

一个操作就可以看看你平时上网都在干嘛?
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文章来自腾讯云 作者:Python进阶者
想要学习Python?有问题得不到第一时间解决?来看看这里“1039649593”满足你的需求,资料都已经上传至文件中,可以自行下载!还有海量最新2020python学习资料。
点击查看
简介
想看看你最近一年都在干嘛?看看你平时上网是在摸鱼还是认真工作?想写年度汇报总结,但是苦于没有数据?现在,它来了。
这是一个能让你了解自己的浏览历史的Chrome浏览历史记录分析程序,当然了,他仅适用于Chrome浏览器或者以Chrome为内核的浏览器。
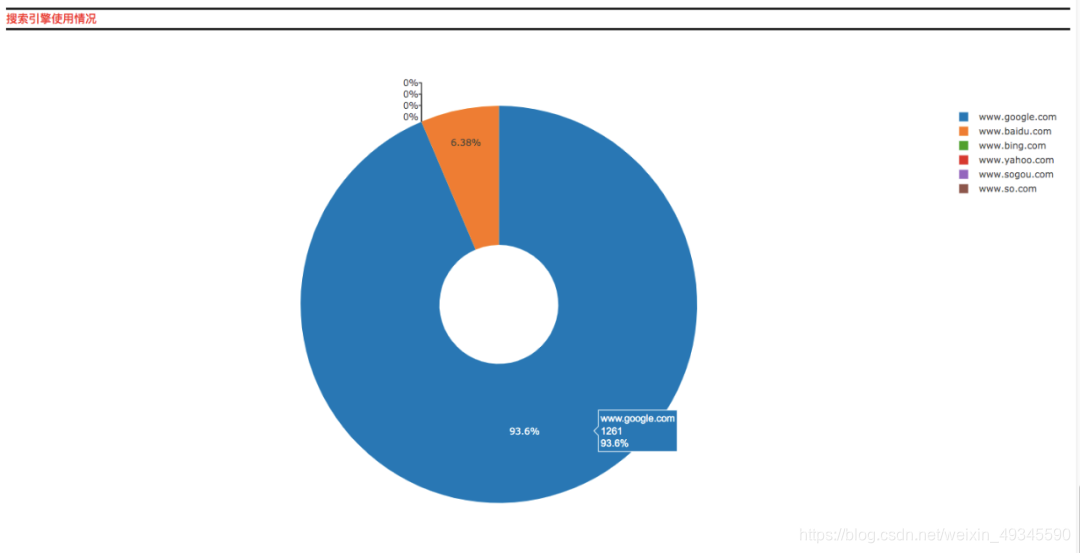
在该页面中你将可以查看有关自己在过去的时间里所访问浏览的域名、URL以及忙碌天数的前十排名以及相关的数据图表。
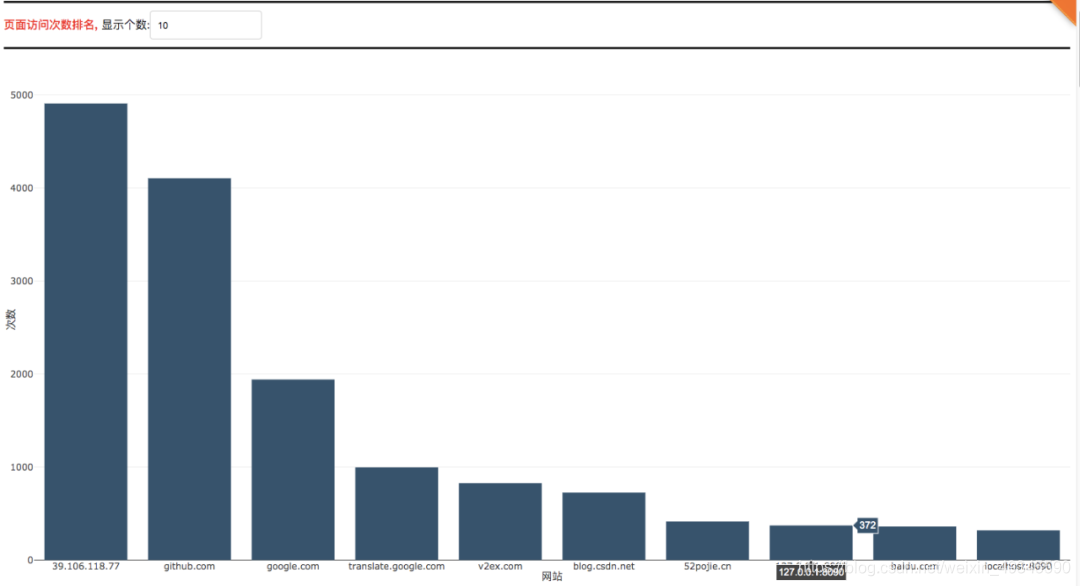

