

Python爬虫:爬取网络表情包,助你成为斗帝。
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文章来自腾讯云 作者:Python进阶者
想要学习Python?有问题得不到第一时间解决?来看看这里“1039649593”满足你的需求,资料都已经上传至文件中,可以自行下载!还有海量最新2020python学习资料。
点击查看
你是否在寻找可以与高手斗图的应用? 你是否在寻找可以自制表情的应用?你是否在寻找最全、最爆笑的表情库?
斗图网是一个收集了成千上万的撕逼斗图表情包,在这里你可以快速找到想要的表情, 更好的“斗图”,助您成为真正的斗图终结者!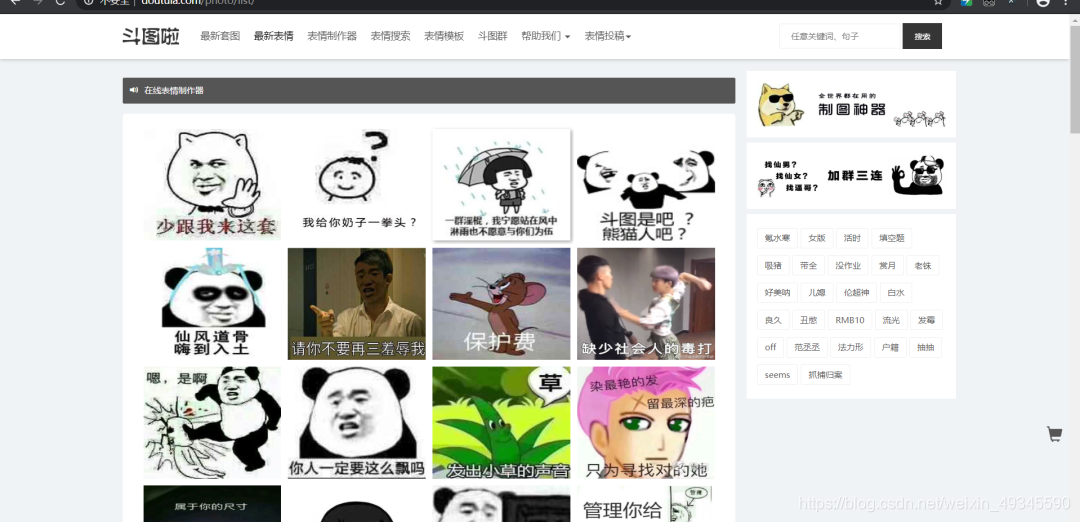
下载表情包,保存文档。
1、网址如下:
https://www.doutula.com/photo/list/?page={}
2、涉及的库:requests****、lxml、ssl****、time
3、软件:PyCharm
1、如何找到表情包图片地址?
F12右键检查,找到对应的图片的地址。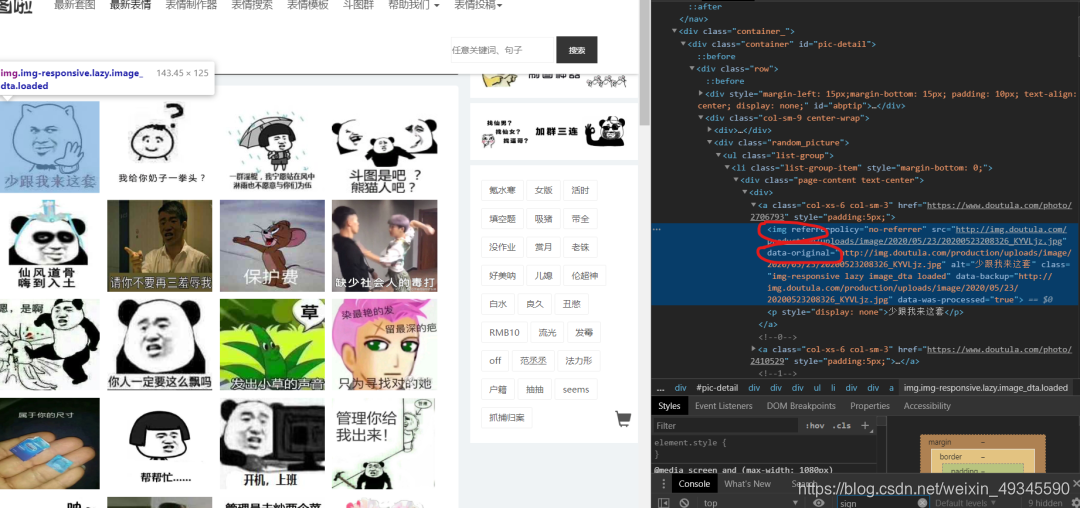
https://www.doutula.com/photo/list/?page=1 https://www.doutula.com/photo/list/?page=2 https://www.doutula.com/photo/list/?page=3
发现点击下一页时,page{}每增加一页自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
2.如何解除ssl验证?
