kube-proxy.kubeconfig拷贝到node节点 cd /opt/k8s/kubeconfig scp bootstrap.kubeconfig kube-proxy-kubeconfig root0192.168.80.11:/opt/kubernetes/cfg/ scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.80.12:/opt/kubernetes/cfg/ //RBAC授权,将预设用户kubelet-bootatrap 与内置的ClusterRole system:node-bootatrapper 绑定到一起,使其能够发起CSR请求 kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap --------------------------------------- kubelet采用TLS Bootstrapping 机制,自 动完成到kube -apiserver的注册,在node节点量较大或者后期自动扩容时非常有用。 Master apiserver 启用TLS 认证后,node 节点kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与apiserver 通信,当node节点很多时,签署证书是一件很繁琐的事情。因此Kubernetes 引入了TLS bootstraping 机制来自动颁发客户端证书,kubelet会以一个低权限
用户自动向apiserver 申请证书,kubelet 的证书由apiserver 动态签署。 kubelet首次启动通过加载bootstrap.kubeconfig中的用户Token 和apiserver CA证书发起首次CSR请求,这个Token被预先内置在apiserver 节点的token.csv 中,其身份为kubelet-bootstrap 用户和system: kubelet- bootstrap用户组:想要首次CSR请求能成功(即不会
被apiserver 401拒绝),则需要先创建一个ClusterRoleBinding, 将kubelet-bootstrap 用户和system:node - bootstrapper内置ClusterRole 绑定(通过kubectl get clusterroles 可查询),使其能够发起CSR认证请求。 TLS bootstrapping 时的证书实际是由kube-controller-manager组件来签署的,也就是说证书有效期是kube-controller-manager组件控制的; kube-controller-manager 组件提供了一个--experimental-cluster-signing-duration 参数来设置签署的证书有效时间:默认为8760h0m0s, 将其改为87600h0m0s, 即10年后再进行TLS bootstrapping 签署证书即可。 也就是说kubelet 首次访问API Server 时,是使用token 做认证,通过后,Controller Manager 会为kubelet生成一个证书,以后的访问都是用证书做认证了。 ------------------------------------------ //查看角色: kubectl get clusterroles | grep system:node-bootstrapper //查看已授权的角色: kubectl get clusterrolebinding

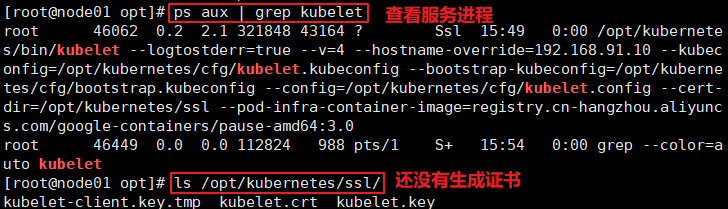
======在node1节点上操作====== //使用kubelet.sh脚本启动kubelet服务 cd /opt/ chmod +x kubelet.sh ./kubelet.sh 192.168.80.11 //检查kubelet服务启动 ps aux | grep kubelet //此时还没有生成证书 ls /opt/kubernetes/ssl/