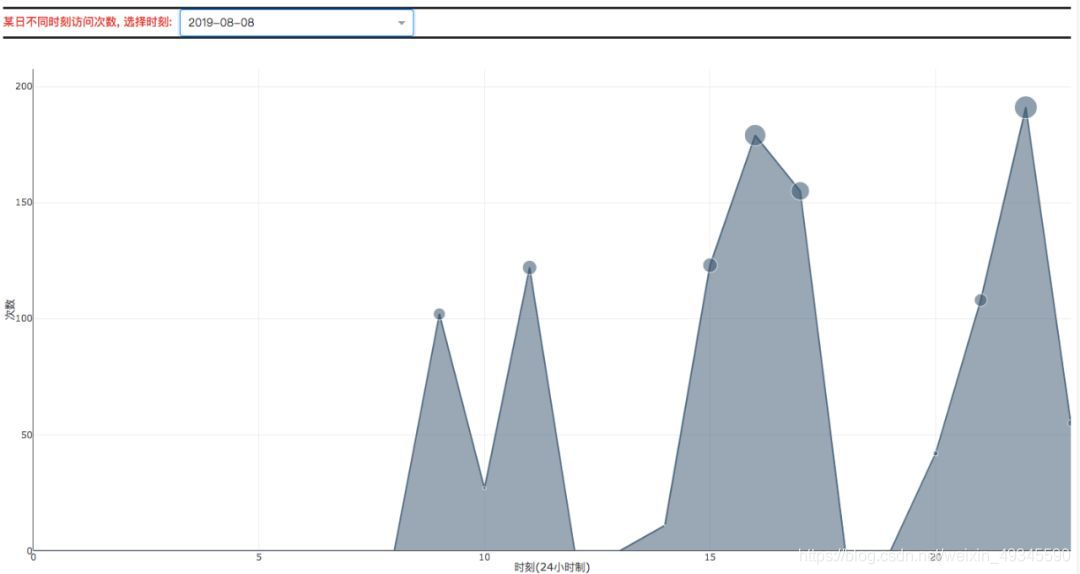

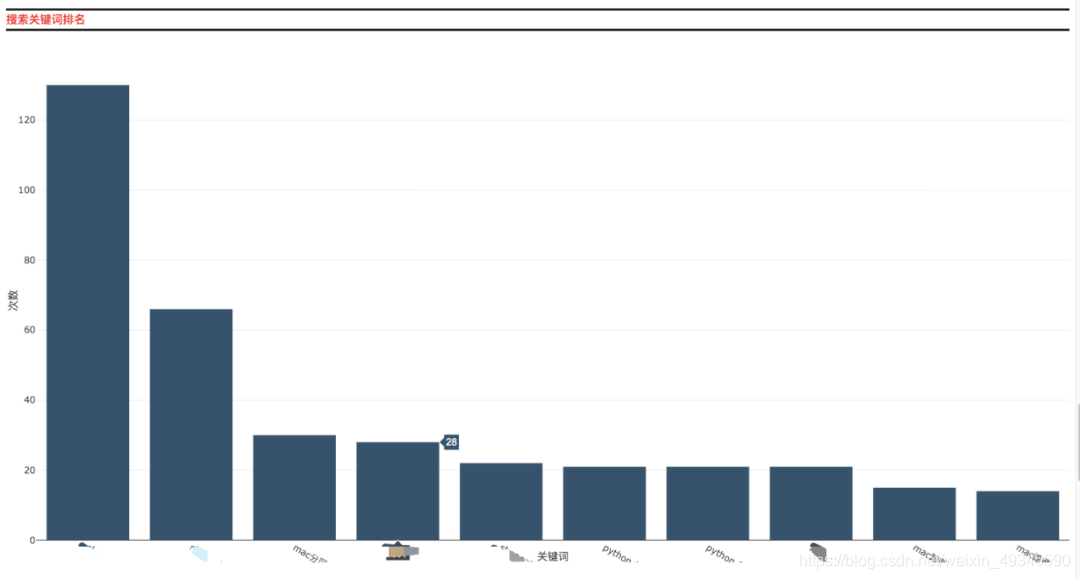

代码思路
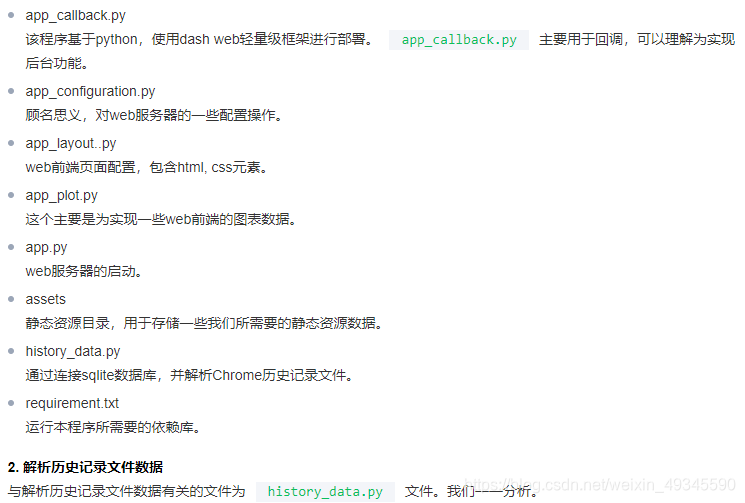
- 目录结构
首先,我们先看一下整体目录结构
Code ├─ app_callback.py 回调函数,实现后台功能 ├─ app_configuration.py web服务器配置 ├─ app_layout.py web前端页面配置 ├─ app_plot.py web图表绘制 ├─ app.py web服务器的启动 ├─ assets web所需的一些静态资源文件 │ ├─ css web前端元素布局文件 │ │ ├─ custum-styles_phyloapp.css │ │ └─ stylesheet.css │ ├─ image web前端logo图标 │ │ ├─ GitHub-Mark-Light.png │ └─ static web前端帮助页面 │ │ ├─ help.html │ │ └─ help.md ├─ history_data.py 解析chrome历史记录文件 └─ requirement.txt 程序所需依赖库
# 查询数据库内容 def query_sqlite_db(history_db, query): # 查询sqlite数据库 # 注意,History是一个文件,没有后缀名。它不是一个目录。 conn = sqlite3.connect(history_db) cursor = conn.cursor() # 使用sqlite查看软件,可清晰看到表visits的字段url=表urls的字段id # 连接表urls和visits,并获取指定数据 select_statement = query # 执行数据库查询语句 cursor.execute(select_statement) # 获取数据,数据格式为元组(tuple) results = cursor.fetchall() # 关闭 cursor.close() conn.close() return results
该函数的代码流程为:
连接sqlite数据库,执行查询语句,返回查询结构,最终关闭数据库连接。
# 获取排序后的历史数据 def get_history_data(history_file_path): try: # 获取数据库内容 # 数据格式为元组(tuple) select_statement = "SELECT urls.id, urls.url, urls.title, urls.last_visit_time, urls.visit_count, visits.visit_time, visits.from_visit, visits.transition, visits.visit_duration