因为这个网址是https,需要导入一个ssl模块,忽略ssl验证。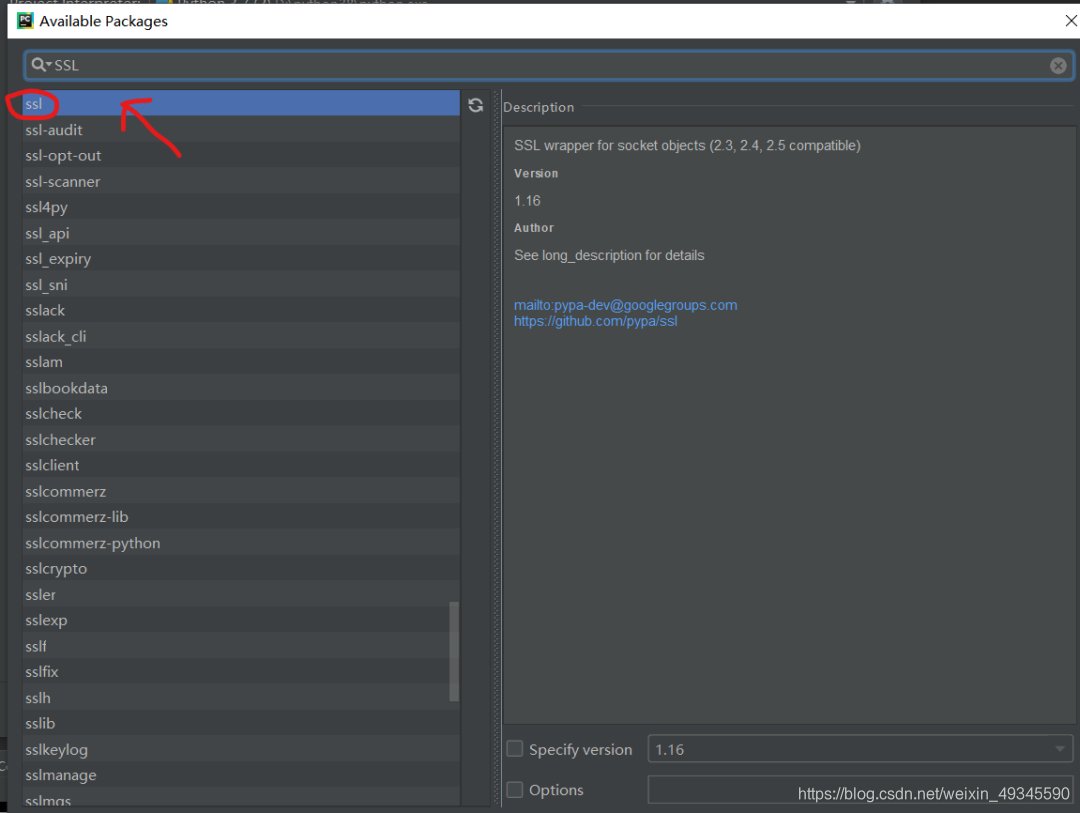
3. ****如何获取Cookie?