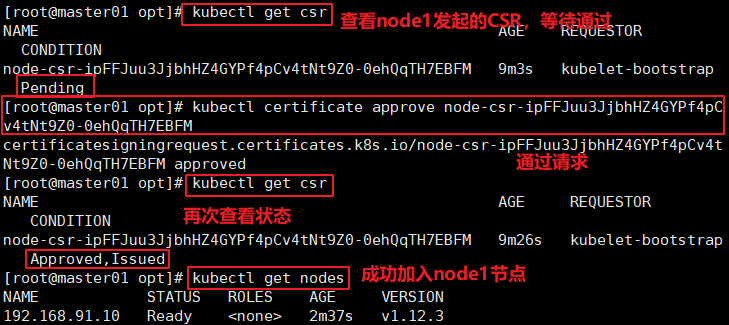
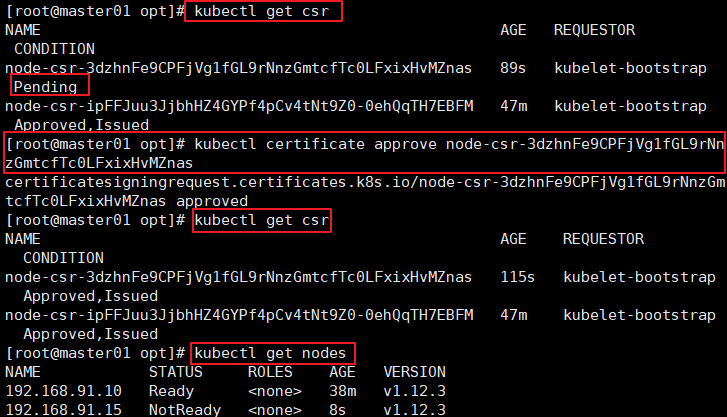
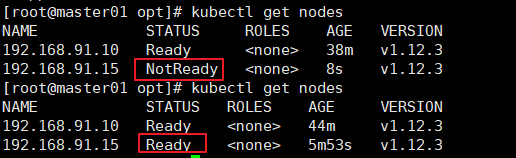
======在master1 节点上操作====== //检查到node1 节点的kubelet 发起的CSR请求,Pending 表示等待集群给该节点签发证书. kubectl get csr //通过CSR请求 kubectl certificate approve node-csr-NOI-9vufTLIqJgMWq4fHPNPHKbjCX1DGHptj7FqTa8A //再次查看CSR请求状态,Approved, Issued表示已授权CSR请求并签发证书 kubectl get csr //查看群集节点状态,成功加入node1节点 kubectl get nodes
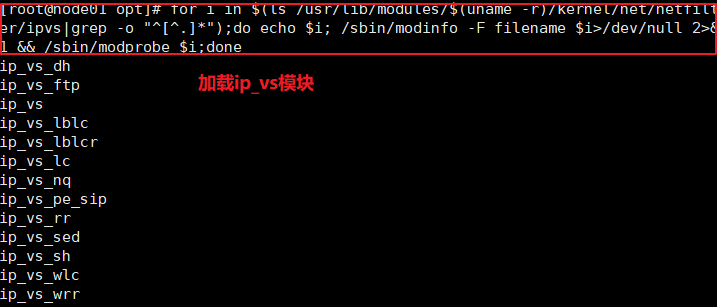
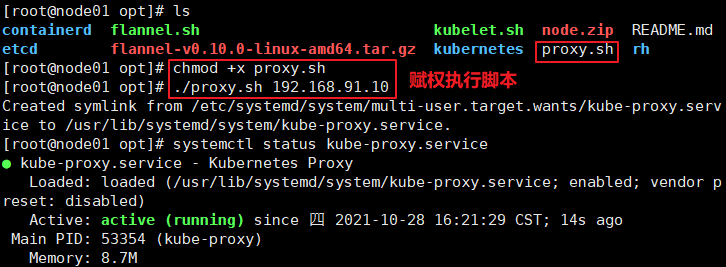
======在node1节点上操作====== //自动生成了证书和kubelet.kubeconfig 文件 ls /opt/kubernetes/cfg/kubelet.kubeconfig ls /opt/kubernetes/ssl/ //加载ip_vs模块 for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done //使用proxy.sh脚本启动proxy服务 cd /opt/ chmod +x proxy.sh ./proxy.sh 192.168.80.11 systemctl status kube-proxy.service


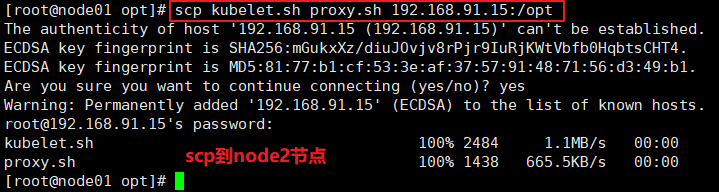
======node2 节点部署====== ##方法一 : //在node1 节点上将kubelet.sh、 proxy.sh 文件拷贝到node2 节点 cd /opt/ scp kubelet.sh proxy.sh root@192.168.80.12:/opt/ //使用kubelet.sh脚本启动kubelet服务 cd /opt/ chmod +x kubelet.sh ./kubelet.sh 192.168.80.11 //在master1 节点上操作,检查到node2 节点的kubelet 发起的CSR请求,Pending 表示等待集群给该节点签发证书. kubectl get csr //通过CSR请求 kubect1 certificate approve node-csr-NOI-9vufTLIqJgMWq4fHPNPHKbjCX1DGHptj7FqTa8A //再次查看CSR请求状态,Approved, Issued表示已授权CSR请求并签发证书 kubectl get csr //查看群集节点状态,成功加入node1节点 kubectl get nodes //在node2 节点 加载ip_vs模块 for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done //使用proxy.sh脚本启动proxy服务 cd /opt/ chmod +x proxy.sh ./proxy.sh 192.168.80.11 systemctl status kube-proxy.service



 浙公网安备 33010602011771号
浙公网安备 33010602011771号