FROM urls, visits WHERE urls.id = visits.url;" result = query_sqlite_db(history_file_path, select_statement) # 将结果按第1个元素进行排序 # sort和sorted内建函数会优先排序第1个元素,然后再排序第2个元素,依此类推 result_sort = sorted(result, key=lambda x: (x[0], x[1], x[2], x[3], x[4], x[5], x[6], x[7], x[8])) # 返回排序后的数据 return result_sort except: # print('读取出错!') return 'error'

# 页面访问次数排名 html.Div( style={'margin-bottom':'150px'}, children=[ html.Div( style={'border-top-style':'solid','border-bottom-style':'solid'}, className='row', children=[ html.Span( children='页面访问次数排名, ', style={'font-weight': 'bold', 'color':'red'} ), html.Span( children='显示个数:', ), dcc.Input( id='input_website_count_rank', type='text', value=10, style={'margin-top':'10px', 'margin-bottom':'10px'} ), ] ), html.Div( style={'position': 'relative', 'margin': '0 auto', 'width': '100%', 'padding-bottom': '50%', }, children=[ dcc.Loading( children=[ dcc.Graph( id='graph_website_count_rank', style={'position': 'absolute', 'width': '100%', 'height': '100%', 'top': '0', 'left': '0', 'bottom': '0', 'right': '0'}, config={'displayModeBar': False}, ), ], type='dot', style={'position': 'absolute', 'top': '50%', 'left': '50%', 'transform': 'translate(-50%,-50%)'} ), ], ) ] )