右键检查,找到NetWork,随便复制一个Cookie即可。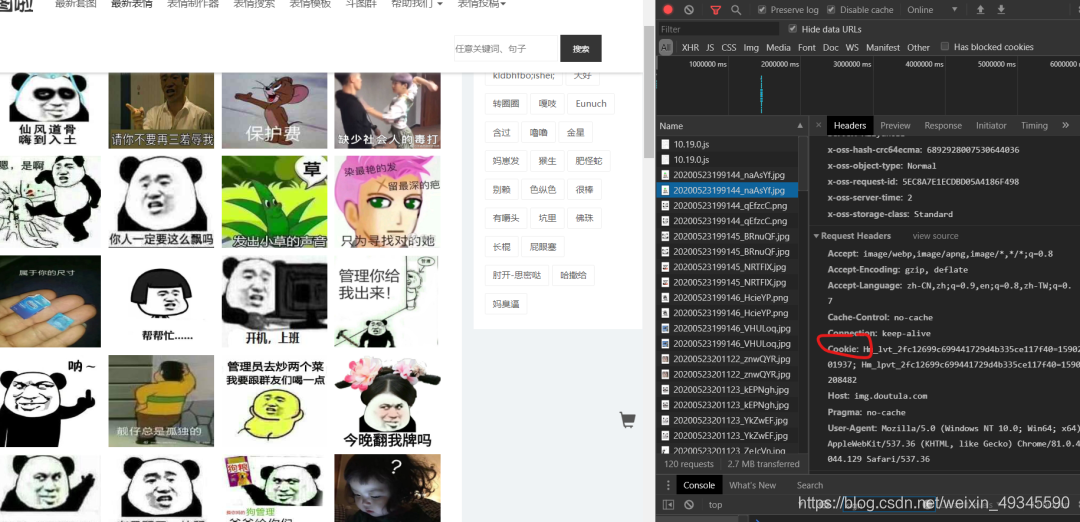
1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。导入需要的库。
import requests from lxml import etree from fake_useragent import UserAgent import ssl # ssl验证import time ssl._create_default_https_context = ssl._create_unverified_contextclass Emoticon(object): def __init__(self): pass def main(self): passif __name__ == '__main__': spider = Emoticon() spider.main()
2、导入网址和构造请求头,防止反爬。
def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0'} self.url = 'https://www.doutula.com/photo/list/?page={}'
3、发送请求 ,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、xpath解析页面。
这里我们先获取父节点,在通过for循环遍历,找到对应的子节点(图片地址)。
image = parse_html.xpath('//ul[@class="list-group"]/li/div/div//a') for i in image: image_src_list = i.xpath('.//img/@data-original')[0] image_name = i.xpath('.//img//@alt')[0]
运行的结果:
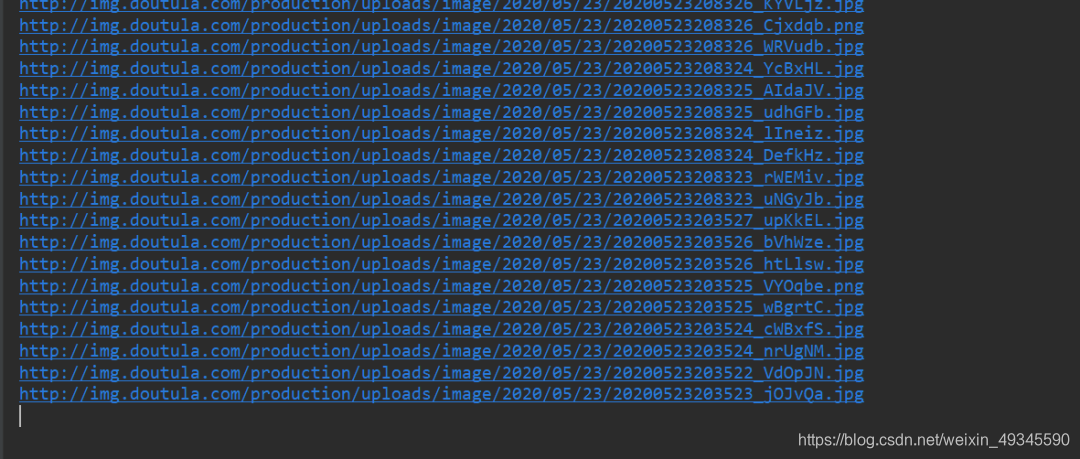
5、对图片地址发生请求,取对应图片地址后10位,作为图片的命名,写入文件(每一张图片的后缀名不一样,所有这里不采用image_name作为图片的命名)。
html2 = requests.get(url=image_src_list, headers=self.headers).content name = "/图/" + image_src_list[-20:] #print(name[-10:]) with open(name[-10:], 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % image_name) print("==================================")
6、调用方法,实现功能。
html = self.get_page(url) self.parse_page(html) print("======================第%s页爬取成功!!!!=======================" % page)
7、time模块打出执行时间。
start = time.time() end = time.time() print('执行时间:%.2f' % (end - start))
六、效果展示
1、点击绿色小三角运行输入起始页,终止页。
2、将下载成功信息显示在控制台。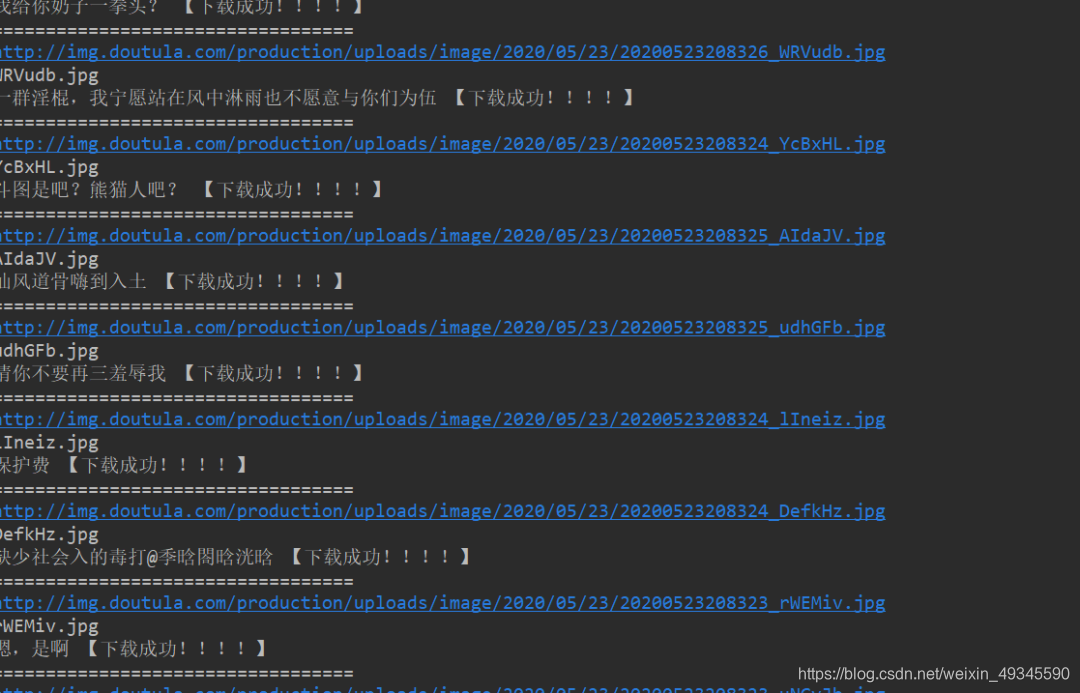
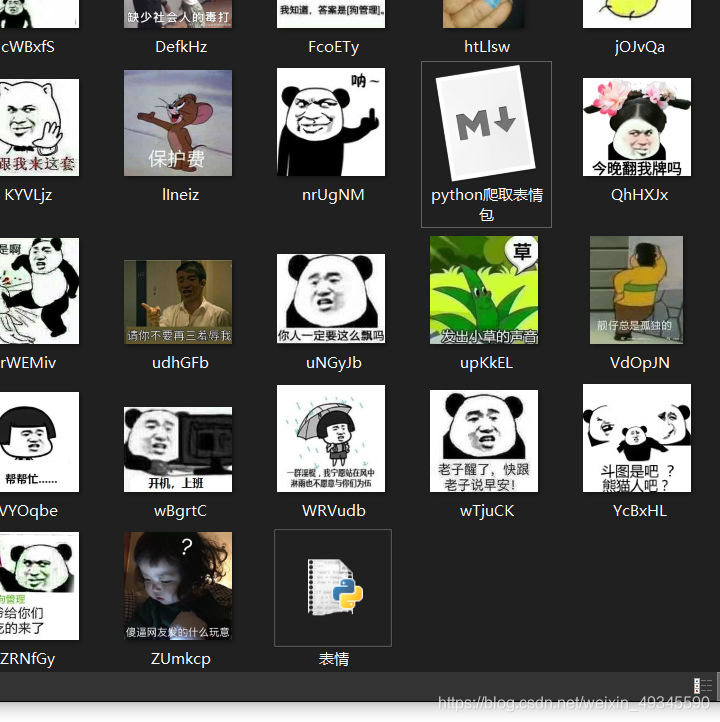
3、保存文档,在本地可以看到斗图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号