# 绘制 页面访问频率排名 柱状图 def plot_bar_website_count_rank(value, history_data): # 频率字典 dict_data = {} # 对历史记录文件进行遍历 for data in history_data: url = data[1] # 简化url key = url_simplification(url) if (key in dict_data.keys()): dict_data[key] += 1 else: dict_data[key] = 0 # 筛选出前k个频率最高的数据 k = convert_to_number(value) top_10_dict = get_top_k_from_dict(dict_data, k) figure = go.Figure( data=[ go.Bar( x=[i for i in top_10_dict.keys()], y=[i for i in top_10_dict.values()], name='bar', marker=go.bar.Marker( color='rgb(55, 83, 109)' ) ) ], layout=go.Layout( showlegend=False, margin=go.layout.Margin(l=40, r=0, t=40, b=30), paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', xaxis=dict(title='网站'), yaxis=dict(title='次数') ) ) return figure

# 页面访问频率排名 @app.callback( dash.dependencies.Output('graph_website_count_rank', 'figure'), [ dash.dependencies.Input('input_website_count_rank', 'value'), dash.dependencies.Input('store_memory_history_data', 'data') ] ) def update(value, store_memory_history_data): # 正确获取到历史记录文件 if store_memory_history_data: history_data = store_memory_history_data['history_data'] figure = plot_bar_website_count_rank(value, history_data) return figure else: # 取消更新页面数据 raise dash.exceptions.PreventUpdate("cancel the callback")

# 上传文件回调 @app.callback( dash.dependencies.Output('store_memory_history_data', 'data'), [ dash.dependencies.Input('dcc_upload_file', 'contents') ] ) def update(contents): if contents is not None: # 接收base64编码的数据 content_type, content_string = contents.split(',') # 将客户端上传的文件进行base64解码 decoded = base64.b64decode(content_string) # 为客户端上传的文件添加后缀,防止文件重复覆盖 # 以下方式确保文件名不重复 suffix = [str(random.randint(0,100)) for i in range(10)] suffix = "".join(suffix) suffix = suffix + str(int(time.time())) # 最终的文件名 file_name = 'History_' + suffix # print(file_name) # 创建存放文件的目录 if (not (exists('data'))): makedirs('data') # 欲写入的文件路径 path = 'data' + '/' + file_name # 写入本地磁盘文件 with open(file=path, mode='wb+') as f: f.write(decoded) # 使用sqlite读取本地磁盘文件 # 获取历史记录数据 history_data = get_history_data(path) # 获取搜索关键词数据 search_word = get_search_word(path) # 判断读取到的数据是否正确 if (history_data != 'error'): # 找到 date_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('新接收到一条客户端的数据, 数据正确, 时间:{}'.format(date_time)) store_data = {'history_data': history_data, 'search_word': search_word} return store_data else: # 没找到 date_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('新接收到一条客户端的数据, 数据错误, 时间:{}'.format(date_time)) return None return None
该函数的代码流程为:
首先判断用户上传的数据contents是否不为空,接着将客户端上传的文件进行base64解码。并且,为客户端上传的文件添加后缀,防止文件重复覆盖,最终将客户端上传的文件写入本地磁盘文件。
写入完毕后,使用sqlite读取本地磁盘文件,若读取正确,则返回解析后的数据,否则返回None
接下来,就是我们数据提取最核心的部分了,即从Chrome历史记录文件中提取出我们想要的数据。由于Chrome历史记录文件是一个sqlite数据库,所以我们需要使用数据库语法提取出我们想要的内容。
# 获取排序后的历史数据 def get_history_data(history_file_path): try: # 获取数据库内容 # 数据格式为元组(tuple) select_statement = "SELECT urls.id, urls.url, urls.title, urls.last_visit_time, urls.visit_count, visits.visit_time, visits.from_visit, visits.transition, visits.visit_duration FROM urls, visits WHERE urls.id = visits.url;" result = query_sqlite_db(history_file_path, select_statement) # 将结果按第1个元素进行排序 # sort和sorted内建函数会优先排序第1个元素,然后再排序第2个元素,依此类推 result_sort = sorted(result, key=lambda x: (x[0], x[1], x[2], x[3], x[4], x[5], x[6], x[7], x[8])) # 返回排序后的数据 return result_sort except: # print('读取出错!') return 'error'




# 跳转到当前目录 cd 目录名 # 先卸载依赖库 pip uninstall -y -r requirement.txt # 再重新安装依赖库 pip install -r requirement.txt # 开始运行 python app.py # 运行成功后,通过浏览器打开http://localhost:8090

 浙公网安备 33010602011771号
浙公网安备 33010602011771号